RoadBEV: Road Surface Reconstruction in Bird's Eye View
2404.06605
0
0
Abstract
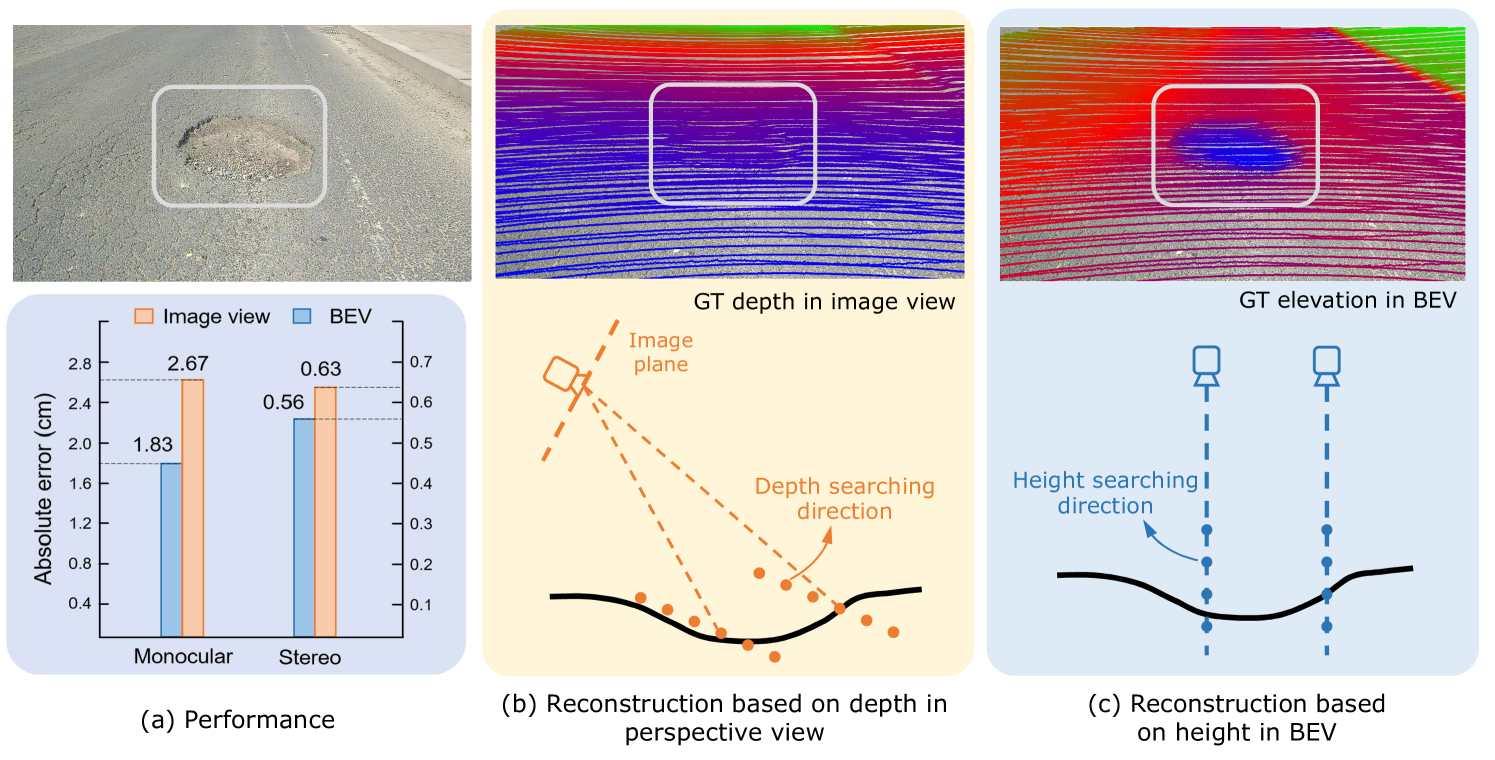
Road surface conditions, especially geometry profiles, enormously affect driving performance of autonomous vehicles. Vision-based online road reconstruction promisingly captures road information in advance. Existing solutions like monocular depth estimation and stereo matching suffer from modest performance. The recent technique of Bird's-Eye-View (BEV) perception provides immense potential to more reliable and accurate reconstruction. This paper uniformly proposes two simple yet effective models for road elevation reconstruction in BEV named RoadBEV-mono and RoadBEV-stereo, which estimate road elevation with monocular and stereo images, respectively. The former directly fits elevation values based on voxel features queried from image view, while the latter efficiently recognizes road elevation patterns based on BEV volume representing discrepancy between left and right voxel features. Insightful analyses reveal their consistence and difference with perspective view. Experiments on real-world dataset verify the models' effectiveness and superiority. Elevation errors of RoadBEV-mono and RoadBEV-stereo achieve 1.83cm and 0.50cm, respectively. The estimation performance improves by 50% in BEV based on monocular image. Our models are promising for practical applications, providing valuable references for vision-based BEV perception in autonomous driving. The code is released at https://github.com/ztsrxh/RoadBEV.
Create account to get full access
Overview
- This paper presents a novel approach called RoadBEV for reconstructing road surfaces in a bird's eye view (BEV) perspective.
- The proposed method aims to enable accurate and efficient reconstruction of road surfaces, which is crucial for various autonomous driving applications.
- RoadBEV leverages deep learning techniques to transform input data, such as point clouds or images, into a BEV representation of the road surface.
Plain English Explanation
RoadBEV: Towards Accurate Road Surface Reconstruction in Bird's Eye View
Navigating roads and avoiding obstacles is a critical challenge for self-driving cars. To address this, researchers have developed a new technique called RoadBEV that can accurately reconstruct the road surface from sensor data.
The key idea behind RoadBEV is to transform the data collected by the car's cameras and sensors into a "bird's eye view" (BEV) representation of the road. This BEV format provides a top-down perspective that makes it easier to understand the road layout and identify potential hazards.
To create the BEV representation, RoadBEV uses advanced deep learning algorithms to process the sensor data. These algorithms can identify the boundaries of the road, detect cracks or potholes, and map out the entire road surface in 3D. This detailed road reconstruction is crucial for self-driving cars to plan their routes, stay centered in their lane, and respond safely to changing road conditions.
Compared to previous approaches, RoadBEV is more accurate, efficient, and robust to different environments and sensor setups. By providing a clear and comprehensive view of the road, RoadBEV helps autonomous vehicles navigate more safely and reliably.
Technical Explanation
The RoadBEV paper introduces a novel deep learning-based method for reconstructing road surfaces in a bird's eye view (BEV) perspective. The key technical components of the RoadBEV approach include:
-
Data Representation: The method takes in input data, such as point clouds or camera images, and transforms them into a BEV representation of the road surface. This Bird's Eye View format provides a top-down perspective that facilitates understanding the road layout and identifying potential obstacles.
-
Deep Learning Architecture: RoadBEV employs a deep neural network that is designed to effectively process the input data and output an accurate BEV reconstruction of the road. The network architecture includes specialized modules for tasks like road boundary detection and 3D surface reconstruction.
-
Multi-Modal Fusion: To leverage different sensor modalities (e.g., cameras, LiDAR), RoadBEV fuses the input data from various sources to improve the quality and robustness of the road reconstruction.
-
Domain Adaptation: The method incorporates techniques to adapt the deep learning model to different environments and driving conditions, ensuring reliable performance across a variety of scenarios.
The paper evaluates the RoadBEV approach on several benchmarks and demonstrates its superior performance compared to previous methods in terms of accuracy, efficiency, and generalization capabilities. The proposed technique represents an important step towards enabling robust and precise road understanding for autonomous driving applications.
Critical Analysis
The RoadBEV paper presents a promising approach for road surface reconstruction in a bird's eye view, but it also acknowledges several limitations and areas for future research:
-
Sensor Dependency: The current implementation of RoadBEV relies on specific sensor modalities, such as camera images and point clouds. Exploring ways to make the method more sensor-agnostic could improve its applicability in diverse autonomous driving setups.
-
Environmental Variations: While the authors demonstrate the ability to adapt RoadBEV to different environments, further research is needed to ensure robust performance under more extreme weather conditions, lighting changes, and infrastructure variations.
-
Real-time Performance: The paper focuses on the accuracy of the road reconstruction, but the computational efficiency of the method is not extensively evaluated. Optimizing the RoadBEV algorithm for real-time operation is crucial for its practical deployment in self-driving cars.
-
Occlusion Handling: The current approach does not explicitly address the challenge of occluded road sections, which can occur due to other vehicles, pedestrians, or infrastructure. Developing techniques to handle such occlusions would enhance the method's reliability in complex urban environments.
-
End-to-End Integration: The paper presents RoadBEV as a standalone module, but integrating it seamlessly into the broader autonomous driving pipeline could unlock additional benefits and synergies with other perception and planning components.
Overall, the RoadBEV paper makes a valuable contribution to the field of autonomous driving by introducing an effective road surface reconstruction technique. Further research addressing the identified limitations and exploring practical deployment considerations could lead to more advanced and reliable road understanding systems for self-driving vehicles.
Conclusion
The RoadBEV paper presents a novel deep learning-based approach for reconstructing road surfaces in a bird's eye view (BEV) format. This BEV representation provides a crucial top-down perspective that enables autonomous vehicles to better understand the road layout and plan their movements more effectively.
The key innovation of RoadBEV lies in its ability to transform input data, such as point clouds and camera images, into an accurate and detailed 3D reconstruction of the road surface. This includes detecting road boundaries, identifying potential hazards like cracks or potholes, and mapping the entire road layout. By fusing data from multiple sensors, the method achieves robust performance across diverse environments and driving conditions.
The successful development and evaluation of RoadBEV represents an important step towards enabling more reliable and capable autonomous driving systems. By providing a comprehensive and precise understanding of the road surface, this technology can help self-driving cars navigate with greater safety, efficiency, and adaptability. As the authors have highlighted, further research to address the identified limitations and integrate RoadBEV into end-to-end autonomous driving pipelines could lead to even more advanced road understanding capabilities in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Benchmarking and Improving Bird's Eye View Perception Robustness in Autonomous Driving
Shaoyuan Xie, Lingdong Kong, Wenwei Zhang, Jiawei Ren, Liang Pan, Kai Chen, Ziwei Liu
0
0
Recent advancements in bird's eye view (BEV) representations have shown remarkable promise for in-vehicle 3D perception. However, while these methods have achieved impressive results on standard benchmarks, their robustness in varied conditions remains insufficiently assessed. In this study, we present RoboBEV, an extensive benchmark suite designed to evaluate the resilience of BEV algorithms. This suite incorporates a diverse set of camera corruption types, each examined over three severity levels. Our benchmarks also consider the impact of complete sensor failures that occur when using multi-modal models. Through RoboBEV, we assess 33 state-of-the-art BEV-based perception models spanning tasks like detection, map segmentation, depth estimation, and occupancy prediction. Our analyses reveal a noticeable correlation between the model's performance on in-distribution datasets and its resilience to out-of-distribution challenges. Our experimental results also underline the efficacy of strategies like pre-training and depth-free BEV transformations in enhancing robustness against out-of-distribution data. Furthermore, we observe that leveraging extensive temporal information significantly improves the model's robustness. Based on our observations, we design an effective robustness enhancement strategy based on the CLIP model. The insights from this study pave the way for the development of future BEV models that seamlessly combine accuracy with real-world robustness.
5/28/2024

BEVRender: Vision-based Cross-view Vehicle Registration in Off-road GNSS-denied Environment
Lihong Jin, Wei Dong, Michael Kaess
0
0
We introduce BEVRender, a novel learning-based approach for the localization of ground vehicles in Global Navigation Satellite System (GNSS)-denied off-road scenarios. These environments are typically challenging for conventional vision-based state estimation due to the lack of distinct visual landmarks and the instability of vehicle poses. To address this, BEVRender generates high-quality local bird's eye view (BEV) images of the local terrain. Subsequently, these images are aligned with a geo-referenced aerial map via template-matching to achieve accurate cross-view registration. Our approach overcomes the inherent limitations of visual inertial odometry systems and the substantial storage requirements of image-retrieval localization strategies, which are susceptible to drift and scalability issues, respectively. Extensive experimentation validates BEVRender's advancement over existing GNSS-denied visual localization methods, demonstrating notable enhancements in both localization accuracy and update frequency. The code for BEVRender will be made available soon.
5/16/2024

Improving Bird's Eye View Semantic Segmentation by Task Decomposition
Tianhao Zhao, Yongcan Chen, Yu Wu, Tianyang Liu, Bo Du, Peilun Xiao, Shi Qiu, Hongda Yang, Guozhen Li, Yi Yang, Yutian Lin
0
0
Semantic segmentation in bird's eye view (BEV) plays a crucial role in autonomous driving. Previous methods usually follow an end-to-end pipeline, directly predicting the BEV segmentation map from monocular RGB inputs. However, the challenge arises when the RGB inputs and BEV targets from distinct perspectives, making the direct point-to-point predicting hard to optimize. In this paper, we decompose the original BEV segmentation task into two stages, namely BEV map reconstruction and RGB-BEV feature alignment. In the first stage, we train a BEV autoencoder to reconstruct the BEV segmentation maps given corrupted noisy latent representation, which urges the decoder to learn fundamental knowledge of typical BEV patterns. The second stage involves mapping RGB input images into the BEV latent space of the first stage, directly optimizing the correlations between the two views at the feature level. Our approach simplifies the complexity of combining perception and generation into distinct steps, equipping the model to handle intricate and challenging scenes effectively. Besides, we propose to transform the BEV segmentation map from the Cartesian to the polar coordinate system to establish the column-wise correspondence between RGB images and BEV maps. Moreover, our method requires neither multi-scale features nor camera intrinsic parameters for depth estimation and saves computational overhead. Extensive experiments on nuScenes and Argoverse show the effectiveness and efficiency of our method. Code is available at https://github.com/happytianhao/TaDe.
4/3/2024

GraphBEV: Towards Robust BEV Feature Alignment for Multi-Modal 3D Object Detection
Ziying Song, Lei Yang, Shaoqing Xu, Lin Liu, Dongyang Xu, Caiyan Jia, Feiyang Jia, Li Wang
0
0
Integrating LiDAR and camera information into Bird's-Eye-View (BEV) representation has emerged as a crucial aspect of 3D object detection in autonomous driving. However, existing methods are susceptible to the inaccurate calibration relationship between LiDAR and the camera sensor. Such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a robust fusion framework called Graph BEV. Addressing errors caused by inaccurate point cloud projection, we introduce a Local Align module that employs neighbor-aware depth features via Graph matching. Additionally, we propose a Global Align module to rectify the misalignment between LiDAR and camera BEV features. Our Graph BEV framework achieves state-of-the-art performance, with an mAP of 70.1%, surpassing BEV Fusion by 1.6% on the nuscenes validation set. Importantly, our Graph BEV outperforms BEV Fusion by 8.3% under conditions with misalignment noise.
4/11/2024