HMT: Hierarchical Memory Transformer for Long Context Language Processing
2405.06067
87
0
Abstract
Transformer-based large language models (LLM) have been widely used in language processing applications. However, most of them restrict the context window that permits the model to attend to every token in the inputs. Previous works in recurrent models can memorize past tokens to enable unlimited context and maintain effectiveness. However, they have flat memory architectures, which have limitations in selecting and filtering information. Since humans are good at learning and self-adjustment, we speculate that imitating brain memory hierarchy is beneficial for model memorization. We propose the Hierarchical Memory Transformer (HMT), a novel framework that enables and improves models' long-context processing ability by imitating human memorization behavior. Leveraging memory-augmented segment-level recurrence, we organize the memory hierarchy by preserving tokens from early input token segments, passing memory embeddings along the sequence, and recalling relevant information from history. Evaluating general language modeling (Wikitext-103, PG-19) and question-answering tasks (PubMedQA), we show that HMT steadily improves the long-context processing ability of context-constrained and long-context models. With an additional 0.5% - 2% of parameters, HMT can easily plug in and augment future LLMs to handle long context effectively. Our code is open-sourced on Github: https://github.com/OswaldHe/HMT-pytorch.
Create account to get full access
Overview
- This paper introduces the Hierarchical Memory Transformer (HMT), a novel language model architecture designed for processing long-form text and dialog.
- HMT employs a hierarchical memory structure to better capture and utilize contextual information across different levels of granularity.
- The model is evaluated on various long-context language understanding tasks and shows improved performance compared to previous state-of-the-art methods.
Plain English Explanation
The Hierarchical Memory Transformer (HMT) is a new type of language model that is better at understanding long passages of text or multi-turn conversations. Traditional language models can struggle with keeping track of all the relevant context when processing lengthy inputs.
HMT addresses this by using a "hierarchical memory" - it stores information at different levels of detail, from broad themes down to specific details. This allows the model to efficiently access and combine relevant context from various scales as needed, rather than trying to remember everything at once.
For example, when reading a long document, HMT can maintain a high-level summary of the main topics, while also holding onto important low-level facts and details. This gives it a more complete understanding of the text compared to models that can only focus on the immediate words and sentences.
The researchers tested HMT on several benchmark tasks that require understanding long-form language, and found it outperformed other state-of-the-art models. This suggests the hierarchical memory approach is a promising direction for building more capable language AI systems that can better comprehend extended contexts.
Technical Explanation
The core innovation of the Hierarchical Memory Transformer (HMT) is its hierarchical memory structure, which aims to more effectively capture and utilize contextual information across different levels of granularity.
Unlike standard Transformer models that maintain a single context vector, HMT maintains a hierarchy of context representations at different scales. This includes a high-level summary, mid-level segment embeddings, and low-level token embeddings. These levels of context are dynamically combined as needed by the model during processing.
The hierarchical memory is implemented using a series of recurrent and attentional modules. The segment-level recurrence mechanism maintains persistent memory across input segments, while the memory sharing and context merging components allow relevant contextual information to flow between the different memory levels.
The hierarchical design is inspired by insights from human memory and aims to provide a more efficient and effective way for large language models to reason about and retain long-range contexts.
The researchers evaluate HMT on a variety of long-context language understanding benchmarks, including document-level question answering, dialogue state tracking, and multi-document summarization. HMT demonstrates consistent performance improvements over previous state-of-the-art models, highlighting the value of its hierarchical memory architecture.
Critical Analysis
The Hierarchical Memory Transformer (HMT) presents a novel and promising approach to improving long-context language understanding in large language models. The hierarchical memory structure seems well-motivated by insights from human cognition, and the empirical results on benchmark tasks are impressive.
However, the paper does not provide a deep analysis of the inner workings and limitations of the HMT architecture. For example, it is unclear how the different memory levels interact and how the model learns to effectively combine them. More investigation is needed to fully understand the model's strengths and weaknesses.
Additionally, the paper focuses on standard natural language processing tasks and does not explore the potential of HMT for more open-ended, multi-modal, or grounded language understanding. It would be valuable to see how the hierarchical memory approach generalizes to these more challenging domains.
Further research is also needed to better understand the computational and memory efficiency of HMT compared to other long-range context modeling techniques, such as L2MAC. As language models continue to grow in scale and complexity, the ability to effectively manage and leverage long-term context will be crucial.
Conclusion
The Hierarchical Memory Transformer (HMT) represents an important step forward in developing language models that can better understand and reason about long-form text and dialog. By introducing a hierarchical memory structure, the model is able to more efficiently capture and utilize relevant contextual information across different levels of granularity.
The promising results on benchmark tasks suggest that the hierarchical memory approach is a valuable direction for advancing the state of the art in long-context language processing. As language models continue to grow in scale and ambition, techniques like HMT will be essential for enabling more powerful and versatile natural language understanding capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Woomin Song, Seunghyuk Oh, Sangwoo Mo, Jaehyung Kim, Sukmin Yun, Jung-Woo Ha, Jinwoo Shin
0
0
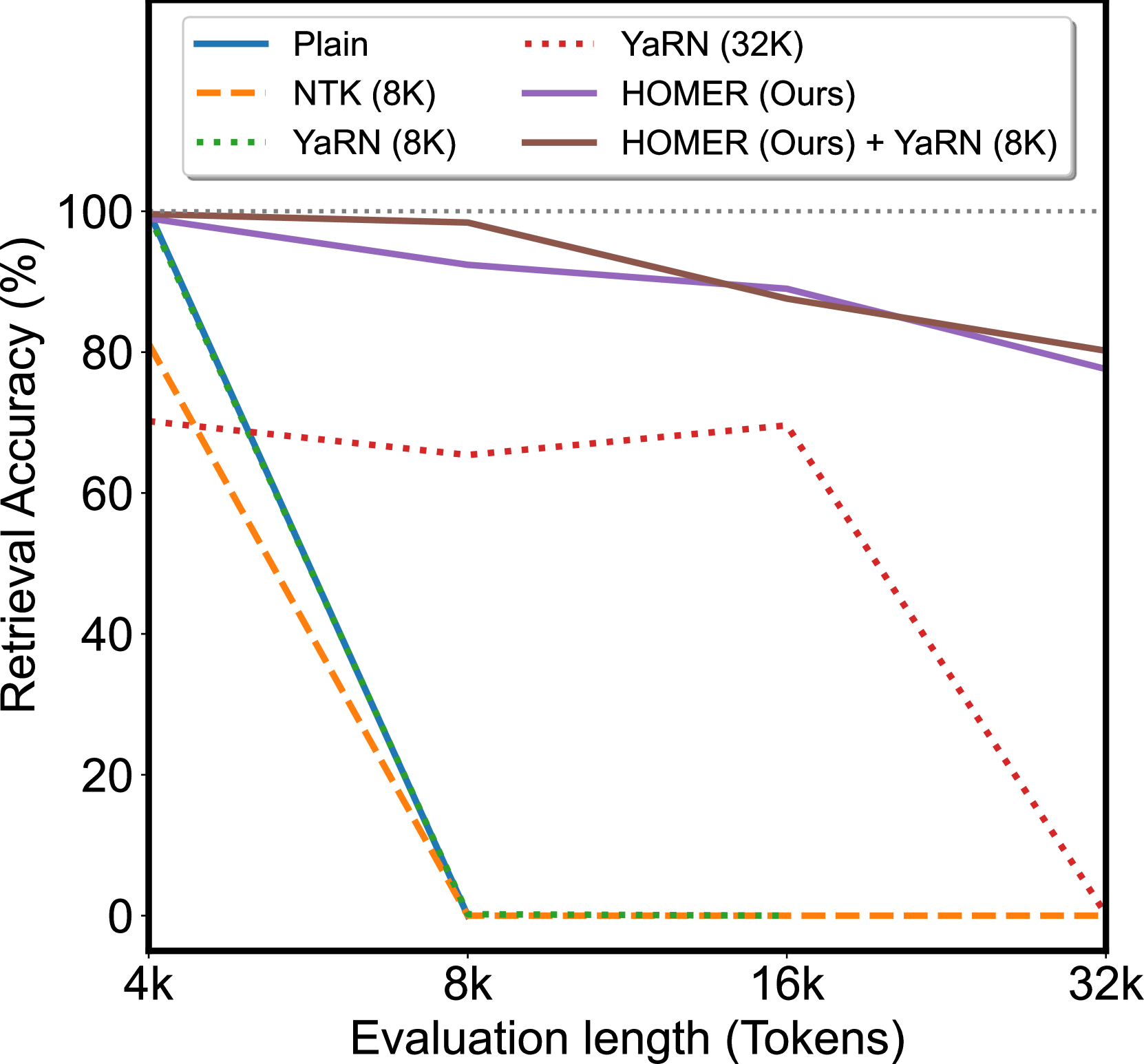
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.
4/17/2024
Enhancing Long-Term Memory using Hierarchical Aggregate Tree for Retrieval Augmented Generation
Aadharsh Aadhithya A, Sachin Kumar S, Soman K. P
0
0
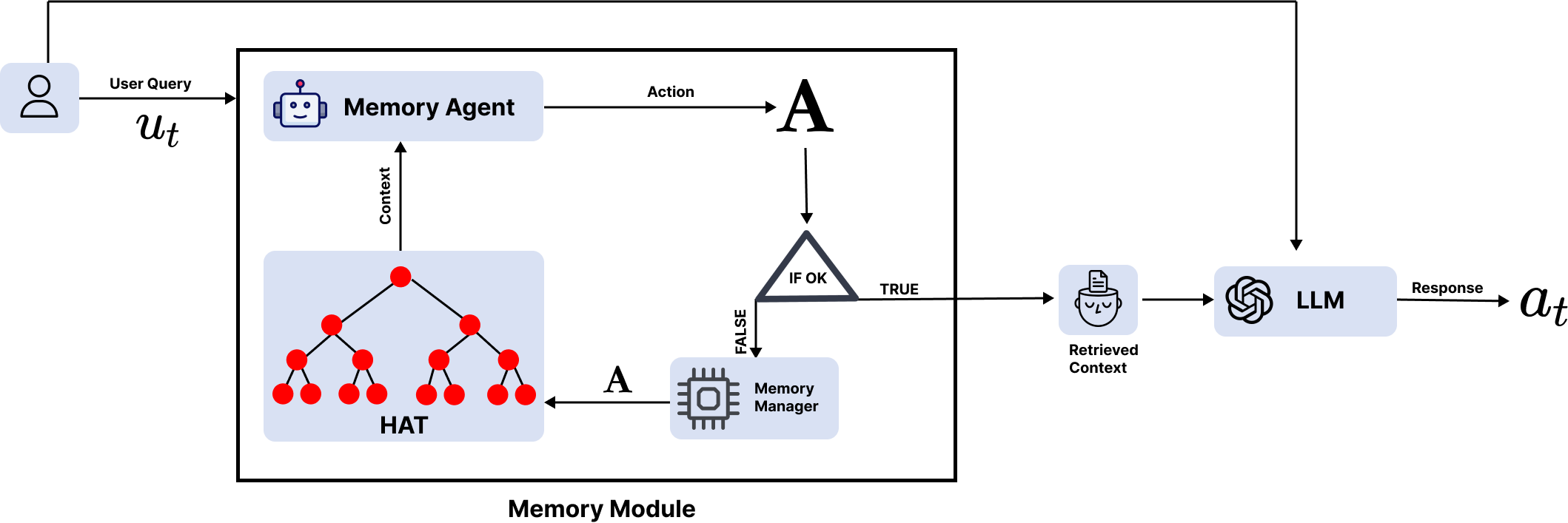
Large language models have limited context capacity, hindering reasoning over long conversations. We propose the Hierarchical Aggregate Tree memory structure to recursively aggregate relevant dialogue context through conditional tree traversals. HAT encapsulates information from children nodes, enabling broad coverage with depth control. We formulate finding best context as optimal tree traversal. Experiments show HAT improves dialog coherence and summary quality over baseline contexts, demonstrating the techniques effectiveness for multi turn reasoning without exponential parameter growth. This memory augmentation enables more consistent, grounded longform conversations from LLMs
6/11/2024
💬
MEMORYLLM: Towards Self-Updatable Large Language Models
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, Julian McAuley
0
0
Existing Large Language Models (LLMs) usually remain static after deployment, which might make it hard to inject new knowledge into the model. We aim to build models containing a considerable portion of self-updatable parameters, enabling the model to integrate new knowledge effectively and efficiently. To this end, we introduce MEMORYLLM, a model that comprises a transformer and a fixed-size memory pool within the latent space of the transformer. MEMORYLLM can self-update with text knowledge and memorize the knowledge injected earlier. Our evaluations demonstrate the ability of MEMORYLLM to effectively incorporate new knowledge, as evidenced by its performance on model editing benchmarks. Meanwhile, the model exhibits long-term information retention capacity, which is validated through our custom-designed evaluations and long-context benchmarks. MEMORYLLM also shows operational integrity without any sign of performance degradation even after nearly a million memory updates. Our code and model are open-sourced at https://github.com/wangyu-ustc/MemoryLLM.
5/28/2024
🔍
InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory
Chaojun Xiao, Pengle Zhang, Xu Han, Guangxuan Xiao, Yankai Lin, Zhengyan Zhang, Zhiyuan Liu, Maosong Sun
0
0
Large language models (LLMs) have emerged as a cornerstone in real-world applications with lengthy streaming inputs (e.g., LLM-driven agents). However, existing LLMs, pre-trained on sequences with a restricted maximum length, cannot process longer sequences due to the out-of-domain and distraction issues. Common solutions often involve continual pre-training on longer sequences, which will introduce expensive computational overhead and uncontrollable change in model capabilities. In this paper, we unveil the intrinsic capacity of LLMs for understanding extremely long sequences without any fine-tuning. To this end, we introduce a training-free memory-based method, InfLLM. Specifically, InfLLM stores distant contexts into additional memory units and employs an efficient mechanism to lookup token-relevant units for attention computation. Thereby, InfLLM allows LLMs to efficiently process long sequences with a limited context window and well capture long-distance dependencies. Without any training, InfLLM enables LLMs that are pre-trained on sequences consisting of a few thousand tokens to achieve comparable performance with competitive baselines that continually train these LLMs on long sequences. Even when the sequence length is scaled to $1,024$K, InfLLM still effectively captures long-distance dependencies. Our code can be found in url{https://github.com/thunlp/InfLLM}.
5/29/2024