Here's a Free Lunch: Sanitizing Backdoored Models with Model Merge
2402.19334
0
0

Abstract
The democratization of pre-trained language models through open-source initiatives has rapidly advanced innovation and expanded access to cutting-edge technologies. However, this openness also brings significant security risks, including backdoor attacks, where hidden malicious behaviors are triggered by specific inputs, compromising natural language processing (NLP) system integrity and reliability. This paper suggests that merging a backdoored model with other homogeneous models can significantly remediate backdoor vulnerabilities even if such models are not entirely secure. In our experiments, we verify our hypothesis on various models (BERT-Base, RoBERTa-Large, Llama2-7B, and Mistral-7B) and datasets (SST-2, OLID, AG News, and QNLI). Compared to multiple advanced defensive approaches, our method offers an effective and efficient inference-stage defense against backdoor attacks on classification and instruction-tuned tasks without additional resources or specific knowledge. Our approach consistently outperforms recent advanced baselines, leading to an average of about 75% reduction in the attack success rate. Since model merging has been an established approach for improving model performance, the extra advantage it provides regarding defense can be seen as a cost-free bonus.
Create account to get full access
Overview
- Researchers propose a method called "Model Merge" to sanitize backdoored machine learning models by merging them with clean, trusted models.
- Backdoored models are models that have been maliciously altered to perform unexpected behaviors, like misclassifying certain inputs.
- The Model Merge technique aims to remove these backdoors without the need for complex backdoor detection or model retraining.
Plain English Explanation
Machine learning models, like the ones used for image recognition or language processing, can sometimes be "backdoored" - meaning they've been secretly altered to behave in unexpected ways. For example, a backdoored image recognition model might always classify a certain type of image as something else, even though it works fine for most inputs.
Backdoor attacks and defenses are a major concern in AI safety, as they can allow bad actors to exploit models for nefarious purposes. The researchers in this paper propose a novel technique called "Model Merge" to help address this problem.
The key idea is to take a backdoored model and "merge" it with a clean, trusted model. This merging process effectively "sanitizes" the backdoored model, removing the malicious backdoor behavior without the need for complex backdoor detection or full model retraining. It's like taking a cake with a hidden poison and mixing it with a perfectly good cake - the result is a cake that's safe to eat.
Exploring backdoor attacks against large language models and exploring backdoor vulnerabilities in chat models have shown how pervasive this problem can be, so techniques like Model Merge could be an important tool for securing AI systems against these kinds of attacks.
Technical Explanation
The researchers propose a "Model Merge" technique to sanitize backdoored machine learning models. The core idea is to take a backdoored model and merge it with a clean, trusted model to effectively remove the backdoor behavior.
Formally, let M_bad be the backdoored model and M_clean be the clean model. The researchers define a merge operation M_merged = M_Merge(M_bad, M_clean) that produces a new model M_merged which retains the desired functionality of M_clean while removing the backdoor behavior of M_bad.
The key aspects of the Model Merge technique are:
- Preserving Functionality: The merged model
M_mergedmaintains the core functionality of the clean modelM_clean, ensuring no degradation in performance on normal inputs. - Backdoor Removal: The merged model
M_mergedno longer exhibits the backdoor behavior of the original backdoored modelM_bad. - Efficiency: Model Merge is an efficient process that does not require complex backdoor detection or full model retraining, making it a practical defense against backdoor attacks.
The researchers demonstrate the effectiveness of Model Merge through experiments on computer vision and natural language processing tasks, showing that it can successfully remove backdoors without impacting model performance. They also analyze the inner mechanisms of backdoored language models to better understand the merging process.
Critical Analysis
The Model Merge technique proposed in this paper is a promising approach for addressing the growing threat of backdoor attacks in machine learning. By providing an efficient way to sanitize backdoored models without degrading their core functionality, it could be a valuable tool for improving the security and robustness of AI systems.
That said, the paper does acknowledge some limitations and areas for further research. For example, the merging process may not work as effectively in cases where the backdoor is deeply integrated into the model's architecture or when the clean and backdoored models have significantly different architectures.
Additionally, the paper focuses on single-task models, and it's unclear how well the Model Merge approach would scale to more complex, multi-task models that are common in modern AI systems. Backdoor attacks on multilingual machine translation models also present unique challenges that the current work does not address.
Further research is needed to explore the limits of Model Merge, its applicability to different model types and attack scenarios, and potential ways to make the merging process more robust and versatile. Ongoing work in this area will be crucial for developing effective defenses against the growing threat of backdoor attacks in AI.
Conclusion
The "Here's a Free Lunch: Sanitizing Backdoored Models with Model Merge" paper presents a novel technique for addressing the critical problem of backdoored machine learning models. By merging a backdoored model with a clean, trusted model, the researchers demonstrate an efficient way to remove the malicious backdoor behavior without sacrificing the model's core functionality.
This work represents an important step forward in the ongoing efforts to secure AI systems against backdoor attacks, which have emerged as a significant threat to the widespread adoption and deployment of machine learning technologies. As the field continues to grapple with these challenges, techniques like Model Merge could prove invaluable in building more robust and trustworthy AI systems that can be safely deployed in high-stakes applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Survey of Backdoor Attacks and Defenses on Large Language Models: Implications for Security Measures
Shuai Zhao, Meihuizi Jia, Zhongliang Guo, Leilei Gan, Jie Fu, Yichao Feng, Fengjun Pan, Luu Anh Tuan
0
0
The large language models (LLMs), which bridge the gap between human language understanding and complex problem-solving, achieve state-of-the-art performance on several NLP tasks, particularly in few-shot and zero-shot settings. Despite the demonstrable efficacy of LMMs, due to constraints on computational resources, users have to engage with open-source language models or outsource the entire training process to third-party platforms. However, research has demonstrated that language models are susceptible to potential security vulnerabilities, particularly in backdoor attacks. Backdoor attacks are designed to introduce targeted vulnerabilities into language models by poisoning training samples or model weights, allowing attackers to manipulate model responses through malicious triggers. While existing surveys on backdoor attacks provide a comprehensive overview, they lack an in-depth examination of backdoor attacks specifically targeting LLMs. To bridge this gap and grasp the latest trends in the field, this paper presents a novel perspective on backdoor attacks for LLMs by focusing on fine-tuning methods. Specifically, we systematically classify backdoor attacks into three categories: full-parameter fine-tuning, parameter-efficient fine-tuning, and attacks without fine-tuning. Based on insights from a substantial review, we also discuss crucial issues for future research on backdoor attacks, such as further exploring attack algorithms that do not require fine-tuning, or developing more covert attack algorithms.
6/14/2024
💬
Backdoor Removal for Generative Large Language Models
Haoran Li, Yulin Chen, Zihao Zheng, Qi Hu, Chunkit Chan, Heshan Liu, Yangqiu Song
0
0
With rapid advances, generative large language models (LLMs) dominate various Natural Language Processing (NLP) tasks from understanding to reasoning. Yet, language models' inherent vulnerabilities may be exacerbated due to increased accessibility and unrestricted model training on massive textual data from the Internet. A malicious adversary may publish poisoned data online and conduct backdoor attacks on the victim LLMs pre-trained on the poisoned data. Backdoored LLMs behave innocuously for normal queries and generate harmful responses when the backdoor trigger is activated. Despite significant efforts paid to LLMs' safety issues, LLMs are still struggling against backdoor attacks. As Anthropic recently revealed, existing safety training strategies, including supervised fine-tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), fail to revoke the backdoors once the LLM is backdoored during the pre-training stage. In this paper, we present Simulate and Eliminate (SANDE) to erase the undesired backdoored mappings for generative LLMs. We initially propose Overwrite Supervised Fine-tuning (OSFT) for effective backdoor removal when the trigger is known. Then, to handle the scenarios where the trigger patterns are unknown, we integrate OSFT into our two-stage framework, SANDE. Unlike previous works that center on the identification of backdoors, our safety-enhanced LLMs are able to behave normally even when the exact triggers are activated. We conduct comprehensive experiments to show that our proposed SANDE is effective against backdoor attacks while bringing minimal harm to LLMs' powerful capability without any additional access to unbackdoored clean models. We will release the reproducible code.
5/14/2024
💬
Exploring Backdoor Attacks against Large Language Model-based Decision Making
Ruochen Jiao, Shaoyuan Xie, Justin Yue, Takami Sato, Lixu Wang, Yixuan Wang, Qi Alfred Chen, Qi Zhu
0
0
Large Language Models (LLMs) have shown significant promise in decision-making tasks when fine-tuned on specific applications, leveraging their inherent common sense and reasoning abilities learned from vast amounts of data. However, these systems are exposed to substantial safety and security risks during the fine-tuning phase. In this work, we propose the first comprehensive framework for Backdoor Attacks against LLM-enabled Decision-making systems (BALD), systematically exploring how such attacks can be introduced during the fine-tuning phase across various channels. Specifically, we propose three attack mechanisms and corresponding backdoor optimization methods to attack different components in the LLM-based decision-making pipeline: word injection, scenario manipulation, and knowledge injection. Word injection embeds trigger words directly into the query prompt. Scenario manipulation occurs in the physical environment, where a high-level backdoor semantic scenario triggers the attack. Knowledge injection conducts backdoor attacks on retrieval augmented generation (RAG)-based LLM systems, strategically injecting word triggers into poisoned knowledge while ensuring the information remains factually accurate for stealthiness. We conduct extensive experiments with three popular LLMs (GPT-3.5, LLaMA2, PaLM2), using two datasets (HighwayEnv, nuScenes), and demonstrate the effectiveness and stealthiness of our backdoor triggers and mechanisms. Finally, we critically assess the strengths and weaknesses of our proposed approaches, highlight the inherent vulnerabilities of LLMs in decision-making tasks, and evaluate potential defenses to safeguard LLM-based decision making systems.
6/3/2024
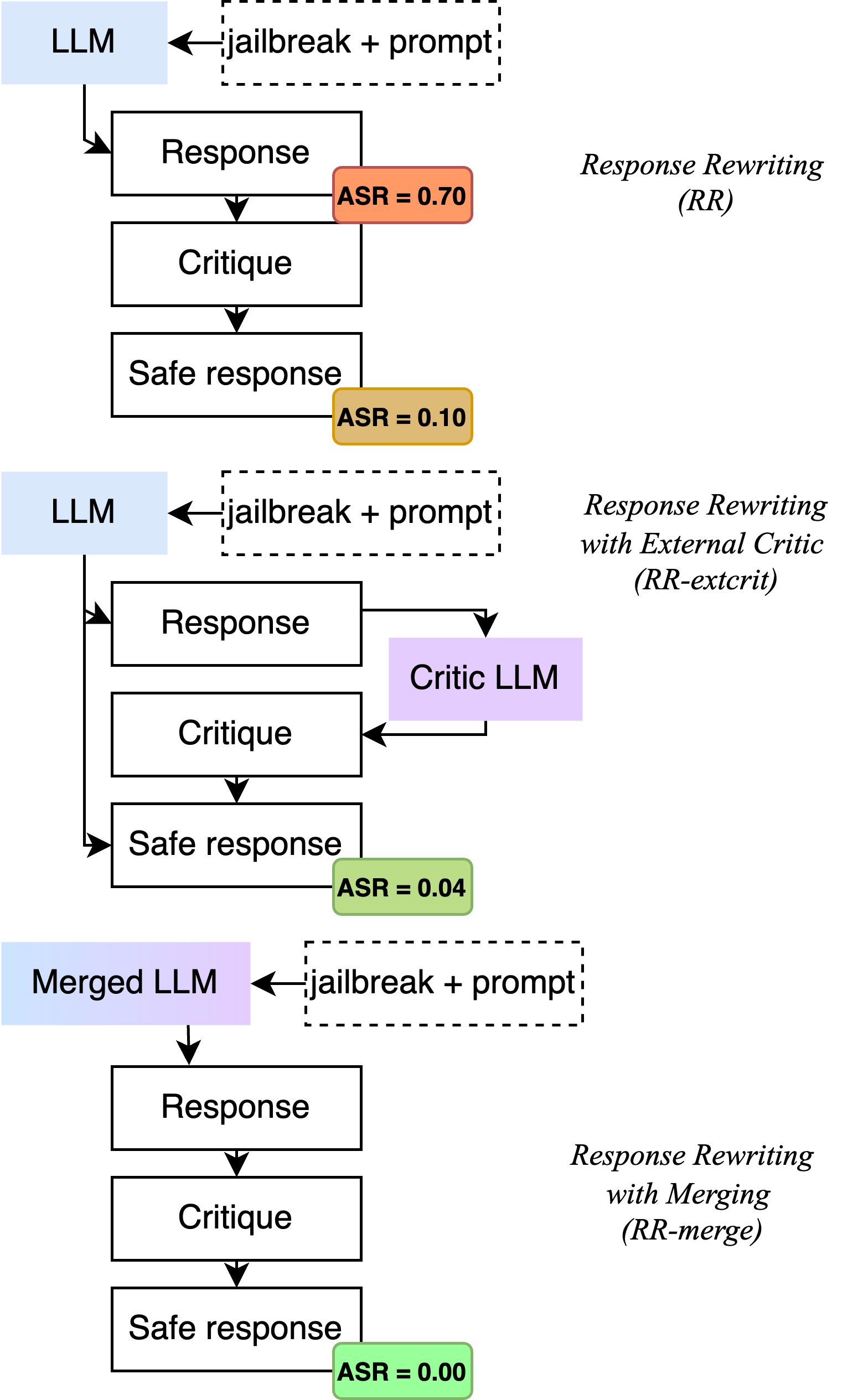
Merging Improves Self-Critique Against Jailbreak Attacks
Victor Gallego
0
0
The robustness of large language models (LLMs) against adversarial manipulations, such as jailbreak attacks, remains a significant challenge. In this work, we propose an approach that enhances the self-critique capability of the LLM and further fine-tunes it over sanitized synthetic data. This is done with the addition of an external critic model that can be merged with the original, thus bolstering self-critique capabilities and improving the robustness of the LLMs response to adversarial prompts. Our results demonstrate that the combination of merging and self-critique can reduce the attack success rate of adversaries significantly, thus offering a promising defense mechanism against jailbreak attacks. Code, data and models released at https://github.com/vicgalle/merging-self-critique-jailbreaks .
6/12/2024