High dimensional Bayesian Optimization via Condensing-Expansion Projection

0
Sign in to get full access
Overview
- This paper presents a new approach for high-dimensional Bayesian optimization using a Condensing-Expansion Projection (CEP) method.
- The key idea is to project the high-dimensional search space onto a lower-dimensional subspace, perform optimization in that subspace, and then expand the solution back to the original high-dimensional space.
- The authors demonstrate that CEP can effectively solve high-dimensional optimization problems with strong empirical results.
Plain English Explanation
The paper introduces a technique called Condensing-Expansion Projection (CEP) to address the challenge of Bayesian optimization in high-dimensional search spaces. Bayesian optimization is a powerful method for optimizing black-box functions, but it can struggle when the number of input variables is very large.
The CEP approach works by projecting the high-dimensional search space onto a lower-dimensional subspace. This allows the optimization to be performed more efficiently in the reduced space. The solution is then expanded back to the original high-dimensional space, providing the final optimized result.
The key insight is that many high-dimensional optimization problems have an underlying low-dimensional structure that can be leveraged. By focusing the search on this lower-dimensional subspace, CEP can find good solutions more quickly than exploring the full high-dimensional space.
Technical Explanation
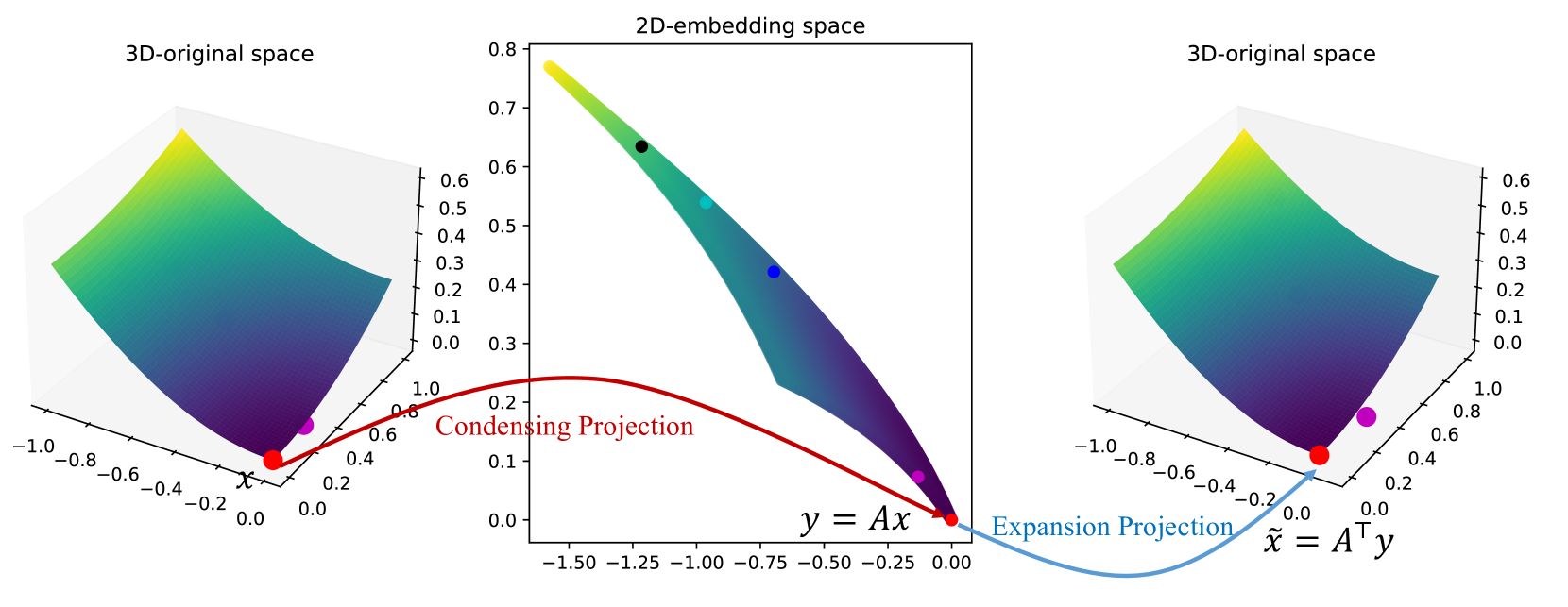
The paper proposes a Condensing-Expansion Projection (CEP) method for high-dimensional Bayesian optimization. The core idea is to project the high-dimensional search space onto a lower-dimensional subspace, perform optimization in that subspace, and then expand the solution back to the original high-dimensional space.
The projection step uses principal component analysis (PCA) to identify the most important dimensions of the search space. The optimization is then carried out in this lower-dimensional subspace using a standard Bayesian optimization algorithm. Finally, the expansion step maps the optimized solution back to the full high-dimensional space.
The authors demonstrate that this CEP approach can effectively solve high-dimensional optimization problems, outperforming alternative methods on a range of benchmark tasks. By leveraging the underlying low-dimensional structure of the problem, CEP is able to find good solutions more efficiently than exploring the entire high-dimensional space.
Critical Analysis
The paper presents a novel and promising approach to high-dimensional Bayesian optimization using the Condensing-Expansion Projection (CEP) method. However, the authors acknowledge several limitations and areas for further research:
- The projection step using PCA assumes the problem has a low-dimensional structure, which may not always be the case. More sophisticated dimensionality reduction techniques could be explored.
- The expansion step may introduce errors or distortions when mapping the optimized solution back to the full high-dimensional space. The impact of this step on optimization performance is not fully characterized.
- The paper focuses on continuous optimization problems, but many real-world applications involve discrete or mixed-integer search spaces that are not addressed.
- The experimental evaluation is limited to synthetic benchmark problems, and the performance on realistic high-dimensional optimization tasks is not evaluated.
Overall, the CEP approach represents an interesting and promising direction for high-dimensional Bayesian optimization, but further research is needed to address the limitations and expand the applicability of the method.
Conclusion
This paper introduces a novel Condensing-Expansion Projection (CEP) method to address the challenge of high-dimensional Bayesian optimization. By projecting the search space onto a lower-dimensional subspace, performing optimization in that space, and then expanding the solution back to the original high-dimensional space, CEP can effectively solve complex optimization problems with many input variables.
The empirical results demonstrate the effectiveness of the CEP approach, and the authors discuss several promising directions for future research. As high-dimensional optimization problems become increasingly common in areas like machine learning and engineering design, techniques like CEP will be crucial for unlocking the potential of Bayesian optimization in these high-dimensional settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
High dimensional Bayesian Optimization via Condensing-Expansion Projection
Jiaming Lu, Rong J. B. Zhu
In high-dimensional settings, Bayesian optimization (BO) can be expensive and infeasible. The random embedding Bayesian optimization algorithm is commonly used to address high-dimensional BO challenges. However, this method relies on the effective subspace assumption on the optimization problem's objective function, which limits its applicability. In this paper, we introduce Condensing-Expansion Projection Bayesian optimization (CEPBO), a novel random projection-based approach for high-dimensional BO that does not reply on the effective subspace assumption. The approach is both simple to implement and highly practical. We present two algorithms based on different random projection matrices: the Gaussian projection matrix and the hashing projection matrix. Experimental results demonstrate that both algorithms outperform existing random embedding-based algorithms in most cases, achieving superior performance on high-dimensional BO problems. The code is available in url{https://anonymous.4open.science/r/CEPBO-14429}.
Read more8/12/2024
🛠️
0
Joint Composite Latent Space Bayesian Optimization
Natalie Maus, Zhiyuan Jerry Lin, Maximilian Balandat, Eytan Bakshy
Bayesian Optimization (BO) is a technique for sample-efficient black-box optimization that employs probabilistic models to identify promising input locations for evaluation. When dealing with composite-structured functions, such as f=g o h, evaluating a specific location x yields observations of both the final outcome f(x) = g(h(x)) as well as the intermediate output(s) h(x). Previous research has shown that integrating information from these intermediate outputs can enhance BO performance substantially. However, existing methods struggle if the outputs h(x) are high-dimensional. Many relevant problems fall into this setting, including in the context of generative AI, molecular design, or robotics. To effectively tackle these challenges, we introduce Joint Composite Latent Space Bayesian Optimization (JoCo), a novel framework that jointly trains neural network encoders and probabilistic models to adaptively compress high-dimensional input and output spaces into manageable latent representations. This enables viable BO on these compressed representations, allowing JoCo to outperform other state-of-the-art methods in high-dimensional BO on a wide variety of simulated and real-world problems.
Read more7/11/2024
0
Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
Huong Ha, Vu Nguyen, Hung Tran-The, Hongyu Zhang, Xiuzhen Zhang, Anton van den Hengel
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees of this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the objective function's global optimum even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures consistent estimation. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
Read more6/7/2024
🛠️
0
Comparison of High-Dimensional Bayesian Optimization Algorithms on BBOB
Maria Laura Santoni, Elena Raponi, Renato De Leone, Carola Doerr
Bayesian Optimization (BO) is a class of black-box, surrogate-based heuristics that can efficiently optimize problems that are expensive to evaluate, and hence admit only small evaluation budgets. BO is particularly popular for solving numerical optimization problems in industry, where the evaluation of objective functions often relies on time-consuming simulations or physical experiments. However, many industrial problems depend on a large number of parameters. This poses a challenge for BO algorithms, whose performance is often reported to suffer when the dimension grows beyond 15 variables. Although many new algorithms have been proposed to address this problem, it is not well understood which one is the best for which optimization scenario. In this work, we compare five state-of-the-art high-dimensional BO algorithms, with vanilla BO and CMA-ES on the 24 BBOB functions of the COCO environment at increasing dimensionality, ranging from 10 to 60 variables. Our results confirm the superiority of BO over CMA-ES for limited evaluation budgets and suggest that the most promising approach to improve BO is the use of trust regions. However, we also observe significant performance differences for different function landscapes and budget exploitation phases, indicating improvement potential, e.g., through hybridization of algorithmic components.
Read more6/26/2024