Hierarchical Hypercomplex Network for Multimodal Emotion Recognition

0

Sign in to get full access
Overview
- This paper presents a "Hierarchical Hypercomplex Network" for multimodal emotion recognition.
- The model integrates visual, audio, and text modalities to recognize complex emotional states.
- The hierarchical architecture captures both low-level features and high-level interactions between modalities.
- Experiments show the model outperforms previous state-of-the-art approaches on benchmark emotion recognition tasks.
Plain English Explanation
The paper introduces a new artificial intelligence (AI) model called the "Hierarchical Hypercomplex Network" that is designed to recognize human emotions from multiple sources of information. Emotion recognition is an important task for applications like social robots, mental health monitoring, and human-computer interaction.
Typically, emotion recognition models focus on a single type of data, like facial expressions or speech. However, humans express emotion through a combination of visual, auditory, and linguistic cues. The Hierarchical Hypercomplex Network aims to capture this multimodal nature of emotion by integrating features from different data sources.
The model has a hierarchical architecture, which means it processes information at multiple levels of abstraction. At the lower levels, it extracts basic visual, audio, and textual features. At the higher levels, it learns how these lower-level features interact to represent more complex emotional states. This hierarchical design allows the model to build a rich, comprehensive understanding of emotion.
The researchers tested the Hierarchical Hypercomplex Network on standard emotion recognition benchmarks and found that it outperformed previous state-of-the-art approaches. This suggests the model is a promising tool for applications that require accurate and nuanced emotion recognition.
Technical Explanation
The Hierarchical Hypercomplex Network consists of three main components: a Visual Hypercomplex Network, an Audio Hypercomplex Network, and a Text Hypercomplex Network.
Each of these modality-specific networks uses a hierarchical structure to extract features at multiple levels of abstraction. The lower levels process raw input data, while the higher levels learn complex representations by modeling interactions between the modalities.
The output features from the three modality networks are then fused using a Multimodal Fusion Module to produce a final emotion prediction. The fusion module learns to optimally combine the multidimensional features from each modality.
The researchers evaluate their Hierarchical Hypercomplex Network on several emotion recognition benchmarks, including the IEMOCAP and MELD datasets. They demonstrate state-of-the-art performance, outperforming previous unimodal and multimodal emotion recognition approaches.
Critical Analysis
The paper provides a comprehensive technical description of the Hierarchical Hypercomplex Network and presents strong empirical results. However, there are a few potential areas for improvement or further exploration:
-
Interpretability: While the hierarchical architecture is designed to capture complex multimodal interactions, it may be challenging to interpret the model's internal representations and understand how it arrives at its emotion predictions. Improving the interpretability of the model could enhance its real-world applicability.
-
Robustness: The paper does not explore the model's robustness to noisy or incomplete input data, which is an important consideration for practical emotion recognition systems. Further testing of the model's performance under more realistic, challenging conditions would be valuable.
-
Ethical Considerations: Emotion recognition technology, if deployed without appropriate safeguards, raises potential ethical concerns around privacy, bias, and the use of personal data. The paper does not discuss these important issues, which should be addressed as the technology matures.
-
Generalization: The experiments focus on a limited set of emotion recognition benchmarks. Evaluating the model's performance on a more diverse range of datasets and real-world applications would help demonstrate its broader applicability.
Overall, the Hierarchical Hypercomplex Network represents an innovative and promising approach to multimodal emotion recognition. Addressing the points raised above could further strengthen the research and prepare the model for real-world deployment.
Conclusion
The "Hierarchical Hypercomplex Network" presented in this paper is a novel AI model that excels at recognizing human emotions by integrating visual, auditory, and textual information. Its hierarchical architecture allows it to capture both low-level features and high-level interactions between modalities, resulting in state-of-the-art performance on standard emotion recognition benchmarks.
This research contributes to the field of multimodal affective computing, which aims to develop advanced emotion recognition systems. Such systems have various applications, including social robotics, mental health monitoring, and human-computer interaction. By considering multiple channels of emotional expression, the Hierarchical Hypercomplex Network represents an important step towards more comprehensive and reliable emotion recognition technologies.
While the paper demonstrates the model's strong performance, further research is needed to address issues like interpretability, robustness, and ethical considerations. Nonetheless, this work highlights the potential of combining hierarchical and hypercomplex architectures for multimodal perception and understanding, which could have far-reaching implications for the development of more natural and empathetic AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Hierarchical Hypercomplex Network for Multimodal Emotion Recognition
Eleonora Lopez, Aurelio Uncini, Danilo Comminiello
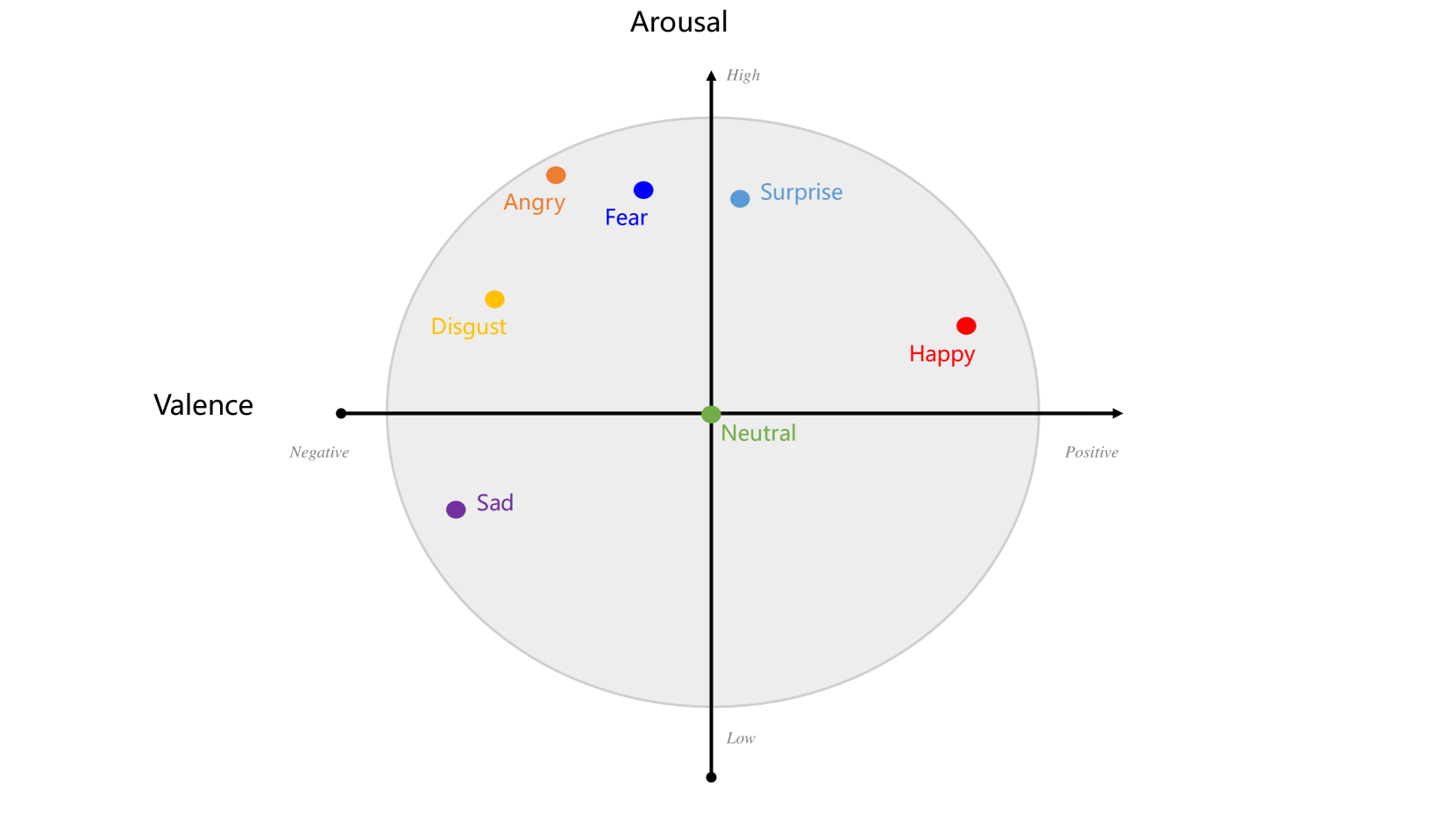
Emotion recognition is relevant in various domains, ranging from healthcare to human-computer interaction. Physiological signals, being beyond voluntary control, offer reliable information for this purpose, unlike speech and facial expressions which can be controlled at will. They reflect genuine emotional responses, devoid of conscious manipulation, thereby enhancing the credibility of emotion recognition systems. Nonetheless, multimodal emotion recognition with deep learning models remains a relatively unexplored field. In this paper, we introduce a fully hypercomplex network with a hierarchical learning structure to fully capture correlations. Specifically, at the encoder level, the model learns intra-modal relations among the different channels of each input signal. Then, a hypercomplex fusion module learns inter-modal relations among the embeddings of the different modalities. The main novelty is in exploiting intra-modal relations by endowing the encoders with parameterized hypercomplex convolutions (PHCs) that thanks to hypercomplex algebra can capture inter-channel interactions within single modalities. Instead, the fusion module comprises parameterized hypercomplex multiplications (PHMs) that can model inter-modal correlations. The proposed architecture surpasses state-of-the-art models on the MAHNOB-HCI dataset for emotion recognition, specifically in classifying valence and arousal from electroencephalograms (EEGs) and peripheral physiological signals. The code of this study is available at https://github.com/ispamm/MHyEEG.
Read more9/17/2024
0
Temporal Label Hierachical Network for Compound Emotion Recognition
Sunan Li, Hailun Lian, Cheng Lu, Yan Zhao, Tianhua Qi, Hao Yang, Yuan Zong, Wenming Zheng
The emotion recognition has attracted more attention in recent decades. Although significant progress has been made in the recognition technology of the seven basic emotions, existing methods are still hard to tackle compound emotion recognition that occurred commonly in practical application. This article introduces our achievements in the 7th Field Emotion Behavior Analysis (ABAW) competition. In the competition, we selected pre trained ResNet18 and Transformer, which have been widely validated, as the basic network framework. Considering the continuity of emotions over time, we propose a time pyramid structure network for frame level emotion prediction. Furthermore. At the same time, in order to address the lack of data in composite emotion recognition, we utilized fine-grained labels from the DFEW database to construct training data for emotion categories in competitions. Taking into account the characteristics of valence arousal of various complex emotions, we constructed a classification framework from coarse to fine in the label space.
Read more7/19/2024
🌐
0
Multi-scale Transformer-based Network for Emotion Recognition from Multi Physiological Signals
Tu Vu, Van Thong Huynh, Soo-Hyung Kim
This paper presents an efficient Multi-scale Transformer-based approach for the task of Emotion recognition from Physiological data, which has gained widespread attention in the research community due to the vast amount of information that can be extracted from these signals using modern sensors and machine learning techniques. Our approach involves applying a Multi-modal technique combined with scaling data to establish the relationship between internal body signals and human emotions. Additionally, we utilize Transformer and Gaussian Transformation techniques to improve signal encoding effectiveness and overall performance. Our model achieves decent results on the CASE dataset of the EPiC competition, with an RMSE score of 1.45.
Read more7/19/2024

0
Multimodal Fusion via Hypergraph Autoencoder and Contrastive Learning for Emotion Recognition in Conversation
Zijian Yi, Ziming Zhao, Zhishu Shen, Tiehua Zhang
Multimodal emotion recognition in conversation (MERC) seeks to identify the speakers' emotions expressed in each utterance, offering significant potential across diverse fields. The challenge of MERC lies in balancing speaker modeling and context modeling, encompassing both long-distance and short-distance contexts, as well as addressing the complexity of multimodal information fusion. Recent research adopts graph-based methods to model intricate conversational relationships effectively. Nevertheless, the majority of these methods utilize a fixed fully connected structure to link all utterances, relying on convolution to interpret complex context. This approach can inherently heighten the redundancy in contextual messages and excessive graph network smoothing, particularly in the context of long-distance conversations. To address this issue, we propose a framework that dynamically adjusts hypergraph connections by variational hypergraph autoencoder (VHGAE), and employs contrastive learning to mitigate uncertainty factors during the reconstruction process. Experimental results demonstrate the effectiveness of our proposal against the state-of-the-art methods on IEMOCAP and MELD datasets. We release the code to support the reproducibility of this work at https://github.com/yzjred/-HAUCL.
Read more8/6/2024