Hierarchical Separable Video Transformer for Snapshot Compressive Imaging

0

Sign in to get full access
Overview
- This paper presents a new video reconstruction model called Hierarchical Separable Video Transformer (HSVIT) for snapshot compressive imaging.
- Snapshot compressive imaging is a technique that captures a high-speed video using a single camera snapshot, which is then reconstructed computationally.
- The HSVIT model uses a hierarchical transformer architecture to efficiently process the video data and produce high-quality reconstructions.
Plain English Explanation
The researchers have developed a new way to reconstruct high-speed videos from single camera snapshots. This technique, called snapshot compressive imaging, is useful for capturing fast-moving events that are difficult to record with traditional video cameras.
The key innovation in this paper is the Hierarchical Separable Video Transformer (HSVIT) model. This model uses a specialized transformer architecture to efficiently process the video data and produce high-quality reconstructions.
Transformers are a type of neural network that have shown great success in tasks like natural language processing. By adapting the transformer design to work with video data, the researchers were able to create a model that can capture the complex spatial and temporal relationships in the video, leading to more accurate reconstructions.
The hierarchical and separable nature of the HSVIT model also makes it efficient and scalable, allowing it to handle high-resolution videos without requiring excessive computational resources.
Technical Explanation
The Hierarchical Separable Video Transformer (HSVIT) model uses a transformer-based architecture to perform video reconstruction for snapshot compressive imaging.
The key components of the HSVIT model include:
-
Hierarchical Encoder: This module processes the input video frames in a hierarchical manner, extracting features at multiple scales. This allows the model to capture both local and global information in the video.
-
Separable Transformer Blocks: The transformer blocks in the HSVIT model are designed to be separable, meaning they process the spatial and temporal dimensions of the video independently. This improves the efficiency and scalability of the model.
-
Multi-Scale Fusion: The features extracted at different scales in the hierarchical encoder are combined through a multi-scale fusion module, allowing the model to integrate information at various resolutions.
-
Efficient Attention Mechanism: The transformer blocks in HSVIT use a novel attention mechanism that is more efficient than traditional attention, further improving the model's computational performance.
The researchers evaluated the HSVIT model on several snapshot compressive imaging benchmark datasets, demonstrating state-of-the-art performance in terms of video reconstruction quality and computational efficiency.
Critical Analysis
The HSVIT model presented in this paper is a significant advancement in the field of snapshot compressive imaging, addressing several key challenges in this area.
One potential limitation of the research is that the model was only evaluated on a limited set of benchmark datasets. It would be valuable to see how the HSVIT model performs on a wider range of real-world video data, including more diverse scenes and motion patterns.
Additionally, the paper does not provide a detailed analysis of the model's sensitivity to different types of noise or compression artifacts that may be present in the input snapshots. Understanding the robustness of the HSVIT model to these factors would be an important consideration for real-world applications.
The researchers also acknowledge that there is still room for improvement in the computational efficiency of the model, particularly for high-resolution video reconstruction. Further refinements to the architecture or attention mechanism could potentially address this limitation.
Overall, the Hierarchical Separable Video Transformer (HSVIT) represents an exciting development in the field of video reconstruction from compressed inputs. The model's strong performance and efficient design make it a promising candidate for practical applications in areas such as high-speed imaging, surveillance, and robotics.
Conclusion
The Hierarchical Separable Video Transformer (HSVIT) proposed in this paper is a novel approach to video reconstruction for snapshot compressive imaging. By adapting the transformer architecture to efficiently process video data, the HSVIT model achieves state-of-the-art performance in terms of reconstruction quality and computational efficiency.
The hierarchical and separable nature of the HSVIT model allows it to capture both local and global features in the video, while the efficient attention mechanism further improves its scalability. These innovations make the HSVIT a promising tool for a wide range of applications that require high-speed video capture and reconstruction, such as scientific research, industrial monitoring, and autonomous systems.
While the paper demonstrates the effectiveness of the HSVIT model on benchmark datasets, further research is needed to evaluate its performance on more diverse and challenging real-world scenarios. Exploring the model's robustness to noise and compression artifacts, as well as continued improvements to its computational efficiency, will be important next steps in advancing the state-of-the-art in snapshot compressive imaging.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Separable Video Transformer for Snapshot Compressive Imaging
Ping Wang, Yulun Zhang, Lishun Wang, Xin Yuan
Transformers have achieved the state-of-the-art performance on solving the inverse problem of Snapshot Compressive Imaging (SCI) for video, whose ill-posedness is rooted in the mixed degradation of spatial masking and temporal aliasing. However, previous Transformers lack an insight into the degradation and thus have limited performance and efficiency. In this work, we tailor an efficient reconstruction architecture without temporal aggregation in early layers and Hierarchical Separable Video Transformer (HiSViT) as building block. HiSViT is built by multiple groups of Cross-Scale Separable Multi-head Self-Attention (CSS-MSA) and Gated Self-Modulated Feed-Forward Network (GSM-FFN) with dense connections, each of which is conducted within a separate channel portions at a different scale, for multi-scale interactions and long-range modeling. By separating spatial operations from temporal ones, CSS-MSA introduces an inductive bias of paying more attention within frames instead of between frames while saving computational overheads. GSM-FFN further enhances the locality via gated mechanism and factorized spatial-temporal convolutions. Extensive experiments demonstrate that our method outperforms previous methods by $!>!0.5$ dB with comparable or fewer parameters and complexity. The source codes and pretrained models are released at https://github.com/pwangcs/HiSViT.
Read more7/18/2024
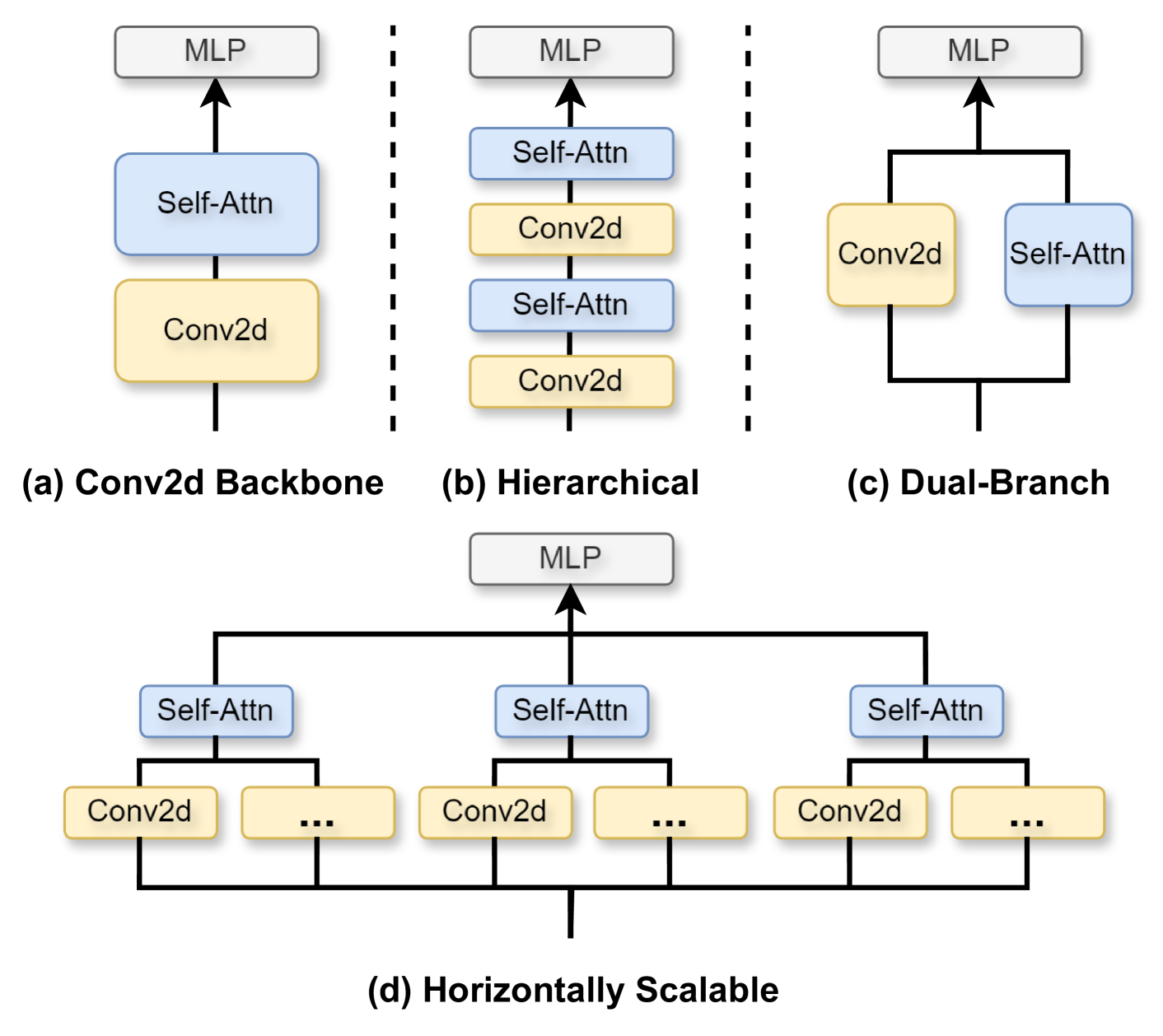
0
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
Due to its deficiency in prior knowledge (inductive bias), Vision Transformer (ViT) requires pre-training on large-scale datasets to perform well. Moreover, the growing layers and parameters in ViT models impede their applicability to devices with limited computing resources. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT) scheme. Specifically, a novel image-level feature embedding is introduced to ViT, where the preserved inductive bias allows the model to eliminate the need for pre-training while outperforming on small datasets. Besides, a novel horizontally scalable architecture is designed, facilitating collaborative model training and inference across multiple computing devices. The experimental results depict that, without pre-training, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes on small datasets, while providing existing CNN backbones up to 3.1% improvement in top-1 accuracy on ImageNet. The code is available at https://github.com/xuchenhao001/HSViT.
Read more7/17/2024

0
Bi-Level Spatial and Channel-aware Transformer for Learned Image Compression
Hamidreza Soltani, Erfan Ghasemi
Recent advancements in learned image compression (LIC) methods have demonstrated superior performance over traditional hand-crafted codecs. These learning-based methods often employ convolutional neural networks (CNNs) or Transformer-based architectures. However, these nonlinear approaches frequently overlook the frequency characteristics of images, which limits their compression efficiency. To address this issue, we propose a novel Transformer-based image compression method that enhances the transformation stage by considering frequency components within the feature map. Our method integrates a novel Hybrid Spatial-Channel Attention Transformer Block (HSCATB), where a spatial-based branch independently handles high and low frequencies at the attention layer, and a Channel-aware Self-Attention (CaSA) module captures information across channels, significantly improving compression performance. Additionally, we introduce a Mixed Local-Global Feed Forward Network (MLGFFN) within the Transformer block to enhance the extraction of diverse and rich information, which is crucial for effective compression. These innovations collectively improve the transformation's ability to project data into a more decorrelated latent space, thereby boosting overall compression efficiency. Experimental results demonstrate that our framework surpasses state-of-the-art LIC methods in rate-distortion performance.
Read more8/9/2024

0
New!Investigation of Hierarchical Spectral Vision Transformer Architecture for Classification of Hyperspectral Imagery
Wei Liu, Saurabh Prasad, Melba Crawford
In the past three years, there has been significant interest in hyperspectral imagery (HSI) classification using vision Transformers for analysis of remotely sensed data. Previous research predominantly focused on the empirical integration of convolutional neural networks (CNNs) to augment the network's capability to extract local feature information. Yet, the theoretical justification for vision Transformers out-performing CNN architectures in HSI classification remains a question. To address this issue, a unified hierarchical spectral vision Transformer architecture, specifically tailored for HSI classification, is investigated. In this streamlined yet effective vision Transformer architecture, multiple mixer modules are strategically integrated separately. These include the CNN-mixer, which executes convolution operations; the spatial self-attention (SSA)-mixer and channel self-attention (CSA)-mixer, both of which are adaptations of classical self-attention blocks; and hybrid models such as the SSA+CNN-mixer and CSA+CNN-mixer, which merge convolution with self-attention operations. This integration facilitates the development of a broad spectrum of vision Transformer-based models tailored for HSI classification. In terms of the training process, a comprehensive analysis is performed, contrasting classical CNN models and vision Transformer-based counterparts, with particular attention to disturbance robustness and the distribution of the largest eigenvalue of the Hessian. From the evaluations conducted on various mixer models rooted in the unified architecture, it is concluded that the unique strength of vision Transformers can be attributed to their overarching architecture, rather than being exclusively reliant on individual multi-head self-attention (MSA) components.
Read more9/17/2024