Hierarchical Associative Memory, Parallelized MLP-Mixer, and Symmetry Breaking

0

Sign in to get full access
Overview
- This paper explores three interconnected topics: Hierarchical Associative Memory, Parallelized MLP-Mixer, and Symmetry Breaking.
- It proposes novel approaches and insights in these areas, with potential implications for improving the performance and understanding of transformer-based models.
Plain English Explanation
The paper delves into the complex world of transformer-based machine learning models, exploring ways to enhance their capabilities and gain a deeper understanding of how they work.
One key focus is on Hierarchical Associative Memory, which aims to mimic the way the human brain stores and retrieves information. By organizing knowledge in a hierarchical structure, the researchers believe this approach could lead to more efficient and robust models.
Another area of focus is Parallelized MLP-Mixer, a novel architecture that combines the strengths of multi-layer perceptrons (MLPs) and transformer models. This hybrid approach could potentially unlock new performance gains and computational efficiencies.
The paper also investigates the phenomenon of Symmetry Breaking, which is crucial for transformer models to learn meaningful representations. By understanding and leveraging this concept, the researchers hope to further advance the capabilities of these powerful AI systems.
Throughout the paper, the authors draw insights from related fields, such as neuroscience and optimization theory, to push the boundaries of what's possible in the realm of transformer-based machine learning.
Technical Explanation
The paper begins by exploring the concept of Hierarchical Associative Memory, which draws inspiration from the way the human brain stores and retrieves information. The researchers propose a novel architecture that organizes knowledge hierarchically, allowing for more efficient and robust information processing. This approach could potentially lead to improved performance in tasks that require complex reasoning and knowledge representation.
Next, the paper introduces the Parallelized MLP-Mixer, a hybrid architecture that combines the strengths of multi-layer perceptrons (MLPs) and transformer models. By parallelizing the MLP components, the researchers aim to unlock new performance gains and computational efficiencies, potentially making transformer-based models more accessible and practical for a wider range of applications.
The paper also delves into the topic of Symmetry Breaking, which is crucial for transformer models to learn meaningful representations. By understanding and leveraging this concept, the authors believe they can further advance the capabilities of these powerful AI systems, enabling them to better capture the underlying structure and patterns in complex data.
Throughout the paper, the researchers draw insights from related fields, such as neuroscience and optimization theory, to inform their approaches and gain a deeper understanding of the fundamental principles underlying transformer-based models.
Critical Analysis
The paper presents a series of innovative ideas and approaches that have the potential to significantly advance the field of transformer-based machine learning. However, as with any research, there are some caveats and limitations that merit consideration.
One potential concern is the practical implementation and scalability of the proposed Hierarchical Associative Memory and Parallelized MLP-Mixer architectures. While the theoretical foundations seem promising, the authors acknowledge the need for further empirical evaluation to assess their performance and computational efficiency in real-world scenarios.
Additionally, the paper's discussion of Symmetry Breaking provides valuable insights, but the researchers acknowledge that more work is needed to fully understand the underlying mechanisms and their implications for transformer model design and optimization.
Further research and experimentation will be crucial to validate the proposed ideas, explore their broader implications, and address any potential limitations or challenges that may emerge. Engaging with the wider research community and incorporating diverse perspectives could also help to refine and strengthen the proposed approaches.
Conclusion
This paper presents a multifaceted exploration of key topics in the realm of transformer-based machine learning, including Hierarchical Associative Memory, Parallelized MLP-Mixer, and Symmetry Breaking. The researchers have put forth innovative ideas and approaches that have the potential to significantly advance the field, offering new paths for improving the performance, robustness, and understanding of these powerful AI systems.
While the paper raises several thought-provoking concepts, it also acknowledges the need for further research and validation. By continuing to build upon these foundations and collaborating with the broader research community, the insights gained from this work could pave the way for transformative advancements in the field of machine learning and artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Associative Memory, Parallelized MLP-Mixer, and Symmetry Breaking
Ryo Karakida, Toshihiro Ota, Masato Taki
Transformers have established themselves as the leading neural network model in natural language processing and are increasingly foundational in various domains. In vision, the MLP-Mixer model has demonstrated competitive performance, suggesting that attention mechanisms might not be indispensable. Inspired by this, recent research has explored replacing attention modules with other mechanisms, including those described by MetaFormers. However, the theoretical framework for these models remains underdeveloped. This paper proposes a novel perspective by integrating Krotov's hierarchical associative memory with MetaFormers, enabling a comprehensive representation of the entire Transformer block, encompassing token-/channel-mixing modules, layer normalization, and skip connections, as a single Hopfield network. This approach yields a parallelized MLP-Mixer derived from a three-layer Hopfield network, which naturally incorporates symmetric token-/channel-mixing modules and layer normalization. Empirical studies reveal that symmetric interaction matrices in the model hinder performance in image recognition tasks. Introducing symmetry-breaking effects transitions the performance of the symmetric parallelized MLP-Mixer to that of the vanilla MLP-Mixer. This indicates that during standard training, weight matrices of the vanilla MLP-Mixer spontaneously acquire a symmetry-breaking configuration, enhancing their effectiveness. These findings offer insights into the intrinsic properties of Transformers and MLP-Mixers and their theoretical underpinnings, providing a robust framework for future model design and optimization.
Read more6/19/2024

0
MetaMixer Is All You Need
Seokju Yun, Dongheon Lee, Youngmin Ro
Transformer, composed of self-attention and Feed-Forward Network, has revolutionized the landscape of network design across various vision tasks. FFN is a versatile operator seamlessly integrated into nearly all AI models to effectively harness rich representations. Recent works also show that FFN functions like key-value memories. Thus, akin to the query-key-value mechanism within self-attention, FFN can be viewed as a memory network, where the input serves as query and the two projection weights operate as keys and values, respectively. We hypothesize that the importance lies in query-key-value framework itself rather than in self-attention. To verify this, we propose converting self-attention into a more FFN-like efficient token mixer with only convolutions while retaining query-key-value framework, namely FFNification. Specifically, FFNification replaces query-key and attention coefficient-value interactions with large kernel convolutions and adopts GELU activation function instead of softmax. The derived token mixer, FFNified attention, serves as key-value memories for detecting locally distributed spatial patterns, and operates in the opposite dimension to the ConvNeXt block within each corresponding sub-operation of the query-key-value framework. Building upon the above two modules, we present a family of Fast-Forward Networks. Our FFNet achieves remarkable performance improvements over previous state-of-the-art methods across a wide range of tasks. The strong and general performance of our proposed method validates our hypothesis and leads us to introduce MetaMixer, a general mixer architecture that does not specify sub-operations within the query-key-value framework. We show that using only simple operations like convolution and GELU in the MetaMixer can achieve superior performance.
Read more6/5/2024
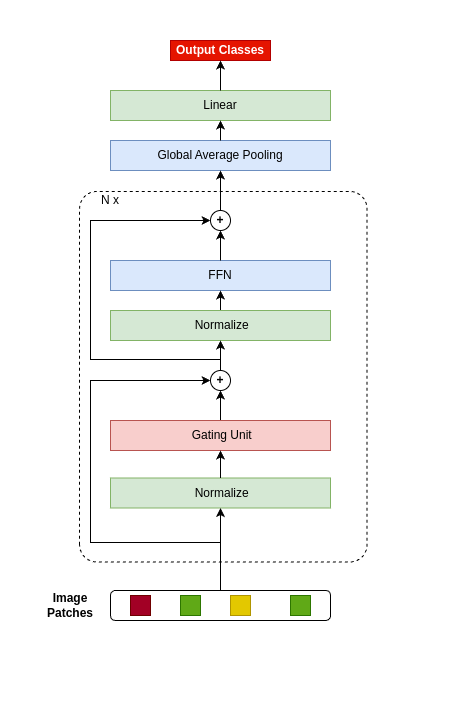
0
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Abdullah Nazhat Abdullah, Tarkan Aydin
The attention mechanism is the main component of the transformer architecture, and since its introduction, it has led to significant advancements in deep learning that span many domains and multiple tasks. The attention mechanism was utilized in computer vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal attention layers with a Network in Network structure that enhances the static approach of the MLP-Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
Read more6/17/2024

0
Masked Mixers for Language Generation and Retrieval
Benjamin L. Badger
Attention mechanisms that confer selective focus on a strict subset of input elements are nearly ubiquitous in language models today. We posit there to be downside to the use of attention: most information present in the input is necessarily lost. In support of this idea we observe poor input representation accuracy in transformers, but find more accurate representation in what we term masked mixers which replace self-attention with masked convolutions. Applied to TinyStories the masked mixer learns causal language tasks more efficiently than early transformer implementations and somewhat less efficiently than optimized, current implementations. The most efficient learning algorithm observed for this dataset is a transformer-masked mixer hybrid, suggesting that these models learn in an orthogonal manner. We hypothesized that the information loss exhibited by transformers would be much more detrimental to retrieval than generation, and to test this we introduce an efficient training approach for retrieval models based on existing generative model embeddings. With this method, embeddings from masked mixers are found to result in far better summary-to-story retrieval compared to embeddings from transformers.
Read more9/4/2024