The Heuristic Core: Understanding Subnetwork Generalization in Pretrained Language Models
2403.03942
0
0

Abstract
Prior work has found that pretrained language models (LMs) fine-tuned with different random seeds can achieve similar in-domain performance but generalize differently on tests of syntactic generalization. In this work, we show that, even within a single model, we can find multiple subnetworks that perform similarly in-domain, but generalize vastly differently. To better understand these phenomena, we investigate if they can be understood in terms of competing subnetworks: the model initially represents a variety of distinct algorithms, corresponding to different subnetworks, and generalization occurs when it ultimately converges to one. This explanation has been used to account for generalization in simple algorithmic tasks (grokking). Instead of finding competing subnetworks, we find that all subnetworks -- whether they generalize or not -- share a set of attention heads, which we refer to as the heuristic core. Further analysis suggests that these attention heads emerge early in training and compute shallow, non-generalizing features. The model learns to generalize by incorporating additional attention heads, which depend on the outputs of the heuristic heads to compute higher-level features. Overall, our results offer a more detailed picture of the mechanisms for syntactic generalization in pretrained LMs.
Create account to get full access
Overview
- This paper explores how pretrained language models (PLMs) can generalize to new tasks and datasets, even with limited fine-tuning.
- The researchers propose the concept of a "heuristic core" - a set of learned features and behaviors that enable PLMs to perform well on a wide range of tasks.
- They investigate the properties of this heuristic core and how it contributes to the strong generalization capabilities of PLMs.
Plain English Explanation
Pretrained language models (PLMs) like BERT and GPT have shown remarkable performance on a wide variety of language tasks, even when only fine-tuned on a small amount of data. This paper tries to understand why these models are so capable of generalizing to new tasks and datasets.
The key idea is that PLMs develop a "heuristic core" - a set of fundamental skills and knowledge that allow them to perform well across many different applications. This heuristic core includes things like understanding the structure of language, recognizing common patterns, and drawing logical inferences. Even when the model is fine-tuned on a specific task, this heuristic core continues to provide a strong foundation for good performance.
The researchers investigate the properties of this heuristic core, exploring how it emerges during pretraining and how it contributes to the impressive generalization abilities of PLMs. By understanding the nature of the heuristic core, we can gain insights into why these models work so well and how we might be able to further improve their capabilities.
Technical Explanation
The paper begins by framing the problem of understanding the remarkable generalization abilities of pretrained language models (PLMs). The researchers note that even with limited fine-tuning, PLMs can achieve strong performance on a wide range of tasks and datasets. They propose the concept of a "heuristic core" - a set of learned features and behaviors that provide a foundation for this strong generalization.
To study the heuristic core, the authors design a series of experiments that analyze the inner workings of PLMs during fine-tuning. They measure properties like the stability of the model's internal representations, the importance of different layers, and the transferability of learned features. Through these analyses, they uncover key insights about the nature of the heuristic core and how it enables PLMs to generalize so effectively.
One key finding is that the heuristic core is largely preserved even as the model is fine-tuned on a specific task. The core representations and behaviors remain stable, acting as a strong starting point for the fine-tuning process. The authors also find that the heuristic core is distributed across multiple layers of the model, with different layers capturing different types of linguistic and reasoning capabilities.
Overall, this paper offers a novel and insightful perspective on the generalization abilities of PLMs. By proposing the concept of a heuristic core and carefully analyzing its properties, the researchers provide a deeper understanding of how these models work and why they are so effective at transferring knowledge to new tasks and datasets.
Critical Analysis
The paper provides a compelling and well-designed investigation into the nature of the heuristic core in pretrained language models. The experimental analyses offer valuable insights into the underlying mechanisms that enable strong generalization, and the authors do a good job of framing the problem and clearly communicating their findings.
That said, there are a few potential limitations and areas for further research that could be explored. For instance, the paper primarily focuses on understanding the heuristic core, but does not delve deeply into how this core is formed during pretraining. Investigating the learning dynamics and architectural choices that lead to the development of the heuristic core could yield additional insights.
Additionally, while the paper highlights the stability of the heuristic core during fine-tuning, it would be interesting to explore the limits of this stability. Under what conditions might the heuristic core break down or become less effective, and how might this inform our understanding of generalization in PLMs?
Finally, the paper focuses primarily on the generalization capabilities of PLMs, but does not examine the potential downsides or biases that may arise from over-relying on the heuristic core. Exploring these potential issues and considering how to mitigate them could be a fruitful area for future research.
Overall, this paper makes a valuable contribution to our understanding of pretrained language models and offers a novel perspective on the mechanisms underlying their impressive generalization abilities. The insights provided could help drive further advancements in language AI and inform the development of even more capable and robust models.
Conclusion
This paper introduces the concept of a "heuristic core" in pretrained language models (PLMs) and investigates its role in enabling strong generalization to new tasks and datasets. The researchers find that PLMs develop a set of fundamental linguistic and reasoning capabilities during pretraining, which then serve as a stable foundation for fine-tuning on specific applications.
By analyzing the properties of this heuristic core, the paper offers important insights into how PLMs are able to achieve such impressive performance with limited fine-tuning. The findings suggest that the heuristic core is distributed across multiple layers of the model and plays a crucial role in allowing these models to effectively transfer knowledge to new domains.
The insights provided in this paper could have significant implications for the future development of language AI systems. Understanding the nature of the heuristic core and how it contributes to generalization could inspire new architectural designs, pretraining strategies, and fine-tuning techniques to further enhance the capabilities of these powerful models. As the field of natural language processing continues to advance, research like this will be essential for unlocking the full potential of pretrained language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Learning Syntax Without Planting Trees: Understanding When and Why Transformers Generalize Hierarchically
Kabir Ahuja, Vidhisha Balachandran, Madhur Panwar, Tianxing He, Noah A. Smith, Navin Goyal, Yulia Tsvetkov
0
0
Transformers trained on natural language data have been shown to learn its hierarchical structure and generalize to sentences with unseen syntactic structures without explicitly encoding any structural bias. In this work, we investigate sources of inductive bias in transformer models and their training that could cause such generalization behavior to emerge. We extensively experiment with transformer models trained on multiple synthetic datasets and with different training objectives and show that while other objectives e.g. sequence-to-sequence modeling, prefix language modeling, often failed to lead to hierarchical generalization, models trained with the language modeling objective consistently learned to generalize hierarchically. We then conduct pruning experiments to study how transformers trained with the language modeling objective encode hierarchical structure. When pruned, we find joint existence of subnetworks within the model with different generalization behaviors (subnetworks corresponding to hierarchical structure and linear order). Finally, we take a Bayesian perspective to further uncover transformers' preference for hierarchical generalization: We establish a correlation between whether transformers generalize hierarchically on a dataset and whether the simplest explanation of that dataset is provided by a hierarchical grammar compared to regular grammars exhibiting linear generalization.
6/4/2024
🐍
A separability-based approach to quantifying generalization: which layer is best?
Luciano Dyballa, Evan Gerritz, Steven W. Zucker
0
0
Generalization to unseen data remains poorly understood for deep learning classification and foundation models. How can one assess the ability of networks to adapt to new or extended versions of their input space in the spirit of few-shot learning, out-of-distribution generalization, and domain adaptation? Which layers of a network are likely to generalize best? We provide a new method for evaluating the capacity of networks to represent a sampled domain, regardless of whether the network has been trained on all classes in the domain. Our approach is the following: after fine-tuning state-of-the-art pre-trained models for visual classification on a particular domain, we assess their performance on data from related but distinct variations in that domain. Generalization power is quantified as a function of the latent embeddings of unseen data from intermediate layers for both unsupervised and supervised settings. Working throughout all stages of the network, we find that (i) high classification accuracy does not imply high generalizability; and (ii) deeper layers in a model do not always generalize the best, which has implications for pruning. Since the trends observed across datasets are largely consistent, we conclude that our approach reveals (a function of) the intrinsic capacity of the different layers of a model to generalize.
5/6/2024
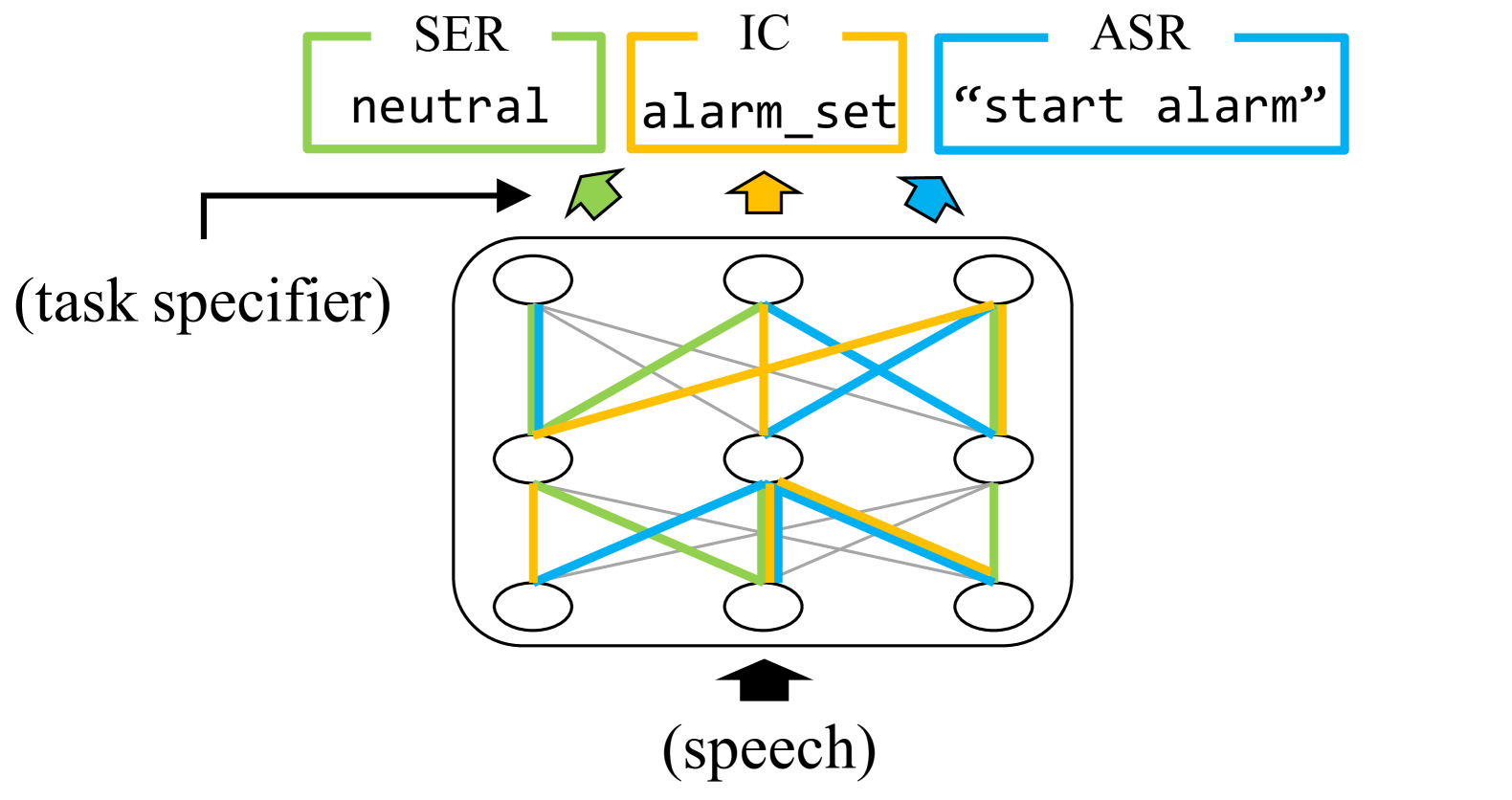
Finding Task-specific Subnetworks in Multi-task Spoken Language Understanding Model
Hayato Futami, Siddhant Arora, Yosuke Kashiwagi, Emiru Tsunoo, Shinji Watanabe
0
0
Recently, multi-task spoken language understanding (SLU) models have emerged, designed to address various speech processing tasks. However, these models often rely on a large number of parameters. Also, they often encounter difficulties in adapting to new data for a specific task without experiencing catastrophic forgetting of previously trained tasks. In this study, we propose finding task-specific subnetworks within a multi-task SLU model via neural network pruning. In addition to model compression, we expect that the forgetting of previously trained tasks can be mitigated by updating only a task-specific subnetwork. We conduct experiments on top of the state-of-the-art multi-task SLU model ``UniverSLU'', trained for several tasks such as emotion recognition (ER), intent classification (IC), and automatic speech recognition (ASR). We show that pruned models were successful in adapting to additional ASR or IC data with minimal performance degradation on previously trained tasks.
6/19/2024
🖼️
Attention as a Hypernetwork
Simon Schug, Seijin Kobayashi, Yassir Akram, Jo~ao Sacramento, Razvan Pascanu
0
0
Transformers can under some circumstances generalize to novel problem instances whose constituent parts might have been encountered during training but whose compositions have not. What mechanisms underlie this ability for compositional generalization? By reformulating multi-head attention as a hypernetwork, we reveal that a low-dimensional latent code specifies key-query specific operations. We find empirically that this latent code is highly structured, capturing information about the subtasks performed by the network. Using the framework of attention as a hypernetwork we further propose a simple modification of multi-head linear attention that strengthens the ability for compositional generalization on a range of abstract reasoning tasks. In particular, we introduce a symbolic version of the Raven Progressive Matrices human intelligence test on which we demonstrate how scaling model size and data enables compositional generalization and gives rise to a functionally structured latent code in the transformer.
6/24/2024