A Holistic Indicator of Polarization to Measure Online Sexism

0

Sign in to get full access
Overview
- The paper proposes a new "holistic indicator of polarization" to measure online sexism.
- It uses word embeddings and other techniques to quantify language bias and polarization in online discussions.
- The goal is to provide a more comprehensive way to detect and analyze sexist content on digital platforms.
Plain English Explanation
The researchers developed a new way to measure how much sexism is present in online discussions. Rather than just looking at individual words or phrases, their "holistic indicator of polarization" examines the overall language patterns and dynamics to get a more complete picture.
The basic idea is that sexism online often doesn't come in the form of blatant slurs or insults, but can be more subtle - the way certain topics are framed, the tone and sentiment used, the way different groups are positioned relative to each other. By analyzing these broader linguistic trends, the researchers hope to uncover sexist dynamics that might be missed by more narrow approaches.
For example, even if individual comments don't contain obviously sexist language, the researchers could detect if there is a consistent pattern of minimizing women's perspectives, casting them as outsiders, or privileging masculine viewpoints. This gives a more holistic sense of the sexist undercurrents in a discussion.
The researchers believe this kind of comprehensive analysis is essential for truly understanding and addressing online sexism, which can have real and harmful impacts on individuals and communities. Their work provides a more nuanced tool for platforms and researchers to identify and respond to these complex dynamics.
Technical Explanation
The paper outlines a framework for a "holistic indicator of polarization" (HIP) to measure sexism in online discussions. The key components are:
- Lexical Bias: Analyzing the use of gendered language, slurs, and other biased terms.
- Sentiment Bias: Examining the emotional tone and sentiment expressed towards different groups.
- Power Dynamics: Assessing how participants position themselves and others in the discussion hierarchy.
- Argument Framing: Looking at how topics and issues are framed to privilege certain perspectives over others.
The researchers combine various natural language processing techniques, including word embeddings, sentiment analysis, and argumentative discourse analysis, to quantify these different dimensions of linguistic bias and polarization.
By considering these interconnected factors, the HIP provides a more comprehensive picture of sexist dynamics compared to simpler metrics focused on individual words or phrases. The researchers demonstrate the utility of this approach through case studies on online forums and social media discussions.
Critical Analysis
The paper makes a compelling case for the need to move beyond simplistic measures of online hate speech and toxicity towards a more holistic understanding of sexist language and dynamics. The HIP framework represents a significant advancement in this direction, drawing on cutting-edge NLP techniques to capture subtle yet pervasive forms of gender bias.
That said, the authors acknowledge several limitations and avenues for further research. The framework relies heavily on the quality and coverage of the underlying NLP models, which can be biased or inconsistent, especially for less represented demographic groups. There are also open questions around how to best aggregate and interpret the different bias signals measured by the HIP.
Additionally, while the case studies demonstrate the potential value of this approach, more extensive validation across diverse online contexts would be helpful to further establish its robustness and generalizability. The authors also note the need to consider the ethical implications of such measurement tools, particularly around user privacy and the potential for misuse.
Overall, the paper makes an important contribution by pushing the boundaries of how we conceptualize and quantify online sexism. The HIP framework represents a valuable step forward, but continued refinement and responsible deployment will be key to realizing its full potential impact.
Conclusion
This paper presents a novel "holistic indicator of polarization" (HIP) that provides a more comprehensive way to measure and analyze sexist dynamics in online discussions. By considering multiple dimensions of linguistic bias, including lexical, sentiment, power, and framing factors, the HIP offers a nuanced assessment of how gender-based discrimination manifests in digital spaces.
The authors demonstrate the utility of this approach through case studies, showing how it can uncover subtle yet pervasive forms of sexism that may be missed by simpler toxicity or hate speech detection methods. While the framework has some limitations and requires further validation, it represents an important advancement in our ability to understand and address the complex challenges of online misogyny and gender-based abuse.
Ultimately, the HIP framework underscores the need for more holistic, context-aware approaches to combating digital harms. As online platforms and communities continue to grapple with these issues, tools like the HIP can play a valuable role in surfacing critical insights and informing more effective interventions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Holistic Indicator of Polarization to Measure Online Sexism
Vahid Ghafouri, Jose Such, Guillermo Suarez-Tangil
The online trend of the manosphere and feminist discourse on social networks requires a holistic measure of the level of sexism in an online community. This indicator is important for policymakers and moderators of online communities (e.g., subreddits) and computational social scientists, either to revise moderation strategies based on the degree of sexism or to match and compare the temporal sexism across different platforms and communities with real-time events and infer social scientific insights. In this paper, we build a model that can provide a comparable holistic indicator of toxicity targeted toward male and female identity and male and female individuals. Despite previous supervised NLP methods that require annotation of toxic comments at the target level (e.g. annotating comments that are specifically toxic toward women) to detect targeted toxic comments, our indicator uses supervised NLP to detect the presence of toxicity and unsupervised word embedding association test to detect the target automatically. We apply our model to gender discourse communities (e.g., r/TheRedPill, r/MGTOW, r/FemaleDatingStrategy) to detect the level of toxicity toward genders (i.e., sexism). Our results show that our framework accurately and consistently (93% correlation) measures the level of sexism in a community. We finally discuss how our framework can be generalized in the future to measure qualities other than toxicity (e.g. sentiment, humor) toward general-purpose targets and turn into an indicator of different sorts of polarizations.
Read more7/2/2024

0
Sexism Detection on a Data Diet
Rabiraj Bandyopadhyay, Dennis Assenmacher, Jose M. Alonso Moral, Claudia Wagner
There is an increase in the proliferation of online hate commensurate with the rise in the usage of social media. In response, there is also a significant advancement in the creation of automated tools aimed at identifying harmful text content using approaches grounded in Natural Language Processing and Deep Learning. Although it is known that training Deep Learning models require a substantial amount of annotated data, recent line of work suggests that models trained on specific subsets of the data still retain performance comparable to the model that was trained on the full dataset. In this work, we show how we can leverage influence scores to estimate the importance of a data point while training a model and designing a pruning strategy applied to the case of sexism detection. We evaluate the model performance trained on data pruned with different pruning strategies on three out-of-domain datasets and find, that in accordance with other work a large fraction of instances can be removed without significant performance drop. However, we also discover that the strategies for pruning data, previously successful in Natural Language Inference tasks, do not readily apply to the detection of harmful content and instead amplify the already prevalent class imbalance even more, leading in the worst-case to a complete absence of the hateful class.
Read more6/10/2024
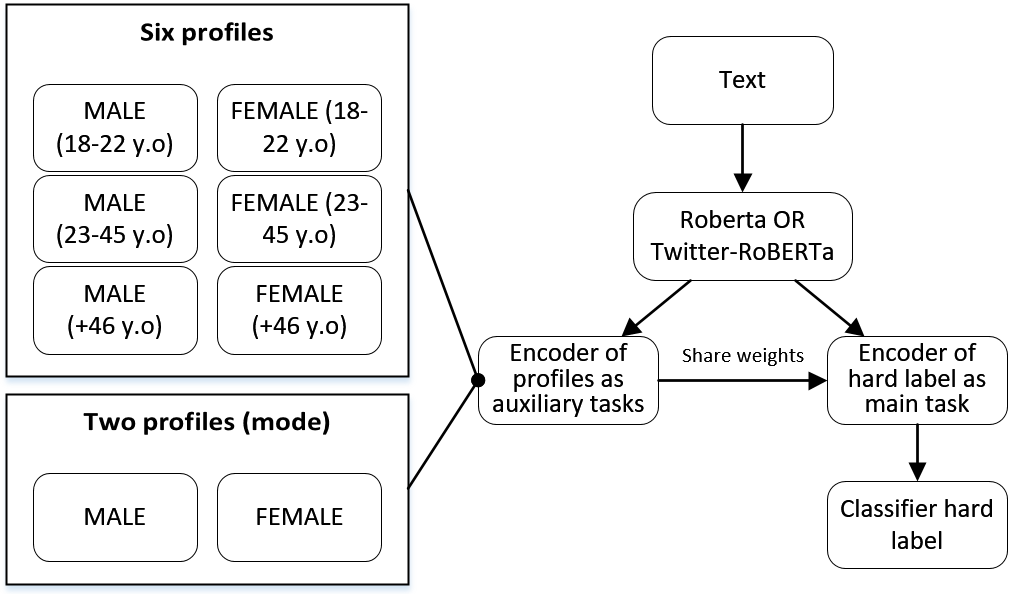
0
A multitask learning framework for leveraging subjectivity of annotators to identify misogyny
Jason Angel, Segun Taofeek Aroyehun, Grigori Sidorov, Alexander Gelbukh
Identifying misogyny using artificial intelligence is a form of combating online toxicity against women. However, the subjective nature of interpreting misogyny poses a significant challenge to model the phenomenon. In this paper, we propose a multitask learning approach that leverages the subjectivity of this task to enhance the performance of the misogyny identification systems. We incorporated diverse perspectives from annotators in our model design, considering gender and age across six profile groups, and conducted extensive experiments and error analysis using two language models to validate our four alternative designs of the multitask learning technique to identify misogynistic content in English tweets. The results demonstrate that incorporating various viewpoints enhances the language models' ability to interpret different forms of misogyny. This research advances content moderation and highlights the importance of embracing diverse perspectives to build effective online moderation systems.
Read more6/26/2024
💬
0
Systematic Offensive Stereotyping (SOS) Bias in Language Models
Fatma Elsafoury
In this paper, we propose a new metric to measure the SOS bias in language models (LMs). Then, we validate the SOS bias and investigate the effectiveness of removing it. Finally, we investigate the impact of the SOS bias in LMs on their performance and fairness on hate speech detection. Our results suggest that all the inspected LMs are SOS biased. And that the SOS bias is reflective of the online hate experienced by marginalized identities. The results indicate that using debias methods from the literature worsens the SOS bias in LMs for some sensitive attributes and improves it for others. Finally, Our results suggest that the SOS bias in the inspected LMs has an impact on their fairness of hate speech detection. However, there is no strong evidence that the SOS bias has an impact on the performance of hate speech detection.
Read more4/29/2024