HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields

0

Sign in to get full access
Overview
- This paper introduces HFNeRF, a method for learning human biomechanical features using neural radiance fields (NeRFs).
- NeRFs are a powerful representation for modeling 3D scenes, but this work extends them to capture detailed human pose and shape information.
- The HFNeRF model can be used for applications like 3D character animation, virtual try-on, and mixed reality.
Plain English Explanation
The HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields paper describes a new way to capture detailed 3D information about the human body using an advanced deep learning technique called neural radiance fields (NeRFs).
NeRFs are a powerful way to model 3D scenes, but the researchers in this paper figured out how to use them specifically for modeling the human body. Their HFNeRF model can learn the exact shape, pose, and biomechanical features of a person from just a few camera images.
This has a lot of potential applications, like creating more realistic 3D avatars for video games or virtual try-on systems for online shopping. It could also help with mixed reality experiences, where digital characters need to seamlessly blend into the real world.
The key innovation is that HFNeRF can capture very fine-grained details about the human form, going beyond just the overall shape and pose. It learns the underlying biomechanical structure, which allows for more natural and lifelike animations.
Technical Explanation
The HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields model builds on the success of neural radiance fields (NeRFs) for 3D scene representation. However, instead of modeling a general 3D environment, the researchers adapted NeRFs to specialize in capturing the detailed geometry and appearance of the human body.
The core idea is to use a NeRF-based architecture that takes in not just the 3D position and viewing direction, but also parameters encoding the human pose and shape. This allows the model to learn a mapping from these high-level human biomechanical features to the actual 3D radiance field representing the person.
To train the HFNeRF model, the authors used a dataset of 3D human scans with corresponding camera images. By optimizing the NeRF to accurately reconstruct the observed images, the model is able to learn an internal representation that captures the key aspects of human form, including joint locations, muscle bulges, and other fine details.
The resulting HFNeRF model can then be used for a variety of applications. For example, it can be used to generate novel views of a person from arbitrary camera angles, enabling applications like virtual try-on and mixed reality. The model's understanding of human biomechanics also allows for more natural 3D character animation compared to traditional techniques.
Critical Analysis
The HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields paper presents a promising approach for modeling the human body in 3D using neural radiance fields. However, there are a few potential limitations and areas for future work:
-
The current model is trained on a relatively small dataset of 3D scans, which may limit its ability to generalize to the full diversity of human body shapes and poses. Scaling up the training data could help improve the model's robustness.
-
While the paper demonstrates the model's ability to capture fine-grained biomechanical details, it's unclear how well these features transfer to downstream applications like animation. Further evaluation is needed to assess the practical benefits.
-
The computational cost of running a full NeRF model at inference time may be prohibitive for some real-time applications. Techniques like neural feature compression or neural radiance field optimization could help improve the efficiency.
Overall, the HFNeRF represents an interesting step forward in human 3D modeling, but there is still room for improvement and further research to unlock its full potential, particularly in terms of generalization, efficiency, and practical applicability.
Conclusion
The HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields paper introduces a novel approach for modeling the human body in 3D using neural radiance fields. By encoding human pose and shape information directly into the NeRF representation, the HFNeRF model is able to capture detailed biomechanical features that could enable more realistic 3D character animation, virtual try-on, and mixed reality applications.
While the current model has some limitations in terms of data diversity and computational efficiency, the core idea of leveraging NeRFs for human 3D modeling is quite promising. Further research building on this work could lead to significant advancements in how we digitally represent the human form, with wide-ranging implications across industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HFNeRF: Learning Human Biomechanic Features with Neural Radiance Fields
Arnab Dey, Di Yang, Antitza Dantcheva, Jean Martinet
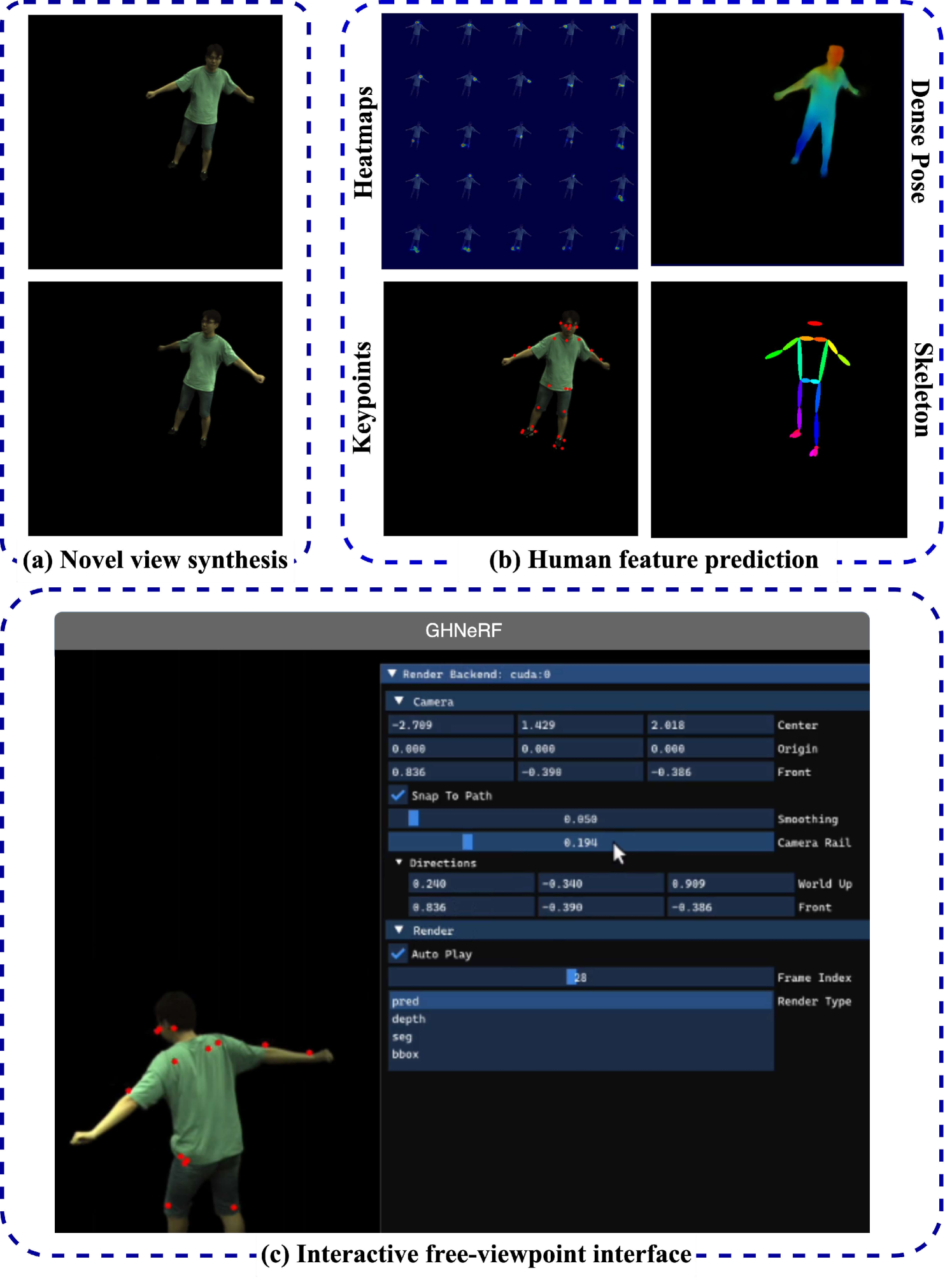
In recent advancements in novel view synthesis, generalizable Neural Radiance Fields (NeRF) based methods applied to human subjects have shown remarkable results in generating novel views from few images. However, this generalization ability cannot capture the underlying structural features of the skeleton shared across all instances. Building upon this, we introduce HFNeRF: a novel generalizable human feature NeRF aimed at generating human biomechanic features using a pre-trained image encoder. While previous human NeRF methods have shown promising results in the generation of photorealistic virtual avatars, such methods lack underlying human structure or biomechanic features such as skeleton or joint information that are crucial for downstream applications including Augmented Reality (AR)/Virtual Reality (VR). HFNeRF leverages 2D pre-trained foundation models toward learning human features in 3D using neural rendering, and then volume rendering towards generating 2D feature maps. We evaluate HFNeRF in the skeleton estimation task by predicting heatmaps as features. The proposed method is fully differentiable, allowing to successfully learn color, geometry, and human skeleton in a simultaneous manner. This paper presents preliminary results of HFNeRF, illustrating its potential in generating realistic virtual avatars with biomechanic features using NeRF.
Read more4/10/2024
0
GHNeRF: Learning Generalizable Human Features with Efficient Neural Radiance Fields
Arnab Dey, Di Yang, Rohith Agaram, Antitza Dantcheva, Andrew I. Comport, Srinath Sridhar, Jean Martinet
Recent advances in Neural Radiance Fields (NeRF) have demonstrated promising results in 3D scene representations, including 3D human representations. However, these representations often lack crucial information on the underlying human pose and structure, which is crucial for AR/VR applications and games. In this paper, we introduce a novel approach, termed GHNeRF, designed to address these limitations by learning 2D/3D joint locations of human subjects with NeRF representation. GHNeRF uses a pre-trained 2D encoder streamlined to extract essential human features from 2D images, which are then incorporated into the NeRF framework in order to encode human biomechanic features. This allows our network to simultaneously learn biomechanic features, such as joint locations, along with human geometry and texture. To assess the effectiveness of our method, we conduct a comprehensive comparison with state-of-the-art human NeRF techniques and joint estimation algorithms. Our results show that GHNeRF can achieve state-of-the-art results in near real-time.
Read more4/10/2024
![Neural radiance fields-based holography [Invited]](https://arxiv.org/html/2403.01137v1/extracted/5444105/fig_outline.jpg)
0
Neural radiance fields-based holography [Invited]
Minsung Kang, Fan Wang, Kai Kumano, Tomoyoshi Ito, Tomoyoshi Shimobaba
This study presents a novel approach for generating holograms based on the neural radiance fields (NeRF) technique. Generating three-dimensional (3D) data is difficult in hologram computation. NeRF is a state-of-the-art technique for 3D light-field reconstruction from 2D images based on volume rendering. The NeRF can rapidly predict new-view images that do not include a training dataset. In this study, we constructed a rendering pipeline directly from a 3D light field generated from 2D images by NeRF for hologram generation using deep neural networks within a reasonable time. The pipeline comprises three main components: the NeRF, a depth predictor, and a hologram generator, all constructed using deep neural networks. The pipeline does not include any physical calculations. The predicted holograms of a 3D scene viewed from any direction were computed using the proposed pipeline. The simulation and experimental results are presented.
Read more5/13/2024

0
TalkinNeRF: Animatable Neural Fields for Full-Body Talking Humans
Aggelina Chatziagapi, Bindita Chaudhuri, Amit Kumar, Rakesh Ranjan, Dimitris Samaras, Nikolaos Sarafianos
We introduce a novel framework that learns a dynamic neural radiance field (NeRF) for full-body talking humans from monocular videos. Prior work represents only the body pose or the face. However, humans communicate with their full body, combining body pose, hand gestures, as well as facial expressions. In this work, we propose TalkinNeRF, a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result. To capture complex finger articulation, we learn an additional deformation field for the hands. Our multi-identity representation enables simultaneous training for multiple subjects, as well as robust animation under completely unseen poses. It can also generalize to novel identities, given only a short video as input. We demonstrate state-of-the-art performance for animating full-body talking humans, with fine-grained hand articulation and facial expressions.
Read more9/26/2024