Holistic Memory Diversification for Incremental Learning in Growing Graphs

0

Sign in to get full access
Overview
- The paper proposes a novel approach called "Holistic Memory Diversification" for incremental learning in growing graphs.
- Incremental learning in growing graphs is an important but challenging problem, where new nodes and edges are continuously added to the graph, and the model needs to adapt to these changes while maintaining performance on previous tasks.
- The authors address this challenge by introducing a memory diversification strategy that encourages the model to learn diverse representations, allowing it to adapt to changes in the graph structure while retaining knowledge from previous tasks.
Plain English Explanation
The paper presents a new technique for "incremental learning" on growing graph data. Incremental learning is when a machine learning model has to continuously learn and update itself as new information is added, without forgetting what it has learned before.
In this case, the data is in the form of a graph, which is a way of representing connections between different elements. The graph is continuously growing, with new nodes (elements) and edges (connections) being added over time. The challenge is to update the model to account for these changes, while also retaining the knowledge it has gained from previous versions of the graph.
The key idea behind the proposed approach, called "Holistic Memory Diversification," is to encourage the model to learn diverse representations of the graph data. This means the model doesn't just memorize specific patterns, but instead develops a more general understanding that can adapt to new additions to the graph. The authors achieve this by incorporating a memory diversification strategy into the model's training process.
By using this holistic memory diversification approach, the model can better handle the evolving nature of the graph data, continuously updating its knowledge while still maintaining performance on previous tasks. This can be useful in a wide range of applications, such as social network analysis, recommendation systems, and knowledge graph management.
Technical Explanation
The paper formulates the problem of incremental learning in growing graphs as a graph classification task, where the model needs to classify each node in the graph based on its features and the graph structure. The authors propose a novel approach called "Holistic Memory Diversification" to address this challenge.
The key components of the proposed method are:
- Graph Encoder: A graph neural network (GNN) that encodes the input graph into node representations.
- Memory Bank: A memory module that stores previously learned representations to be used in subsequent incremental learning steps.
- Memory Diversification: A mechanism that encourages the model to learn diverse representations in the memory bank, enabling better adaptation to changes in the graph structure.
The memory diversification strategy is implemented by introducing a novel loss function that encourages the model to learn representations that are both informative for the current task and dissimilar to the representations already stored in the memory bank. This helps the model develop a more comprehensive understanding of the graph data, allowing it to adapt to new additions while retaining knowledge from previous tasks.
The authors evaluate their approach on several real-world graph datasets and compare it to state-of-the-art incremental learning methods. The results demonstrate that the Holistic Memory Diversification approach outperforms existing techniques, particularly in scenarios with significant changes to the graph structure over time.
Critical Analysis
The paper addresses an important and challenging problem in the field of graph-based machine learning, and the proposed Holistic Memory Diversification approach shows promising results. However, there are a few aspects that could be further explored or addressed:
-
Scalability: The authors evaluate their method on relatively small-scale graph datasets. It would be valuable to assess the scalability of the approach to larger, more complex graph structures, as real-world applications may involve much larger and more dynamic graphs.
-
Interpretability: The paper does not provide much insight into the internal workings of the memory diversification mechanism and how it affects the model's learning process. Incorporating more interpretability could help researchers and practitioners better understand the strengths and limitations of the approach.
-
Generalization to other domains: While the paper focuses on graph-based incremental learning, the principles of holistic memory diversification may be applicable to other domains, such as continual learning or multi-task learning. Exploring the broader applicability of the proposed techniques could further demonstrate their significance and impact.
Conclusion
The "Holistic Memory Diversification" approach presented in this paper offers a promising solution to the problem of incremental learning in growing graphs. By encouraging the model to learn diverse representations, the method can better adapt to changes in the graph structure while retaining knowledge from previous tasks. This has important implications for a wide range of applications that rely on graph-based data, such as social network analysis, recommendation systems, and knowledge graph management.
While the paper demonstrates the effectiveness of the proposed technique, there are opportunities to further explore its scalability, interpretability, and potential for broader applicability. Continued research in this direction could lead to even more robust and adaptable machine learning models for working with evolving graph-structured data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Holistic Memory Diversification for Incremental Learning in Growing Graphs
Ziyue Qiao, Junren Xiao, Qingqiang Sun, Meng Xiao, Hui Xiong
This paper addresses the challenge of incremental learning in growing graphs with increasingly complex tasks. The goal is to continually train a graph model to handle new tasks while retaining its inference ability on previous tasks. Existing methods usually neglect the importance of memory diversity, limiting in effectively selecting high-quality memory from previous tasks and remembering broad previous knowledge within the scarce memory on graphs. To address that, we introduce a novel holistic Diversified Memory Selection and Generation (DMSG) framework for incremental learning in graphs, which first introduces a buffer selection strategy that considers both intra-class and inter-class diversities, employing an efficient greedy algorithm for sampling representative training nodes from graphs into memory buffers after learning each new task. Then, to adequately rememorize the knowledge preserved in the memory buffer when learning new tasks, we propose a diversified memory generation replay method. This method first utilizes a variational layer to generate the distribution of buffer node embeddings and sample synthesized ones for replaying. Furthermore, an adversarial variational embedding learning method and a reconstruction-based decoder are proposed to maintain the integrity and consolidate the generalization of the synthesized node embeddings, respectively. Finally, we evaluate our model on node classification tasks involving increasing class numbers. Extensive experimental results on publicly accessible datasets demonstrate the superiority of DMSG over state-of-the-art methods.
Read more6/12/2024
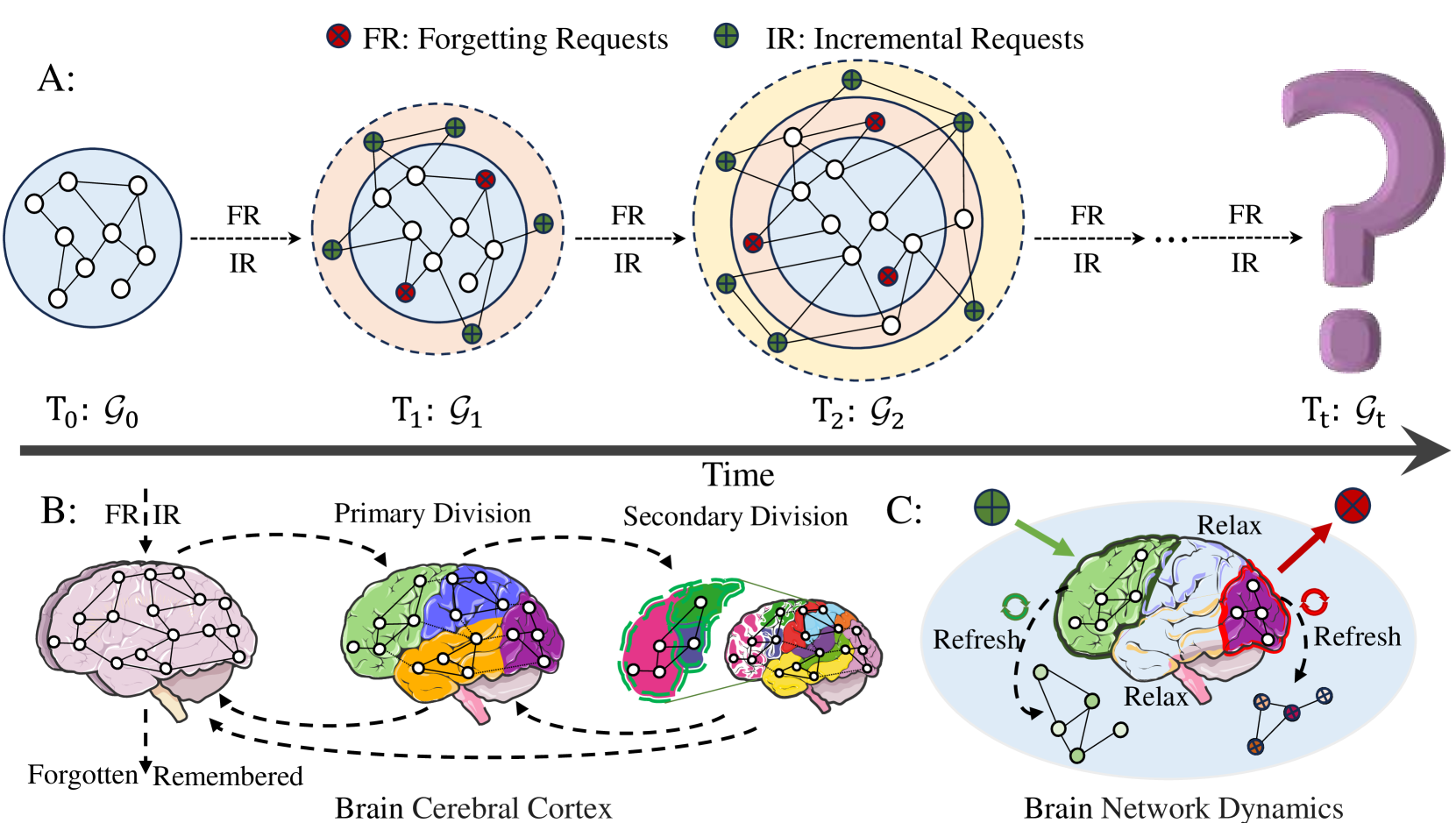
0
Graph Memory Learning: Imitating Lifelong Remembering and Forgetting of Brain Networks
Jiaxing Miao, Liang Hu, Qi Zhang, Longbing Cao
Graph data in real-world scenarios undergo rapid and frequent changes, making it challenging for existing graph models to effectively handle the continuous influx of new data and accommodate data withdrawal requests. The approach to frequently retraining graph models is resource intensive and impractical. To address this pressing challenge, this paper introduces a new concept of graph memory learning. Its core idea is to enable a graph model to selectively remember new knowledge but forget old knowledge. Building on this approach, the paper presents a novel graph memory learning framework - Brain-inspired Graph Memory Learning (BGML), inspired by brain network dynamics and function-structure coupling strategies. BGML incorporates a multi-granular hierarchical progressive learning mechanism rooted in feature graph grain learning to mitigate potential conflict between memorization and forgetting in graph memory learning. This mechanism allows for a comprehensive and multi-level perception of local details within evolving graphs. In addition, to tackle the issue of unreliable structures in newly added incremental information, the paper introduces an information self-assessment ownership mechanism. This mechanism not only facilitates the propagation of incremental information within the model but also effectively preserves the integrity of past experiences. We design five types of graph memory learning tasks: regular, memory, unlearning, data-incremental, and class-incremental to evaluate BGML. Its excellent performance is confirmed through extensive experiments on multiple real-world node classification datasets.
Read more7/30/2024

0
Topology-aware Embedding Memory for Continual Learning on Expanding Networks
Xikun Zhang, Dongjin Song, Yixin Chen, Dacheng Tao
Memory replay based techniques have shown great success for continual learning with incrementally accumulated Euclidean data. Directly applying them to continually expanding networks, however, leads to the potential memory explosion problem due to the need to buffer representative nodes and their associated topological neighborhood structures. To this end, we systematically analyze the key challenges in the memory explosion problem, and present a general framework, textit{i.e.}, Parameter Decoupled Graph Neural Networks (PDGNNs) with Topology-aware Embedding Memory (TEM), to tackle this issue. The proposed framework not only reduces the memory space complexity from $mathcal{O}(nd^L)$ to $mathcal{O}(n)$~footnote{$n$: memory budget, $d$: average node degree, $L$: the radius of the GNN receptive field}, but also fully utilizes the topological information for memory replay. Specifically, PDGNNs decouple trainable parameters from the computation ego-subnetwork via textit{Topology-aware Embeddings} (TEs), which compress ego-subnetworks into compact vectors (textit{i.e.}, TEs) to reduce the memory consumption. Based on this framework, we discover a unique textit{pseudo-training effect} in continual learning on expanding networks and this effect motivates us to develop a novel textit{coverage maximization sampling} strategy that can enhance the performance with a tight memory budget. Thorough empirical studies demonstrate that, by tackling the memory explosion problem and incorporating topological information into memory replay, PDGNNs with TEM significantly outperform state-of-the-art techniques, especially in the challenging class-incremental setting.
Read more7/2/2024

0
Infinite dSprites for Disentangled Continual Learning: Separating Memory Edits from Generalization
Sebastian Dziadzio, c{C}au{g}atay Y{i}ld{i}z, Gido M. van de Ven, Tomasz Trzci'nski, Tinne Tuytelaars, Matthias Bethge
The ability of machine learning systems to learn continually is hindered by catastrophic forgetting, the tendency of neural networks to overwrite previously acquired knowledge when learning a new task. Existing methods mitigate this problem through regularization, parameter isolation, or rehearsal, but they are typically evaluated on benchmarks comprising only a handful of tasks. In contrast, humans are able to learn over long time horizons in dynamic, open-world environments, effortlessly memorizing unfamiliar objects and reliably recognizing them under various transformations. To make progress towards closing this gap, we introduce Infinite dSprites, a parsimonious tool for creating continual classification and disentanglement benchmarks of arbitrary length and with full control over generative factors. We show that over a sufficiently long time horizon, the performance of all major types of continual learning methods deteriorates on this simple benchmark. This result highlights an important and previously overlooked aspect of continual learning: given a finite modelling capacity and an arbitrarily long learning horizon, efficient learning requires memorizing class-specific information and accumulating knowledge about general mechanisms. In a simple setting with direct supervision on the generative factors, we show how learning class-agnostic transformations offers a way to circumvent catastrophic forgetting and improve classification accuracy over time. Our approach sets the stage for continual learning over hundreds of tasks with explicit control over memorization and forgetting, emphasizing open-set classification and one-shot generalization.
Read more7/31/2024