Hawk: Learning to Understand Open-World Video Anomalies

0
🧠
Sign in to get full access
Overview
- Video Anomaly Detection (VAD) systems can automatically monitor and identify disturbances, reducing the need for manual labor and associated costs.
- Current VAD systems are limited by their superficial understanding of scenes and minimal user interaction.
- Existing datasets have data scarcity, restricting the applicability of VAD systems in real-world scenarios.
Plain English Explanation
Video Anomaly Detection (VAD) systems are designed to automatically monitor and identify unusual or concerning events in video footage. This can be very useful, as it can reduce the need for constant human monitoring and the associated labor costs. However, the current VAD systems often have a limited understanding of the scenes they are monitoring and don't allow much interaction from users.
Additionally, the datasets used to train these systems tend to have a lack of diverse data, which makes it difficult for the VAD systems to work well in real-world scenarios that may be quite different from the training data.
Technical Explanation
To address these limitations, the researchers introduce a new framework called Hawk. Hawk leverages interactive large Visual Language Models (VLMs) to interpret video anomalies more precisely. Recognizing that abnormal and normal videos differ in their motion information, Hawk explicitly integrates motion modality to enhance anomaly identification.
To reinforce the model's focus on motion, Hawk uses an auxiliary consistency loss that connects the motion and video spaces, guiding the video branch to pay attention to motion data. Additionally, Hawk establishes a clear supervisory relationship between motion and its linguistic representation, improving the model's ability to understand and describe motion-related anomalies.
Furthermore, the researchers have annotated over 8,000 anomaly videos with language descriptions and created 8,000 question-answering pairs. This enables Hawk to be trained on a more diverse set of open-world scenarios, rather than being limited by the data scarcity in existing datasets.
The results demonstrate that Hawk achieves state-of-the-art performance, surpassing existing baselines in both video description generation and question-answering tasks.
Critical Analysis
While Hawk represents an impressive advancement in the field of Video Anomaly Detection, there are a few potential limitations and areas for further research:
-
The reliance on large language models may raise concerns about the interpretability and explainability of the system's decision-making process. Ensuring transparency and accountability in AI-powered systems is an important consideration.
-
The integration of motion modality is a valuable contribution, but it would be interesting to explore how other modalities, such as audio or textual context, could further enhance the system's anomaly detection capabilities.
-
The dataset creation and annotation process is a significant undertaking, and it would be helpful to understand the challenges and considerations involved in scaling this approach to even larger and more diverse datasets.
Conclusion
The Hawk framework represents an important step forward in Video Anomaly Detection by leveraging interactive large Visual Language Models and integrating motion modality. By addressing the limitations of current VAD systems and creating a more diverse dataset, Hawk demonstrates the potential to improve the precision and applicability of anomaly detection in real-world scenarios. While there are some areas for further research, the overall approach and results suggest that Hawk could have a significant impact on reducing the manual labor and costs associated with video monitoring and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Hawk: Learning to Understand Open-World Video Anomalies
Jiaqi Tang, Hao Lu, Ruizheng Wu, Xiaogang Xu, Ke Ma, Cheng Fang, Bin Guo, Jiangbo Lu, Qifeng Chen, Ying-Cong Chen
Video Anomaly Detection (VAD) systems can autonomously monitor and identify disturbances, reducing the need for manual labor and associated costs. However, current VAD systems are often limited by their superficial semantic understanding of scenes and minimal user interaction. Additionally, the prevalent data scarcity in existing datasets restricts their applicability in open-world scenarios. In this paper, we introduce Hawk, a novel framework that leverages interactive large Visual Language Models (VLM) to interpret video anomalies precisely. Recognizing the difference in motion information between abnormal and normal videos, Hawk explicitly integrates motion modality to enhance anomaly identification. To reinforce motion attention, we construct an auxiliary consistency loss within the motion and video space, guiding the video branch to focus on the motion modality. Moreover, to improve the interpretation of motion-to-language, we establish a clear supervisory relationship between motion and its linguistic representation. Furthermore, we have annotated over 8,000 anomaly videos with language descriptions, enabling effective training across diverse open-world scenarios, and also created 8,000 question-answering pairs for users' open-world questions. The final results demonstrate that Hawk achieves SOTA performance, surpassing existing baselines in both video description generation and question-answering. Our codes/dataset/demo will be released at https://github.com/jqtangust/hawk.
Read more5/28/2024

0
Holmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM
Huaxin Zhang, Xiaohao Xu, Xiang Wang, Jialong Zuo, Chuchu Han, Xiaonan Huang, Changxin Gao, Yuehuan Wang, Nong Sang
Towards open-ended Video Anomaly Detection (VAD), existing methods often exhibit biased detection when faced with challenging or unseen events and lack interpretability. To address these drawbacks, we propose Holmes-VAD, a novel framework that leverages precise temporal supervision and rich multimodal instructions to enable accurate anomaly localization and comprehensive explanations. Firstly, towards unbiased and explainable VAD system, we construct the first large-scale multimodal VAD instruction-tuning benchmark, i.e., VAD-Instruct50k. This dataset is created using a carefully designed semi-automatic labeling paradigm. Efficient single-frame annotations are applied to the collected untrimmed videos, which are then synthesized into high-quality analyses of both abnormal and normal video clips using a robust off-the-shelf video captioner and a large language model (LLM). Building upon the VAD-Instruct50k dataset, we develop a customized solution for interpretable video anomaly detection. We train a lightweight temporal sampler to select frames with high anomaly response and fine-tune a multimodal large language model (LLM) to generate explanatory content. Extensive experimental results validate the generality and interpretability of the proposed Holmes-VAD, establishing it as a novel interpretable technique for real-world video anomaly analysis. To support the community, our benchmark and model will be publicly available at https://holmesvad.github.io.
Read more7/2/2024
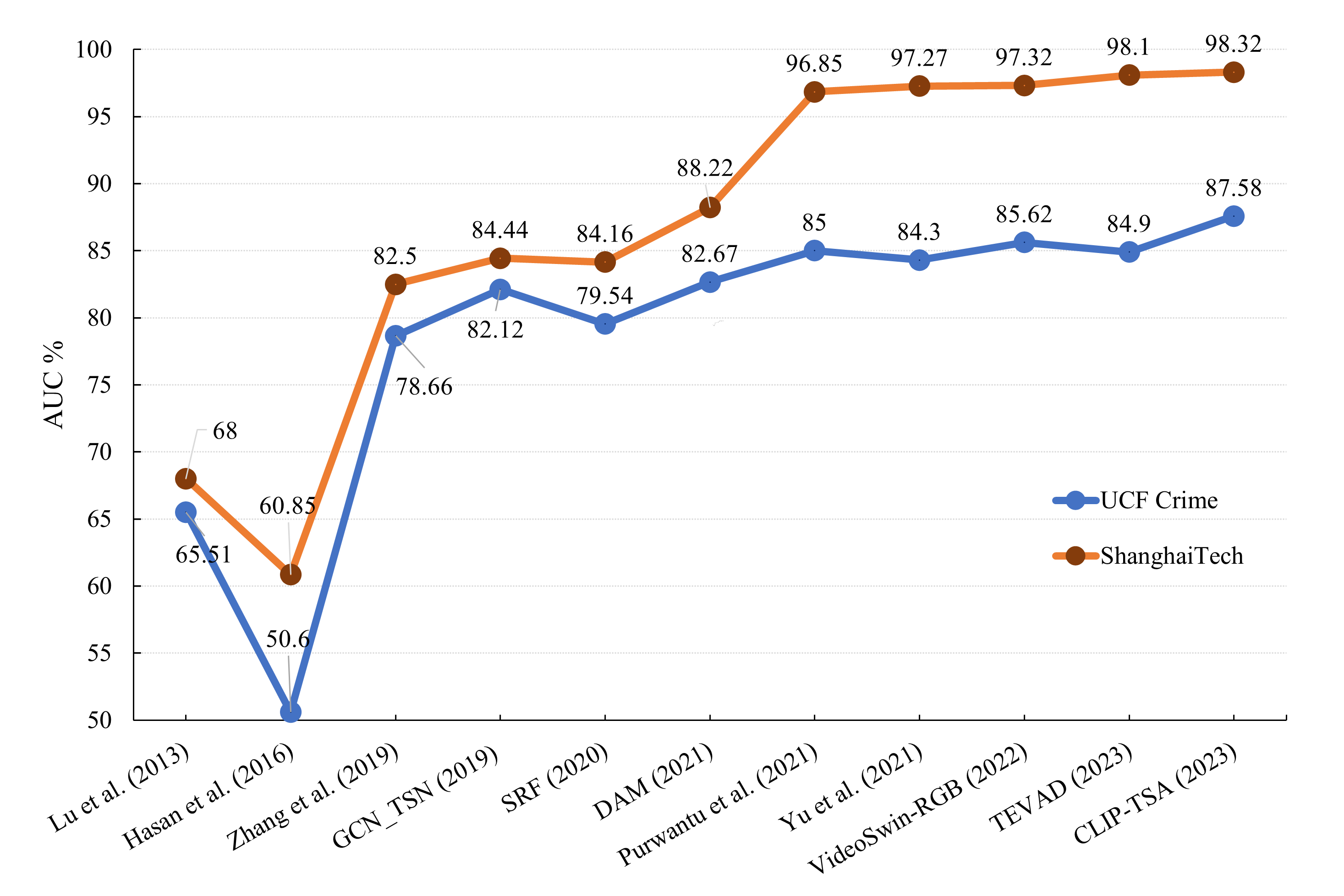
0
Video Anomaly Detection in 10 Years: A Survey and Outlook
Moshira Abdalla, Sajid Javed, Muaz Al Radi, Anwaar Ulhaq, Naoufel Werghi
Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
Read more7/2/2024

0
Evaluating the Effectiveness of Video Anomaly Detection in the Wild: Online Learning and Inference for Real-world Deployment
Shanle Yao, Ghazal Alinezhad Noghre, Armin Danesh Pazho, Hamed Tabkhi
Video Anomaly Detection (VAD) identifies unusual activities in video streams, a key technology with broad applications ranging from surveillance to healthcare. Tackling VAD in real-life settings poses significant challenges due to the dynamic nature of human actions, environmental variations, and domain shifts. Many research initiatives neglect these complexities, often concentrating on traditional testing methods that fail to account for performance on unseen datasets, creating a gap between theoretical models and their real-world utility. Online learning is a potential strategy to mitigate this issue by allowing models to adapt to new information continuously. This paper assesses how well current VAD algorithms can adjust to real-life conditions through an online learning framework, particularly those based on pose analysis, for their efficiency and privacy advantages. Our proposed framework enables continuous model updates with streaming data from novel environments, thus mirroring actual world challenges and evaluating the models' ability to adapt in real-time while maintaining accuracy. We investigate three state-of-the-art models in this setting, focusing on their adaptability across different domains. Our findings indicate that, even under the most challenging conditions, our online learning approach allows a model to preserve 89.39% of its original effectiveness compared to its offline-trained counterpart in a specific target domain.
Read more4/30/2024