Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification

0

Sign in to get full access
Overview
- Presents a hierarchical multi-modal transformer architecture for cross-modal long document classification
- Introduces a dynamic multi-scale multi-modal transformer and a dynamic mask transfer mechanism to effectively process long, multi-modal documents
- Achieves state-of-the-art performance on several long document classification benchmarks
Plain English Explanation
The paper describes a new approach to classifying long documents that contain both text and images. Traditional machine learning models can struggle with long documents, as they may miss important information spread across the text and images.
The Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification aims to address this challenge by using a multi-stage transformer model. This model first processes the text and images separately, then combines them to understand the full context of the document.
A key innovation is the "dynamic multi-scale multi-modal transformer," which can adaptively focus on different parts of the document at different levels of detail. This allows the model to grasp the overall meaning while also picking up on important nuances. The "dynamic mask transfer" mechanism further improves performance by transferring relevant information between the text and image processing stages.
Overall, this work demonstrates how advanced multi-modal deep learning techniques can be used to tackle the challenge of understanding long, complex documents that contain both text and images. The results show significant improvements over previous approaches on several benchmark tasks.
Technical Explanation
The Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification introduces a novel architecture for classifying long documents with both text and images.
The core components are:
-
Hierarchical Multi-modal Transformer: This model first processes the text and images separately using transformer encoders. It then combines the text and image representations using another transformer layer to capture cross-modal interactions.
-
Dynamic Multi-scale Multi-modal Transformer: This module adaptively focuses on different parts of the document at multiple scales, allowing the model to grasp both high-level and low-level details.
-
Dynamic Mask Transfer: This mechanism transfers relevant information between the text and image processing stages, further improving performance on the classification task.
The authors evaluate their approach on several long document classification benchmarks, including Multimodal Metadata Assignment for Cultural Heritage Artifacts, Finding and Editing Multi-modal Neurons in Pre-trained Models, and Robust Latent Representation Tuning for Image-Text Classification. The results demonstrate significant improvements over previous state-of-the-art approaches, highlighting the effectiveness of the proposed hierarchical and multi-scale multi-modal transformer architecture.
Critical Analysis
The paper presents a well-designed and thorough approach to cross-modal long document classification. The key innovations, such as the dynamic multi-scale multi-modal transformer and the dynamic mask transfer mechanism, seem well-motivated and effective based on the reported results.
However, the paper does not extensively discuss potential limitations or future research directions. For example, it would be interesting to understand how the model performs on documents with more complex or noisier multimodal data, or how it could be extended to handle other types of long-form content beyond just documents (e.g., Advanced Multimodal Deep Learning Architecture for Image and Text).
Additionally, while the experiments demonstrate strong performance on benchmark datasets, it would be valuable to see the model applied to real-world, high-stakes applications to better understand its practical implications and potential limitations.
Overall, the Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification is a promising contribution to the field of multimodal machine learning, but there is still room for further exploration and validation of the approach.
Conclusion
The Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification presents an innovative deep learning architecture for classifying long documents with both text and images. By introducing a hierarchical, multi-scale, and cross-modal transformer design, the authors demonstrate significant improvements over previous state-of-the-art methods on several benchmarks.
This work highlights the potential of advanced multimodal deep learning techniques to tackle the challenge of understanding complex, long-form content that combines different modalities. As the volume and complexity of digital information continue to grow, tools like the one presented in this paper will become increasingly important for a wide range of applications, from content management to knowledge discovery.
While the paper does not extensively address the limitations or future research directions, it represents a promising step forward in the field of multimodal machine learning and long document understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Multi-modal Transformer for Cross-modal Long Document Classification
Tengfei Liu, Yongli Hu, Junbin Gao, Yanfeng Sun, Baocai Yin
Long Document Classification (LDC) has gained significant attention recently. However, multi-modal data in long documents such as texts and images are not being effectively utilized. Prior studies in this area have attempted to integrate texts and images in document-related tasks, but they have only focused on short text sequences and images of pages. How to classify long documents with hierarchical structure texts and embedding images is a new problem and faces multi-modal representation difficulties. In this paper, we propose a novel approach called Hierarchical Multi-modal Transformer (HMT) for cross-modal long document classification. The HMT conducts multi-modal feature interaction and fusion between images and texts in a hierarchical manner. Our approach uses a multi-modal transformer and a dynamic multi-scale multi-modal transformer to model the complex relationships between image features, and the section and sentence features. Furthermore, we introduce a new interaction strategy called the dynamic mask transfer module to integrate these two transformers by propagating features between them. To validate our approach, we conduct cross-modal LDC experiments on two newly created and two publicly available multi-modal long document datasets, and the results show that the proposed HMT outperforms state-of-the-art single-modality and multi-modality methods.
Read more7/16/2024

0
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
Xidong Wang, Dingjie Song, Shunian Chen, Chen Zhang, Benyou Wang
Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is crucial for video understanding, high-resolution image understanding, and multi-modal agents. This involves a series of systematic optimizations, including model architecture, data construction and training strategy, particularly addressing challenges such as textit{degraded performance with more images} and textit{high computational costs}. In this paper, we adapt the model architecture to a hybrid of Mamba and Transformer blocks, approach data construction with both temporal and spatial dependencies among multiple images and employ a progressive training strategy. The released model textbf{LongLLaVA}~(textbf{Long}-Context textbf{L}arge textbf{L}anguage textbf{a}nd textbf{V}ision textbf{A}ssistant) is the first hybrid MLLM, which achieved a better balance between efficiency and effectiveness. LongLLaVA not only achieves competitive results across various benchmarks, but also maintains high throughput and low memory consumption. Especially, it could process nearly a thousand images on a single A100 80GB GPU, showing promising application prospects for a wide range of tasks.
Read more9/5/2024
0
HSVLT: Hierarchical Scale-Aware Vision-Language Transformer for Multi-Label Image Classification
Shuyi Ouyang, Hongyi Wang, Ziwei Niu, Zhenjia Bai, Shiao Xie, Yingying Xu, Ruofeng Tong, Yen-Wei Chen, Lanfen Lin
The task of multi-label image classification involves recognizing multiple objects within a single image. Considering both valuable semantic information contained in the labels and essential visual features presented in the image, tight visual-linguistic interactions play a vital role in improving classification performance. Moreover, given the potential variance in object size and appearance within a single image, attention to features of different scales can help to discover possible objects in the image. Recently, Transformer-based methods have achieved great success in multi-label image classification by leveraging the advantage of modeling long-range dependencies, but they have several limitations. Firstly, existing methods treat visual feature extraction and cross-modal fusion as separate steps, resulting in insufficient visual-linguistic alignment in the joint semantic space. Additionally, they only extract visual features and perform cross-modal fusion at a single scale, neglecting objects with different characteristics. To address these issues, we propose a Hierarchical Scale-Aware Vision-Language Transformer (HSVLT) with two appealing designs: (1)~A hierarchical multi-scale architecture that involves a Cross-Scale Aggregation module, which leverages joint multi-modal features extracted from multiple scales to recognize objects of varying sizes and appearances in images. (2)~Interactive Visual-Linguistic Attention, a novel attention mechanism module that tightly integrates cross-modal interaction, enabling the joint updating of visual, linguistic and multi-modal features. We have evaluated our method on three benchmark datasets. The experimental results demonstrate that HSVLT surpasses state-of-the-art methods with lower computational cost.
Read more7/24/2024
60
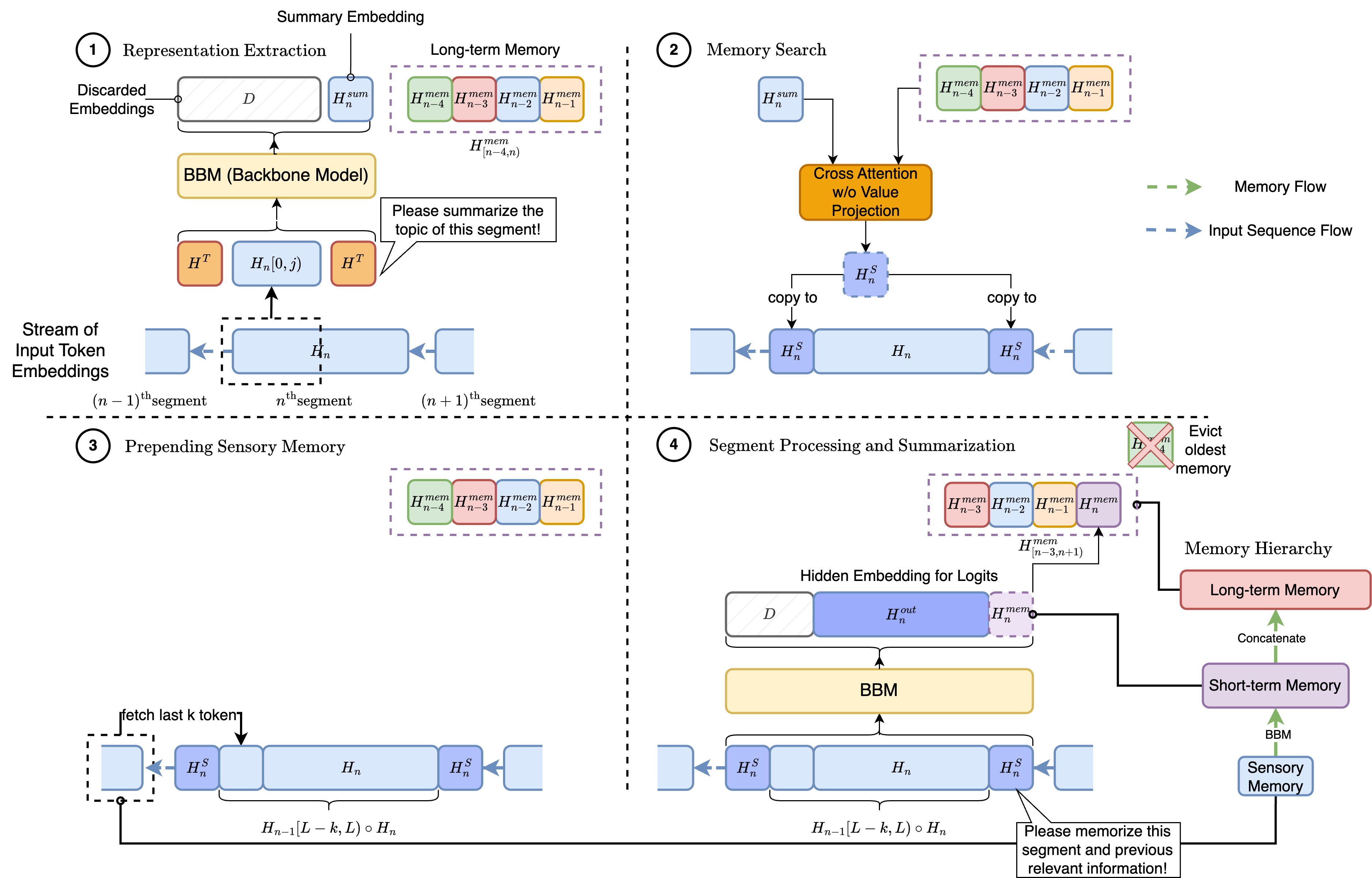
HMT: Hierarchical Memory Transformer for Long Context Language Processing
Zifan He, Zongyue Qin, Neha Prakriya, Yizhou Sun, Jason Cong
Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have flat memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.
Read more5/15/2024