HFT: Half Fine-Tuning for Large Language Models
2404.18466
0
0
💬
Abstract
Large language models (LLMs) with one or more fine-tuning phases have become a necessary step to unlock various capabilities, enabling LLMs to follow natural language instructions or align with human preferences. However, it carries the risk of catastrophic forgetting during sequential training, the parametric knowledge or the ability learned in previous stages may be overwhelmed by incoming training data. In this paper, we find that by regularly resetting partial parameters, LLMs can restore some of the original knowledge. Inspired by this, we introduce Half Fine-Tuning (HFT) for LLMs, as a substitute for full fine-tuning (FFT), to mitigate the forgetting issues, where half of the parameters are selected to learn new tasks while the other half are frozen to remain previous knowledge. We provide a feasibility analysis from the perspective of optimization and interpret the parameter selection operation as a regularization term. Without changing the model architecture, HFT could be seamlessly integrated into existing fine-tuning frameworks. Extensive experiments and analysis on supervised fine-tuning, direct preference optimization, and continual learning consistently demonstrate the effectiveness, robustness, and efficiency of HFT. Compared with FFT, HFT not only significantly alleviates the forgetting problem, but also achieves the best performance in a series of downstream benchmarks, with an approximately 30% reduction in training time.
Create account to get full access
Overview
- Large language models (LLMs) require fine-tuning to unlock various capabilities, but this can lead to catastrophic forgetting of previous knowledge.
- The paper introduces a new technique called Half Fine-Tuning (HFT) to mitigate this issue, where half the model parameters are frozen while the other half are fine-tuned.
- HFT is designed to preserve the original knowledge learned by the LLM while allowing it to adapt to new tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems that can understand and generate human-like text. However, to make them truly useful, they often need to be "fine-tuned" on specific tasks or datasets. This fine-tuning process can help the LLM learn new skills, like following natural language instructions or aligning with human preferences.
The problem is that this fine-tuning can cause the LLM to "forget" some of the original knowledge it had learned. This is known as "catastrophic forgetting." Imagine if you were a human who was really good at math, but then you started focusing on learning a new language. Over time, your math skills might start to deteriorate.
The paper introduces a new technique called "Half Fine-Tuning" (HFT) to address this issue. The idea is to only fine-tune half of the LLM's parameters, while keeping the other half frozen. This way, the LLM can learn new skills without completely forgetting its original knowledge. It's like if you were learning a new language, but you still kept practicing your math skills on the side.
The researchers show that HFT can significantly improve performance compared to traditional fine-tuning, while also reducing the training time by about 30%. This makes it a more efficient and effective way to adapt LLMs to new tasks.
Technical Explanation
The paper introduces a new fine-tuning technique called "Half Fine-Tuning" (HFT) to address the issue of catastrophic forgetting in large language models (LLMs). During the fine-tuning process, LLMs can lose the parametric knowledge or capabilities they had learned in previous stages, as the new training data overwhelms the model.
To mitigate this problem, the researchers propose HFT as a substitute for the traditional full fine-tuning (FFT) approach. In HFT, only half of the model parameters are selected to learn new tasks, while the other half are kept frozen to maintain the original knowledge. This parameter selection process is interpreted as a form of regularization, which helps the model balance the learning of new tasks with the preservation of prior knowledge.
The researchers provide a feasibility analysis of HFT from an optimization perspective and demonstrate that it can be seamlessly integrated into existing fine-tuning frameworks without requiring changes to the model architecture. Through extensive experiments on supervised fine-tuning, direct preference optimization, and continual learning tasks, the paper shows that HFT not only significantly alleviates the forgetting problem but also achieves the best performance in a range of downstream benchmarks, with a roughly 30% reduction in training time compared to FFT.
Critical Analysis
The paper presents a compelling approach to mitigating the catastrophic forgetting problem in large language models, but it's important to consider some potential limitations and areas for further research.
One concern is the generalizability of the HFT technique. The experiments in the paper focus on a specific set of tasks and datasets, and it's unclear how well the method would perform on a broader range of applications or in more complex real-world scenarios. Further research may be needed to assess the robustness and scalability of HFT across a wider range of use cases.
Another potential issue is the selection of the parameters to be frozen during HFT. The paper proposes a simple random selection approach, but more sophisticated strategies for identifying the most critical or informative parameters to preserve may lead to even better results. Exploring alternative parameter selection methods could be an interesting area for future work.
Additionally, the paper does not provide a deep analysis of the mechanisms underlying the improved performance of HFT. While the optimization-based interpretation is helpful, a more detailed understanding of the cognitive or neural processes involved in mitigating catastrophic forgetting could provide valuable insights and inspire further advancements in this field.
Overall, the HFT approach presented in this paper represents a promising step forward in addressing the challenge of preserving the original knowledge of large language models during fine-tuning. However, as with any research, it's important to consider the limitations and continue exploring ways to further enhance the efficiency and robustness of these powerful AI systems.
Conclusion
The paper introduces a novel fine-tuning technique called Half Fine-Tuning (HFT) that effectively mitigates the catastrophic forgetting problem in large language models. By selectively fine-tuning only half of the model parameters while keeping the other half frozen, HFT is able to preserve the original knowledge learned by the LLM while still allowing it to adapt to new tasks.
The researchers demonstrate the effectiveness, robustness, and efficiency of HFT through extensive experiments, showing that it not only significantly reduces forgetting but also outperforms traditional full fine-tuning on a range of downstream benchmarks. With its potential to unlock the full capabilities of LLMs without compromising their existing knowledge, HFT represents an important contribution to the ongoing efforts to enhance the versatility and performance of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

HiFT: A Hierarchical Full Parameter Fine-Tuning Strategy
Yongkang Liu, Yiqun Zhang, Qian Li, Tong Liu, Shi Feng, Daling Wang, Yifei Zhang, Hinrich Schutze
0
0
Full-parameter fine-tuning has become the go-to choice for adapting language models (LMs) to downstream tasks due to its excellent performance. As LMs grow in size, fine-tuning the full parameters of LMs requires a prohibitively large amount of GPU memory. Existing approaches utilize zeroth-order optimizer to conserve GPU memory, which can potentially compromise the performance of LMs as non-zero order optimizers tend to converge more readily on most downstream tasks. In this paper, we propose a novel optimizer-independent end-to-end hierarchical fine-tuning strategy, HiFT, which only updates a subset of parameters at each training step. HiFT can significantly reduce the amount of gradients and optimizer state parameters residing in GPU memory at the same time, thereby reducing GPU memory usage. Our results demonstrate that: (1) HiFT achieves comparable performance to parameter-efficient fine-tuning and standard full parameter fine-tuning. (2) HiFT supports various optimizers including AdamW, AdaGrad, SGD, etc. (3) HiFT can save more than 60% GPU memory compared with standard full-parameter fine-tuning for 7B model. (4) HiFT enables full-parameter fine-tuning of a 7B model on single 48G A6000 with a precision of 32 using the AdamW optimizer, without using any memory saving techniques.
6/18/2024
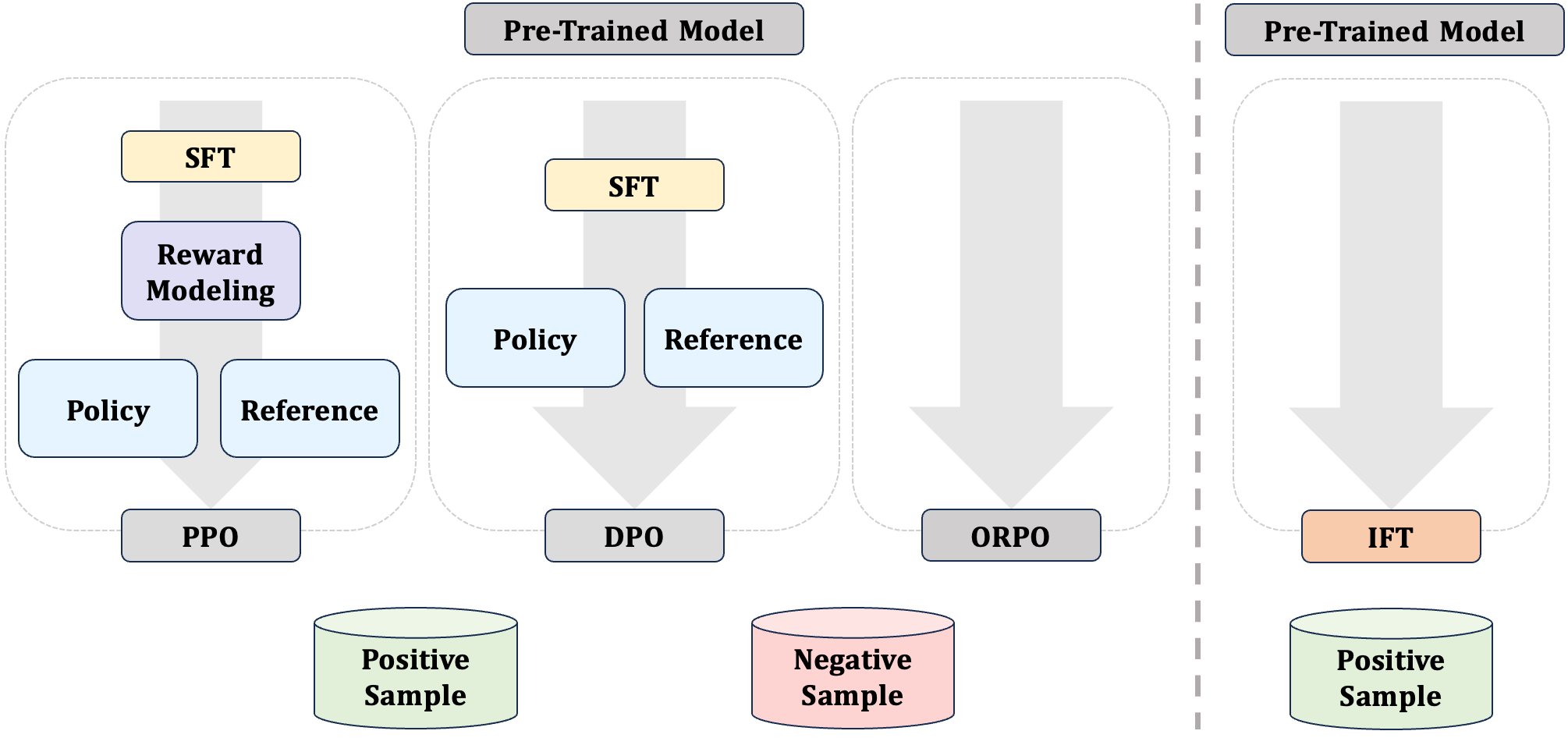
Intuitive Fine-Tuning: Towards Unifying SFT and RLHF into a Single Process
Ermo Hua, Biqing Qi, Kaiyan Zhang, Yue Yu, Ning Ding, Xingtai Lv, Kai Tian, Bowen Zhou
0
0
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language Models (LMs) post pre-training, aligning them better with human preferences. Although SFT advances in training efficiency, PO delivers better alignment, thus they are often combined. However, common practices simply apply them sequentially without integrating their optimization objectives, ignoring the opportunities to bridge their paradigm gap and take the strengths from both. To obtain a unified understanding, we interpret SFT and PO with two sub-processes -- Preference Estimation and Transition Optimization -- defined at token level within the Markov Decision Process (MDP) framework. This modeling shows that SFT is only a specialized case of PO with inferior estimation and optimization. PO evaluates the quality of model's entire generated answer, whereas SFT only scores predicted tokens based on preceding tokens from target answers. Therefore, SFT overestimates the ability of model, leading to inferior optimization. Building on this view, we introduce Intuitive Fine-Tuning (IFT) to integrate SFT and Preference Optimization into a single process. IFT captures LMs' intuitive sense of the entire answers through a temporal residual connection, but it solely relies on a single policy and the same volume of non-preference-labeled data as SFT. Our experiments show that IFT performs comparably or even superiorly to sequential recipes of SFT and some typical Preference Optimization methods across several tasks, particularly those requires generation, reasoning, and fact-following abilities. An explainable Frozen Lake game further validates the effectiveness of IFT for getting competitive policy.
5/29/2024
💬
Comparative Analysis of Different Efficient Fine Tuning Methods of Large Language Models (LLMs) in Low-Resource Setting
Krishna Prasad Varadarajan Srinivasan, Prasanth Gumpena, Madhusudhana Yattapu, Vishal H. Brahmbhatt
0
0
In the domain of large language models (LLMs), arXiv:2305.16938 showed that few-shot full-model fine-tuning -- namely Vanilla Fine Tuning (FT) and Pattern-Based Fine Tuning (PBFT) --, and In-Context Learning (ICL) generalize similarly on Out-Of-Domain (OOD) datasets, but vary in terms of task adaptation. However, they both pose challenges, especially in term of memory requirements. In this paper, we further try to push the understanding of different fine-tuning strategies for LLM and aim to bring a myriad of these on the same pedestal for an elaborate comparison with full-model fine-tuning on two diverse datasets. To that end, we conducted a series of experiments, beginning with state-of-the-art methods like vanilla fine-tuning and Pattern-Based Fine-Tuning (PBFT) on pre-trained models across two datasets, COLA and MNLI. We then investigate adaptive fine-tuning and the efficiency of LoRA adapters in a few-shot setting. Finally, we also compare an alternative approach that has gained recent popularity -- context distillation -- with the vanilla FT and PBFT with and without few-shot setup. Our findings suggest that these alternative strategies that we explored can exhibit out-of-domain generalization comparable to that of vanilla FT and PBFT. PBFT under-performs Vanilla FT on out-of-domain (OOD) data, emphasizing the need for effective prompts. Further, our adaptive-fine tuning and LoRA experiments perform comparable or slightly worse than the standard fine-tunings as anticipated, since standard fine-tunings involve tuning the entire model. Finally, our context distillation experiments out-perform the standard fine-tuning methods. These findings underscore that eventually the choice of an appropriate fine-tuning method depends on the available resources (memory, compute, data) and task adaptability.
5/24/2024

Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
0
0
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
4/30/2024