HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy
2401.15207
0
0

Abstract
Full-parameter fine-tuning has become the go-to choice for adapting language models (LMs) to downstream tasks due to its excellent performance. As LMs grow in size, fine-tuning the full parameters of LMs requires a prohibitively large amount of GPU memory. Existing approaches utilize zeroth-order optimizer to conserve GPU memory, which can potentially compromise the performance of LMs as non-zero order optimizers tend to converge more readily on most downstream tasks. In this paper, we propose a novel optimizer-independent end-to-end hierarchical fine-tuning strategy, HiFT, which only updates a subset of parameters at each training step. HiFT can significantly reduce the amount of gradients and optimizer state parameters residing in GPU memory at the same time, thereby reducing GPU memory usage. Our results demonstrate that: (1) HiFT achieves comparable performance to parameter-efficient fine-tuning and standard full parameter fine-tuning. (2) HiFT supports various optimizers including AdamW, AdaGrad, SGD, etc. (3) HiFT can save more than 60% GPU memory compared with standard full-parameter fine-tuning for 7B model. (4) HiFT enables full-parameter fine-tuning of a 7B model on single 48G A6000 with a precision of 32 using the AdamW optimizer, without using any memory saving techniques.
Create account to get full access
Overview
- Presents a new fine-tuning strategy called Hierarchical Full-Parameter Tuning (HiFT) for large language models
- Aims to improve performance on downstream tasks while maintaining model efficiency
- Compares HiFT to other fine-tuning approaches like full-parameter fine-tuning and parameter-efficient fine-tuning
Plain English Explanation
The paper introduces a new way to fine-tune large language models called Hierarchical Full-Parameter Tuning (HiFT). Fine-tuning is the process of further training a pre-trained model on a specific task to improve its performance.
In full-parameter fine-tuning, all the model's parameters are updated during fine-tuning. This can lead to good performance but also runs the risk of the model forgetting information from the original pre-training. Parameter-efficient fine-tuning approaches try to minimize the number of parameters updated to be more memory-efficient, but this can limit the model's ability to adapt to the new task.
HiFT aims to strike a balance - it updates all the model's parameters during fine-tuning, but does so in a hierarchical fashion. The lower layers of the model are fine-tuned first, followed by the higher layers. This allows the model to gradually adapt to the new task without catastrophically forgetting the knowledge gained during pre-training.
The authors show that HiFT can achieve better performance on downstream tasks compared to full-parameter and parameter-efficient fine-tuning, while still maintaining model efficiency.
Technical Explanation
The paper proposes a new fine-tuning strategy called Hierarchical Full-Parameter Tuning (HiFT) for improving the performance of large language models on downstream tasks.
In contrast to full-parameter fine-tuning, where all model parameters are updated during fine-tuning, HiFT updates the model parameters in a hierarchical fashion. The lower layers of the model are fine-tuned first, followed by the higher layers. This allows the model to gradually adapt to the new task without catastrophically forgetting the knowledge gained during pre-training.
Compared to parameter-efficient fine-tuning approaches that aim to minimize the number of parameters updated, HiFT updates all model parameters but in a structured way. This enables the model to leverage the full expressive power of the pre-trained model while still maintaining parameter efficiency.
The authors conduct experiments on various natural language understanding benchmarks and show that HiFT outperforms both full-parameter and parameter-efficient fine-tuning in terms of task performance. They also demonstrate the stability and robustness of the HiFT approach through extensive ablation studies.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the HiFT fine-tuning strategy. The authors compare it against strong baselines like full-parameter and parameter-efficient fine-tuning, and the results demonstrate the effectiveness of the hierarchical approach.
One potential limitation is that the experiments are focused on natural language understanding tasks. It would be interesting to see how HiFT performs on other types of tasks, such as language generation or multimodal learning, to further validate the generality of the approach.
Additionally, the paper does not provide much insight into the underlying reasons why the hierarchical fine-tuning strategy is beneficial. A more in-depth analysis of the learned representations and the model's adaptation process could shed light on the mechanisms behind HiFT's success.
Overall, the paper makes a compelling case for the HiFT fine-tuning strategy and its potential to improve the performance and efficiency of large language models. The work contributes to the broader study of optimizations for fine-tuning large language models and the [ongoing efforts to develop more parameter-efficient fine-tuning techniques.
Conclusion
The HiFT paper presents a novel fine-tuning strategy that aims to improve the performance of large language models on downstream tasks while maintaining model efficiency. By updating the model parameters in a hierarchical fashion, HiFT allows the model to gradually adapt to the new task without catastrophically forgetting the knowledge gained during pre-training.
The experimental results demonstrate the effectiveness of HiFT compared to full-parameter and parameter-efficient fine-tuning approaches. This work contributes to the ongoing efforts in the field to develop more advanced fine-tuning techniques that can unlock the full potential of large language models.
As the use of these powerful models becomes more widespread, strategies like HiFT will be increasingly important for enabling efficient and effective fine-tuning on a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
HFT: Half Fine-Tuning for Large Language Models
Tingfeng Hui, Zhenyu Zhang, Shuohuan Wang, Weiran Xu, Yu Sun, Hua Wu
0
0
Large language models (LLMs) with one or more fine-tuning phases have become a necessary step to unlock various capabilities, enabling LLMs to follow natural language instructions or align with human preferences. However, it carries the risk of catastrophic forgetting during sequential training, the parametric knowledge or the ability learned in previous stages may be overwhelmed by incoming training data. In this paper, we find that by regularly resetting partial parameters, LLMs can restore some of the original knowledge. Inspired by this, we introduce Half Fine-Tuning (HFT) for LLMs, as a substitute for full fine-tuning (FFT), to mitigate the forgetting issues, where half of the parameters are selected to learn new tasks while the other half are frozen to remain previous knowledge. We provide a feasibility analysis from the perspective of optimization and interpret the parameter selection operation as a regularization term. Without changing the model architecture, HFT could be seamlessly integrated into existing fine-tuning frameworks. Extensive experiments and analysis on supervised fine-tuning, direct preference optimization, and continual learning consistently demonstrate the effectiveness, robustness, and efficiency of HFT. Compared with FFT, HFT not only significantly alleviates the forgetting problem, but also achieves the best performance in a series of downstream benchmarks, with an approximately 30% reduction in training time.
4/30/2024

Full Parameter Fine-tuning for Large Language Models with Limited Resources
Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, Xipeng Qiu
0
0
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but demand massive GPU resources for training. Lowering the threshold for LLMs training would encourage greater participation from researchers, benefiting both academia and society. While existing approaches have focused on parameter-efficient fine-tuning, which tunes or adds a small number of parameters, few have addressed the challenge of tuning the full parameters of LLMs with limited resources. In this work, we propose a new optimizer, LOw-Memory Optimization (LOMO), which fuses the gradient computation and the parameter update in one step to reduce memory usage. By integrating LOMO with existing memory saving techniques, we reduce memory usage to 10.8% compared to the standard approach (DeepSpeed solution). Consequently, our approach enables the full parameter fine-tuning of a 65B model on a single machine with 8 RTX 3090, each with 24GB memory.Code and data are available at https://github.com/OpenLMLab/LOMO.
6/7/2024
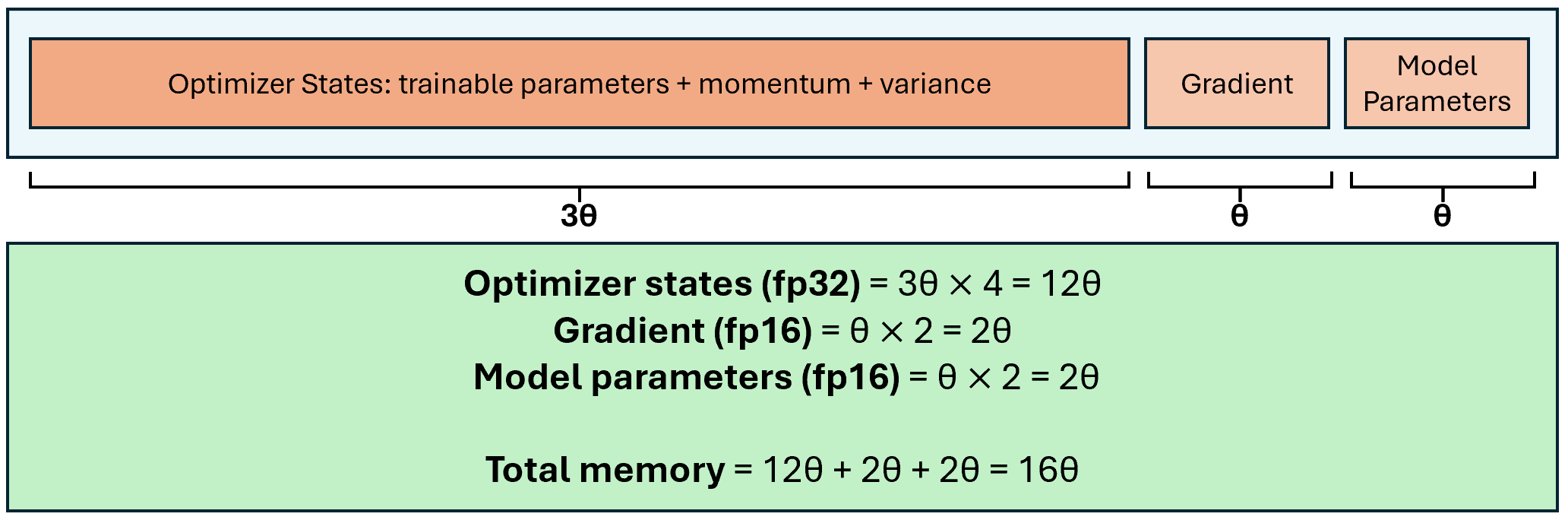
A Study of Optimizations for Fine-tuning Large Language Models
Arjun Singh, Nikhil Pandey, Anup Shirgaonkar, Pavan Manoj, Vijay Aski
0
0
Fine-tuning large language models is a popular choice among users trying to adapt them for specific applications. However, fine-tuning these models is a demanding task because the user has to examine several factors, such as resource budget, runtime, model size and context length among others. A specific challenge is that fine-tuning is memory intensive, imposing constraints on the required hardware memory and context length of training data that can be handled. In this work, we share a detailed study on a variety of fine-tuning optimizations across different fine-tuning scenarios. In particular, we assess Gradient Checkpointing, Low-Rank Adaptation, DeepSpeed's Zero Redundancy Optimizer and FlashAttention. With a focus on memory and runtime, we examine the impact of different optimization combinations on GPU memory usage and execution runtime during fine-tuning phase. We provide our recommendation on the best default optimization for balancing memory and runtime across diverse model sizes. We share effective strategies for fine-tuning very large models with tens or hundreds of billions of parameters and enabling large context lengths during fine-tuning. Furthermore, we propose the appropriate optimization mixtures for fine-tuning under GPU resource limitations.
6/7/2024

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024