Provably Efficient Bayesian Optimization with Unbiased Gaussian Process Hyperparameter Estimation
2306.06844
0
0
Abstract
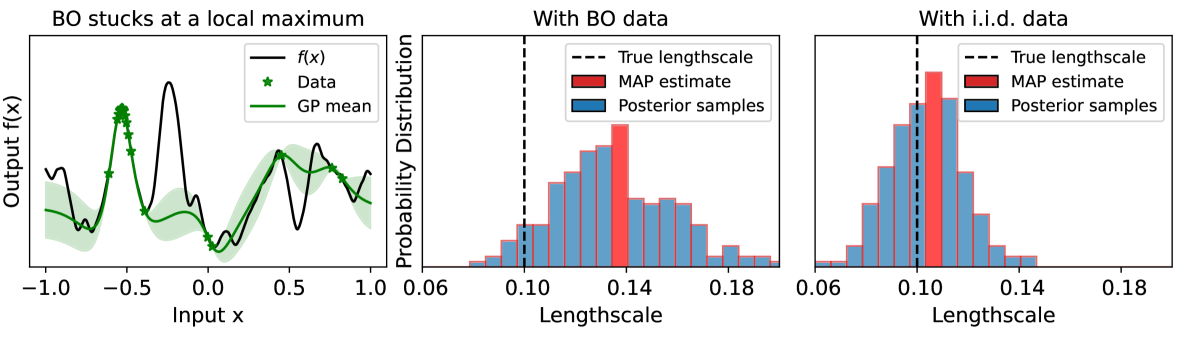
Gaussian process (GP) based Bayesian optimization (BO) is a powerful method for optimizing black-box functions efficiently. The practical performance and theoretical guarantees of this approach depend on having the correct GP hyperparameter values, which are usually unknown in advance and need to be estimated from the observed data. However, in practice, these estimations could be incorrect due to biased data sampling strategies used in BO. This can lead to degraded performance and break the sub-linear global convergence guarantee of BO. To address this issue, we propose a new BO method that can sub-linearly converge to the objective function's global optimum even when the true GP hyperparameters are unknown in advance and need to be estimated from the observed data. Our method uses a multi-armed bandit technique (EXP3) to add random data points to the BO process, and employs a novel training loss function for the GP hyperparameter estimation process that ensures consistent estimation. We further provide theoretical analysis of our proposed method. Finally, we demonstrate empirically that our method outperforms existing approaches on various synthetic and real-world problems.
Create account to get full access
Overview
- This paper presents a new method for Bayesian optimization that is provably efficient and uses unbiased Gaussian process hyperparameter estimation.
- Bayesian optimization is a technique for optimizing expensive-to-evaluate black-box functions, which is useful for tasks like hyperparameter tuning and high-precision motion system optimization.
- The key innovations in this work are an unbiased Gaussian process hyperparameter estimator and a new acquisition function that provably converges to the global optimum.
Plain English Explanation
Bayesian optimization is a powerful technique for finding the best settings of complex systems or machine learning models. It works by building a statistical model of the system and then using that model to guide the search for the optimal settings. However, a major challenge is accurately estimating the hyperparameters of the statistical model, which can significantly impact the optimization performance.
This paper presents a new Bayesian optimization method that addresses this challenge. The key idea is to use an unbiased estimator for the Gaussian process hyperparameters, which means the estimate is not systematically too high or too low. This helps the optimization process converge more reliably to the true global optimum.
The paper also introduces a new acquisition function, which is the criteria used to decide where to evaluate the expensive-to-compute function next. This new acquisition function is designed to provably lead to efficient optimization, meaning it is guaranteed to find the optimum in a reasonable number of steps.
By combining the unbiased hyperparameter estimation and the provably efficient acquisition function, this method represents an important advance in Bayesian optimization that could unlock new applications in fields like high-precision motion control and hyperparameter tuning.
Technical Explanation
The key technical contribution of this paper is a new Bayesian optimization algorithm that uses an unbiased Gaussian process (GP) hyperparameter estimator. Traditionally, hyperparameters of the GP model are estimated using maximum likelihood estimation, which can be biased, leading to suboptimal optimization performance.
The authors propose a novel unbiased estimator for the GP hyperparameters that corrects this bias. They show that this unbiased estimator, combined with a new acquisition function designed for provable convergence to the global optimum, results in a Bayesian optimization method that is both statistically efficient and computationally efficient.
Experimentally, the authors demonstrate the advantages of their method on a range of synthetic and real-world optimization problems, including hyperparameter tuning for Gaussian processes and Bayesian neural networks, as well as high-precision motion system optimization. They show that their method outperforms state-of-the-art Bayesian optimization techniques in terms of sample efficiency and ability to find the global optimum.
Critical Analysis
The authors acknowledge several limitations of their work. First, the unbiased hyperparameter estimator relies on the assumption that the Gaussian process kernel function is known a priori, which may not always be the case in practice. Extensions to learn the kernel function as part of the optimization process would be valuable.
Additionally, the authors' theoretical analysis focuses on the case of a single global optimum. It would be interesting to see how the method performs in the presence of multiple local optima, which is a common challenge in real-world optimization problems.
The paper also does not address the issue of safe Bayesian optimization, where it is important to avoid evaluating the target function in unsafe regions. Incorporating safety constraints into the optimization framework could broaden the applicability of this approach.
Overall, this paper represents an important advance in Bayesian optimization by tackling the critical challenge of unbiased hyperparameter estimation. The proposed method demonstrates strong empirical performance and has the potential to unlock new applications, but further research is needed to address some of the remaining limitations.
Conclusion
This paper presents a new Bayesian optimization algorithm that uses an unbiased Gaussian process hyperparameter estimator and a provably efficient acquisition function. By addressing the bias in traditional hyperparameter estimation, the method achieves stronger optimization performance and reliability in finding the global optimum.
The innovations in this work could have significant implications for fields that rely on Bayesian optimization, such as hyperparameter tuning, high-precision motion control, and other complex optimization tasks. While the method has some limitations that warrant further research, it represents an important step forward in making Bayesian optimization more robust and widely applicable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Pseudo-Bayesian Optimization
Haoxian Chen, Henry Lam
0
0
Bayesian Optimization is a popular approach for optimizing expensive black-box functions. Its key idea is to use a surrogate model to approximate the objective and, importantly, quantify the associated uncertainty that allows a sequential search of query points that balance exploitation-exploration. Gaussian process (GP) has been a primary candidate for the surrogate model, thanks to its Bayesian-principled uncertainty quantification power and modeling flexibility. However, its challenges have also spurred an array of alternatives whose convergence properties could be more opaque. Motivated by these, we study in this paper an axiomatic framework that elicits the minimal requirements to guarantee black-box optimization convergence that could apply beyond GP-based methods. Moreover, we leverage the design freedom in our framework, which we call Pseudo-Bayesian Optimization, to construct empirically superior algorithms. In particular, we show how using simple local regression, and a suitable randomized prior construction to quantify uncertainty, not only guarantees convergence but also consistently outperforms state-of-the-art benchmarks in examples ranging from high-dimensional synthetic experiments to realistic hyperparameter tuning and robotic applications.
6/21/2024

Standard Gaussian Process Can Be Excellent for High-Dimensional Bayesian Optimization
Zhitong Xu, Shandian Zhe
0
0
There has been a long-standing and widespread belief that Bayesian Optimization (BO) with standard Gaussian process (GP), referred to as standard BO, is ineffective in high-dimensional optimization problems. While this belief sounds reasonable, strong empirical evidence is lacking. In this paper, we systematically investigated BO with standard GP regression across a variety of synthetic and real-world benchmark problems for high-dimensional optimization. We found that, surprisingly, when using Mat'ern kernels and Upper Confidence Bound (UCB), standard BO consistently achieves top-tier performance, often outperforming other BO methods specifically designed for high-dimensional optimization. Contrary to the stereotype, we found that standard GP equipped with Mat'ern kernels can serve as a capable surrogate for learning high-dimensional functions. Without strong structural assumptions, BO with standard GP not only excels in high-dimensional optimization but also is robust in accommodating various structures within target functions. Furthermore, with standard GP, achieving promising optimization performance is possible via maximum a posterior (MAP) estimation with diffuse priors or merely maximum likelihood estimation, eliminating the need for expensive Markov-Chain Monte Carlo (MCMC) sampling that might be required by more complex surrogate models. In parallel, we also investigated and analyzed alternative popular settings in running standard BO, which, however, often fail in high-dimensional optimization. This might link to the a few failure cases reported in literature. We thus advocate for a re-evaluation and in-depth study of the potential of standard BO in addressing high-dimensional problems.
5/16/2024

Approximation-Aware Bayesian Optimization
Natalie Maus, Kyurae Kim, Geoff Pleiss, David Eriksson, John P. Cunningham, Jacob R. Gardner
0
0
High-dimensional Bayesian optimization (BO) tasks such as molecular design often require 10,000 function evaluations before obtaining meaningful results. While methods like sparse variational Gaussian processes (SVGPs) reduce computational requirements in these settings, the underlying approximations result in suboptimal data acquisitions that slow the progress of optimization. In this paper we modify SVGPs to better align with the goals of BO: targeting informed data acquisition rather than global posterior fidelity. Using the framework of utility-calibrated variational inference, we unify GP approximation and data acquisition into a joint optimization problem, thereby ensuring optimal decisions under a limited computational budget. Our approach can be used with any decision-theoretic acquisition function and is compatible with trust region methods like TuRBO. We derive efficient joint objectives for the expected improvement and knowledge gradient acquisition functions in both the standard and batch BO settings. Our approach outperforms standard SVGPs on high-dimensional benchmark tasks in control and molecular design.
6/7/2024
🛠️
Principled Preferential Bayesian Optimization
Wenjie Xu, Wenbin Wang, Yuning Jiang, Bratislav Svetozarevic, Colin N. Jones
0
0
We study the problem of preferential Bayesian optimization (BO), where we aim to optimize a black-box function with only preference feedback over a pair of candidate solutions. Inspired by the likelihood ratio idea, we construct a confidence set of the black-box function using only the preference feedback. An optimistic algorithm with an efficient computational method is then developed to solve the problem, which enjoys an information-theoretic bound on the total cumulative regret, a first-of-its-kind for preferential BO. This bound further allows us to design a scheme to report an estimated best solution, with a guaranteed convergence rate. Experimental results on sampled instances from Gaussian processes, standard test functions, and a thermal comfort optimization problem all show that our method stably achieves better or competitive performance as compared to the existing state-of-the-art heuristics, which, however, do not have theoretical guarantees on regret bounds or convergence.
5/30/2024