HeightLane: BEV Heightmap guided 3D Lane Detection

0

Sign in to get full access
Overview
- Presents a new method called "HeightLane" for 3D lane detection that uses a bird's-eye view (BEV) heightmap to guide the detection process
- Leverages the height information in the BEV heightmap to improve the accuracy and robustness of 3D lane detection
- Proposes a novel architecture that combines a height predictor and a lane detector to jointly learn and refine the 3D lane geometry
Plain English Explanation
The paper introduces a new approach called "HeightLane" for detecting 3D lanes on roads using camera and LiDAR data. Typically, 3D lane detection can be challenging because the 3D geometry of the lanes is hard to infer from 2D camera images alone.
The key innovation of HeightLane is that it uses a bird's-eye view heightmap to guide the 3D lane detection process. This heightmap provides additional height information that helps the system better understand the 3D structure of the lanes. The heightmap is generated from the LiDAR data, which can measure the 3D geometry of the scene.
The HeightLane architecture consists of two main components: a height predictor and a lane detector. The height predictor learns to estimate the height of the road surface from the input data. The lane detector then uses this height information to more accurately detect the 3D geometry of the lane markings.
By combining the height prediction and lane detection in an end-to-end trainable model, the system can jointly refine both the height estimation and lane detection, leading to improved overall performance compared to previous methods that treated these as separate tasks.
Technical Explanation
The paper proposes a novel architecture called "HeightLane" for 3D lane detection that leverages a bird's-eye view (BEV) heightmap to guide the detection process. The heightmap is generated from the LiDAR data and provides valuable 3D geometric information about the road surface.
The HeightLane architecture consists of two main components:
-
Height Predictor: This module takes the input camera and LiDAR data and learns to estimate the height of the road surface in a BEV format.
-
Lane Detector: This module uses the predicted heightmap, along with the camera and LiDAR data, to detect the 3D geometry of the lane markings.
The key innovation is that the height predictor and lane detector are trained jointly in an end-to-end fashion. This allows the system to iteratively refine both the height estimation and lane detection, leading to improved overall performance compared to approaches that treat these as separate tasks.
The authors evaluate HeightLane on several benchmark datasets for 3D lane detection and demonstrate state-of-the-art results, outperforming previous methods that do not leverage the heightmap information.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the HeightLane method, including comparisons to several baseline approaches on multiple datasets. The authors acknowledge some potential limitations, such as the dependence on accurate LiDAR data for the heightmap generation and the need for further investigation into the generalization capabilities of the model across different road environments.
One area that could be explored further is the robustness of the HeightLane approach to noisy or incomplete LiDAR data, as real-world deployment may encounter such challenges. Additionally, the authors could consider extending the method to handle more complex lane geometries, such as intersections or lane changes, which are important for real-world autonomous driving applications.
Overall, the paper makes a compelling case for the benefits of leveraging heightmap information for 3D lane detection and provides a solid technical foundation for future research in this area.
Conclusion
The HeightLane paper presents a novel approach to 3D lane detection that effectively exploits the height information from a BEV heightmap to guide the detection process. By jointly learning the height prediction and lane detection tasks, the system is able to achieve state-of-the-art performance on several benchmarks.
The use of heightmap data is a promising direction for improving the accuracy and robustness of 3D lane detection, which is a critical component for autonomous driving systems. The authors have demonstrated the potential of this approach and have laid the groundwork for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HeightLane: BEV Heightmap guided 3D Lane Detection
Chaesong Park, Eunbin Seo, Jongwoo Lim
Accurate 3D lane detection from monocular images presents significant challenges due to depth ambiguity and imperfect ground modeling. Previous attempts to model the ground have often used a planar ground assumption with limited degrees of freedom, making them unsuitable for complex road environments with varying slopes. Our study introduces HeightLane, an innovative method that predicts a height map from monocular images by creating anchors based on a multi-slope assumption. This approach provides a detailed and accurate representation of the ground. HeightLane employs the predicted heightmap along with a deformable attention-based spatial feature transform framework to efficiently convert 2D image features into 3D bird's eye view (BEV) features, enhancing spatial understanding and lane structure recognition. Additionally, the heightmap is used for the positional encoding of BEV features, further improving their spatial accuracy. This explicit view transformation bridges the gap between front-view perceptions and spatially accurate BEV representations, significantly improving detection performance. To address the lack of the necessary ground truth (GT) height map in the original OpenLane dataset, we leverage the Waymo dataset and accumulate its LiDAR data to generate a height map for the drivable area of each scene. The GT heightmaps are used to train the heightmap extraction module from monocular images. Extensive experiments on the OpenLane validation set show that HeightLane achieves state-of-the-art performance in terms of F-score, highlighting its potential in real-world applications.
Read more8/16/2024
📊
0
HeightFormer: Explicit Height Modeling without Extra Data for Camera-only 3D Object Detection in Bird's Eye View
Yiming Wu, Ruixiang Li, Zequn Qin, Xinhai Zhao, Xi Li
Vision-based Bird's Eye View (BEV) representation is an emerging perception formulation for autonomous driving. The core challenge is to construct BEV space with multi-camera features, which is a one-to-many ill-posed problem. Diving into all previous BEV representation generation methods, we found that most of them fall into two types: modeling depths in image views or modeling heights in the BEV space, mostly in an implicit way. In this work, we propose to explicitly model heights in the BEV space, which needs no extra data like LiDAR and can fit arbitrary camera rigs and types compared to modeling depths. Theoretically, we give proof of the equivalence between height-based methods and depth-based methods. Considering the equivalence and some advantages of modeling heights, we propose HeightFormer, which models heights and uncertainties in a self-recursive way. Without any extra data, the proposed HeightFormer could estimate heights in BEV accurately. Benchmark results show that the performance of HeightFormer achieves SOTA compared with those camera-only methods.
Read more7/17/2024

0
DV-3DLane: End-to-end Multi-modal 3D Lane Detection with Dual-view Representation
Yueru Luo, Shuguang Cui, Zhen Li
Accurate 3D lane estimation is crucial for ensuring safety in autonomous driving. However, prevailing monocular techniques suffer from depth loss and lighting variations, hampering accurate 3D lane detection. In contrast, LiDAR points offer geometric cues and enable precise localization. In this paper, we present DV-3DLane, a novel end-to-end Dual-View multi-modal 3D Lane detection framework that synergizes the strengths of both images and LiDAR points. We propose to learn multi-modal features in dual-view spaces, i.e., perspective view (PV) and bird's-eye-view (BEV), effectively leveraging the modal-specific information. To achieve this, we introduce three designs: 1) A bidirectional feature fusion strategy that integrates multi-modal features into each view space, exploiting their unique strengths. 2) A unified query generation approach that leverages lane-aware knowledge from both PV and BEV spaces to generate queries. 3) A 3D dual-view deformable attention mechanism, which aggregates discriminative features from both PV and BEV spaces into queries for accurate 3D lane detection. Extensive experiments on the public benchmark, OpenLane, demonstrate the efficacy and efficiency of DV-3DLane. It achieves state-of-the-art performance, with a remarkable 11.2 gain in F1 score and a substantial 53.5% reduction in errors. The code is available at url{https://github.com/JMoonr/dv-3dlane}.
Read more6/26/2024
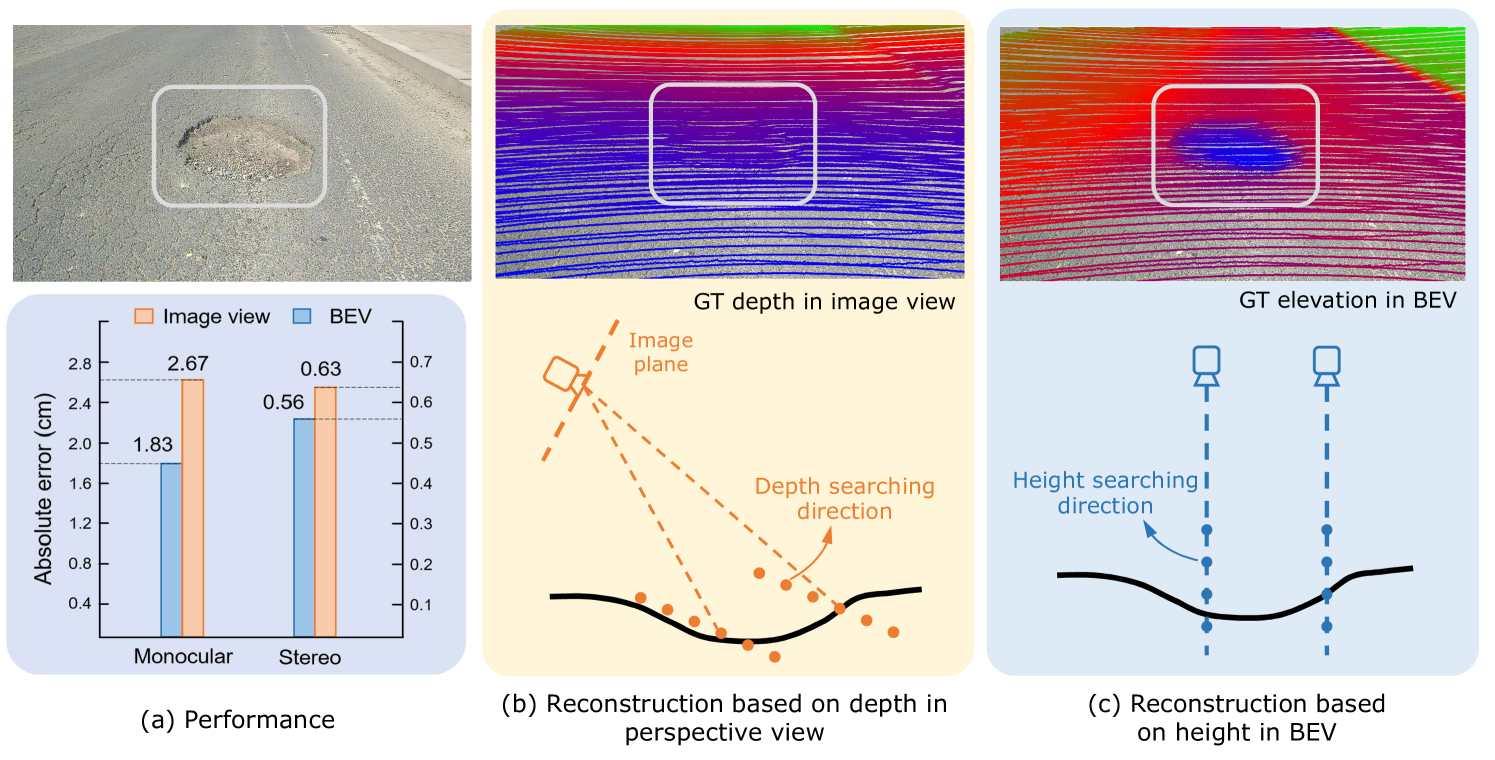
0
RoadBEV: Road Surface Reconstruction in Bird's Eye View
Tong Zhao, Lei Yang, Yichen Xie, Mingyu Ding, Masayoshi Tomizuka, Yintao Wei
Road surface conditions, especially geometry profiles, enormously affect driving performance of autonomous vehicles. Vision-based online road reconstruction promisingly captures road information in advance. Existing solutions like monocular depth estimation and stereo matching suffer from modest performance. The recent technique of Bird's-Eye-View (BEV) perception provides immense potential to more reliable and accurate reconstruction. This paper uniformly proposes two simple yet effective models for road elevation reconstruction in BEV named RoadBEV-mono and RoadBEV-stereo, which estimate road elevation with monocular and stereo images, respectively. The former directly fits elevation values based on voxel features queried from image view, while the latter efficiently recognizes road elevation patterns based on BEV volume representing correlation between left and right voxel features. Insightful analyses reveal their consistence and difference with the perspective view. Experiments on real-world dataset verify the models' effectiveness and superiority. Elevation errors of RoadBEV-mono and RoadBEV-stereo achieve 1.83 cm and 0.50 cm, respectively. Our models are promising for practical road preview, providing essential information for promoting safety and comfort of autonomous vehicles. The code is released at https://github.com/ztsrxh/RoadBEV
Read more8/9/2024