Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection
2404.09654
0
0
Abstract
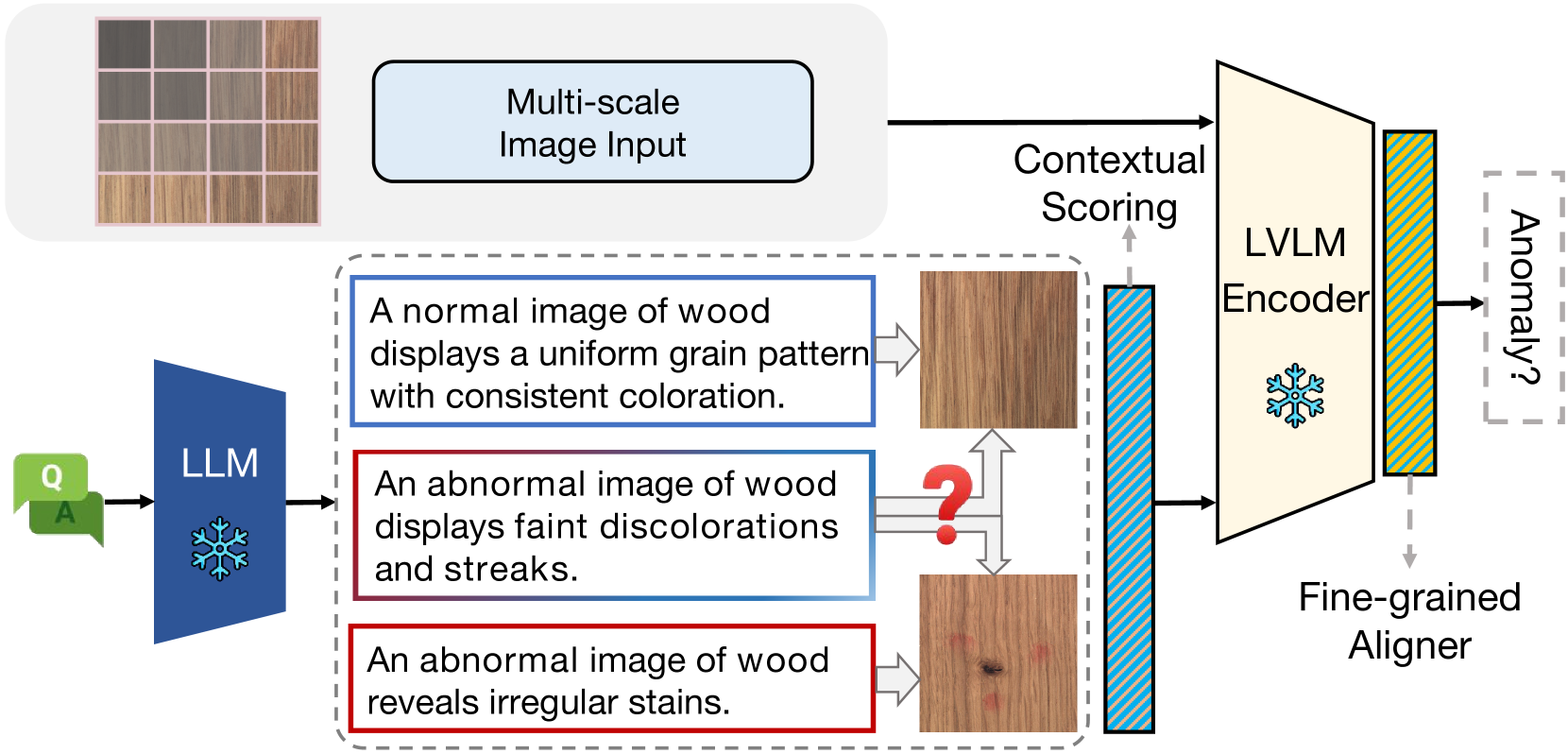
Large vision-language models (LVLMs) are markedly proficient in deriving visual representations guided by natural language. Recent explorations have utilized LVLMs to tackle zero-shot visual anomaly detection (VAD) challenges by pairing images with textual descriptions indicative of normal and abnormal conditions, referred to as anomaly prompts. However, existing approaches depend on static anomaly prompts that are prone to cross-semantic ambiguity, and prioritize global image-level representations over crucial local pixel-level image-to-text alignment that is necessary for accurate anomaly localization. In this paper, we present ALFA, a training-free approach designed to address these challenges via a unified model. We propose a run-time prompt adaptation strategy, which first generates informative anomaly prompts to leverage the capabilities of a large language model (LLM). This strategy is enhanced by a contextual scoring mechanism for per-image anomaly prompt adaptation and cross-semantic ambiguity mitigation. We further introduce a novel fine-grained aligner to fuse local pixel-level semantics for precise anomaly localization, by projecting the image-text alignment from global to local semantic spaces. Extensive evaluations on the challenging MVTec and VisA datasets confirm ALFA's effectiveness in harnessing the language potential for zero-shot VAD, achieving significant PRO improvements of 12.1% on MVTec AD and 8.9% on VisA compared to state-of-the-art zero-shot VAD approaches.
Create account to get full access
Overview
• This paper explores whether large language models (LLMs) can understand visual anomalies, which are unusual or unexpected elements in images. The researchers investigate the zero-shot anomaly detection capabilities of LLMs, meaning the models' ability to detect anomalies without being explicitly trained on that task.
Plain English Explanation
• The paper examines whether powerful language models like GPT-3 and CLIP can recognize when an image contains something unusual or out of the ordinary, even if they haven't been shown examples of anomalies before.
• The researchers wanted to see if these large language models, which are trained on a vast amount of text data, could leverage their understanding of language and visual concepts to spot anomalies in images in a "zero-shot" setting - without any special training on anomaly detection.
• This is an interesting capability, as being able to identify unusual elements in images could have many practical applications, like detecting defects in manufacturing or identifying potentially harmful objects.
Technical Explanation
• The researchers conducted a series of experiments to evaluate the zero-shot anomaly detection capabilities of various LLMs, including GPT-3, CLIP, and Improved Zero-Shot Classification.
• They assembled a dataset of images containing visual anomalies, such as unexpected objects or unusual arrangements. The models were then prompted to classify each image as containing an anomaly or not.
• The results showed that the LLMs were surprisingly effective at this zero-shot anomaly detection task, often outperforming specialized anomaly detection algorithms. The models seemed to leverage their broad understanding of visual concepts and language to identify the anomalies.
Critical Analysis
• The paper acknowledges that the LLMs' performance was not perfect, and their anomaly detection abilities may be limited to certain types of anomalies or visual domains. More research is needed to fully understand the scope and limitations of this capability.
• Additionally, the paper does not explore how the LLMs arrive at their anomaly predictions or what specific visual cues they are using. Further analysis of the model's internal representations and decision-making process could provide valuable insights.
• Overall, the findings suggest that LLMs have surprising capabilities in zero-shot visual anomaly detection, but more work is needed to understand the practical implications and potential applications of this technology.
Conclusion
• This research demonstrates that large language models can exhibit impressive zero-shot anomaly detection capabilities, suggesting they have a deeper understanding of visual concepts than previously thought.
• These findings could pave the way for new applications of LLMs in areas like quality control, safety, and security, where the ability to quickly identify unusual or potentially problematic elements in images could be highly valuable.
• However, the limitations and underlying mechanisms of this capability require further exploration to fully harness the potential of LLMs in visual anomaly detection tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
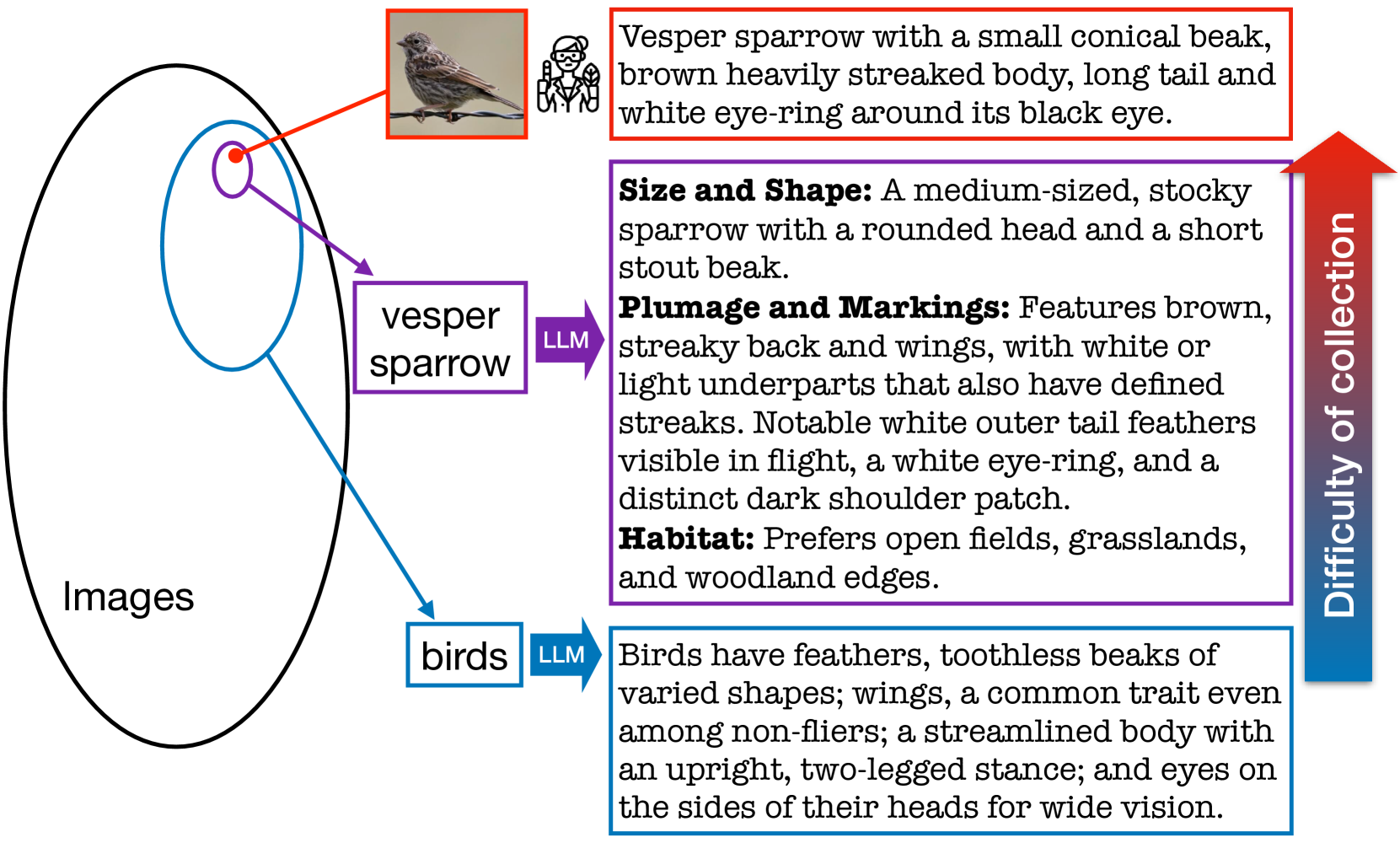
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024

Human-free Prompted Based Anomaly Detection: prompt optimization with Meta-guiding prompt scheme
Pi-Wei Chen, Jerry Chun-Wei Lin, Jia Ji, Feng-Hao Yeh, Chao-Chun Chen
0
0
Pre-trained vision-language models (VLMs) are highly adaptable to various downstream tasks through few-shot learning, making prompt-based anomaly detection a promising approach. Traditional methods depend on human-crafted prompts that require prior knowledge of specific anomaly types. Our goal is to develop a human-free prompt-based anomaly detection framework that optimally learns prompts through data-driven methods, eliminating the need for human intervention. The primary challenge in this approach is the lack of anomalous samples during the training phase. Additionally, the Vision Transformer (ViT)-based image encoder in VLMs is not ideal for pixel-wise anomaly segmentation due to a locality feature mismatch between the original image and the output feature map. To tackle the first challenge, we have developed the Object-Attention Anomaly Generation Module (OAGM) to synthesize anomaly samples for training. Furthermore, our Meta-Guiding Prompt-Tuning Scheme (MPTS) iteratively adjusts the gradient-based optimization direction of learnable prompts to avoid overfitting to the synthesized anomalies. For the second challenge, we propose Locality-Aware Attention, which ensures that each local patch feature attends only to nearby patch features, preserving the locality features corresponding to their original locations. This framework allows for the optimal prompt embeddings by searching in the continuous latent space via backpropagation, free from human semantic constraints. Additionally, the modified locality-aware attention improves the precision of pixel-wise anomaly segmentation.
6/27/2024

Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity
Zhenlin Xu, Yi Zhu, Tiffany Deng, Abhay Mittal, Yanbei Chen, Manchen Wang, Paolo Favaro, Joseph Tighe, Davide Modolo
0
0
This paper presents novel benchmarks for evaluating vision-language models (VLMs) in zero-shot recognition, focusing on granularity and specificity. Although VLMs excel in tasks like image captioning, they face challenges in open-world settings. Our benchmarks test VLMs' consistency in understanding concepts across semantic granularity levels and their response to varying text specificity. Findings show that VLMs favor moderately fine-grained concepts and struggle with specificity, often misjudging texts that differ from their training data. Extensive evaluations reveal limitations in current VLMs, particularly in distinguishing between correct and subtly incorrect descriptions. While fine-tuning offers some improvements, it doesn't fully address these issues, highlighting the need for VLMs with enhanced generalization capabilities for real-world applications. This study provides insights into VLM limitations and suggests directions for developing more robust models.
6/19/2024