Topology-aware Embedding Memory for Continual Learning on Expanding Networks

0

Sign in to get full access
Overview
- The paper proposes a novel approach called Topology-aware Embedding Memory (TEM) for continual learning on expanding graph-structured data.
- TEM aims to effectively learn and adapt to changes in graph topology by maintaining a memory module that captures the topological structure of the graph.
- The method is designed to address the challenges of continual learning on dynamic, growing graphs, where the graph structure and node/edge attributes can change over time.
Plain English Explanation
The paper introduces a new technique called Topology-aware Embedding Memory (TEM) that helps machine learning models learn from graph-structured data that is constantly changing and expanding.
Graphs are a common way to represent complex, interconnected data, such as social networks, transportation systems, or chemical compounds. However, these graphs can often grow and change over time, as new nodes (e.g., people, cities, molecules) and edges (e.g., friendships, roads, bonds) are added.
Traditional machine learning models can struggle to adapt to these changes, as they are not designed to handle the dynamic nature of graph data. TEM aims to address this problem by maintaining a special "memory" module that keeps track of the topological structure of the graph.
This memory module allows the model to learn how the graph is changing and evolve its understanding accordingly. For example, if new connections are formed between nodes in a social network, the model can update its knowledge of the network's structure to make better predictions about user behavior or relationships.
By incorporating this topological awareness, TEM can more effectively learn and adapt to the continual changes in graph-structured data, which is an important capability for many real-world applications.
Technical Explanation
The key idea behind Topology-aware Embedding Memory (TEM) is to maintain a dedicated memory module that captures the topological structure of the graph. This memory module works in conjunction with the main machine learning model to enable continual learning on expanding graphs.
At the core of TEM is a graph neural network (GNN) that learns node and edge representations. To preserve knowledge about the evolving graph structure, TEM uses a memory bank to store past topological embeddings. When new nodes or edges are added, the model updates the memory bank to reflect the changed graph topology.
During training, the model alternates between two phases: a learning phase, where it updates the GNN parameters based on new data, and a memory update phase, where it incorporates the changed graph structure into the memory bank. This allows the model to continuously adapt its understanding of the graph as it grows and changes over time.
The authors also introduce several techniques to improve the efficiency and effectiveness of TEM, such as:
- Topology-aware Data Augmentation: Generating new training samples by perturbing the graph structure in a topologically-consistent way, which helps the model learn more robust representations.
- Holistic Memory Diversification: Actively managing the memory bank to maintain a diverse set of topological embeddings, preventing catastrophic forgetting of past graph structures.
- Gaussian Embedding for Temporal Networks: Using a Gaussian distribution to represent node/edge embeddings, which can better capture the uncertainty and dynamics inherent in temporal graph data.
Through extensive experiments on both synthetic and real-world datasets, the authors demonstrate that TEM outperforms various baseline methods in terms of continual learning performance on expanding graphs.
Critical Analysis
The Topology-aware Embedding Memory (TEM) approach proposed in the paper is a promising solution for the challenging problem of continual learning on dynamic, growing graph-structured data. By explicitly modeling the evolving topological structure of the graph, TEM can adapt its understanding of the data as it changes over time, addressing a key limitation of many existing machine learning models.
One potential limitation of the research is the scope of the experiments. While the authors evaluate TEM on a range of datasets, the graphs used may not fully capture the complexity and diversity of real-world graphs encountered in practice. Further testing on larger, more heterogeneous graph datasets would help validate the scalability and robustness of the approach.
Additionally, the paper does not deeply explore the potential trade-offs or drawbacks of the proposed techniques, such as the computational overhead of maintaining the topological memory module or the sensitivity of the method to hyperparameter tuning. A more thorough analysis of these aspects would provide a more comprehensive understanding of the practical considerations and limitations of TEM.
That said, the core ideas behind TEM, such as topology-aware data augmentation, Gaussian embedding for temporal networks, and holistic memory diversification, are well-grounded in the literature and show promise for advancing the state-of-the-art in continual learning on dynamic graphs. Further research building upon these concepts could lead to even more robust and efficient solutions for memory-efficient graph neural networks.
Conclusion
The Topology-aware Embedding Memory (TEM) approach presented in this paper represents an important step forward in addressing the challenge of continual learning on expanding graph-structured data. By maintaining a dedicated memory module that captures the evolving topological structure of the graph, TEM can adapt its understanding of the data as it changes over time, overcoming a key limitation of traditional machine learning models.
The technical innovations introduced in the paper, such as topology-aware data augmentation, Gaussian embedding for temporal networks, and holistic memory diversification, demonstrate the value of incorporating topological awareness into the learning process. These advancements have the potential to unlock new applications and use cases for graph-based machine learning, particularly in domains where the underlying data is constantly evolving.
While further research is needed to fully explore the practical implications and limitations of TEM, this work represents a significant contribution to the field of continual learning and graph neural networks. As the volume and complexity of graph-structured data continue to grow, solutions like TEM will become increasingly important for developing robust, adaptable machine learning systems that can keep pace with the changing world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Topology-aware Embedding Memory for Continual Learning on Expanding Networks
Xikun Zhang, Dongjin Song, Yixin Chen, Dacheng Tao
Memory replay based techniques have shown great success for continual learning with incrementally accumulated Euclidean data. Directly applying them to continually expanding networks, however, leads to the potential memory explosion problem due to the need to buffer representative nodes and their associated topological neighborhood structures. To this end, we systematically analyze the key challenges in the memory explosion problem, and present a general framework, textit{i.e.}, Parameter Decoupled Graph Neural Networks (PDGNNs) with Topology-aware Embedding Memory (TEM), to tackle this issue. The proposed framework not only reduces the memory space complexity from $mathcal{O}(nd^L)$ to $mathcal{O}(n)$~footnote{$n$: memory budget, $d$: average node degree, $L$: the radius of the GNN receptive field}, but also fully utilizes the topological information for memory replay. Specifically, PDGNNs decouple trainable parameters from the computation ego-subnetwork via textit{Topology-aware Embeddings} (TEs), which compress ego-subnetworks into compact vectors (textit{i.e.}, TEs) to reduce the memory consumption. Based on this framework, we discover a unique textit{pseudo-training effect} in continual learning on expanding networks and this effect motivates us to develop a novel textit{coverage maximization sampling} strategy that can enhance the performance with a tight memory budget. Thorough empirical studies demonstrate that, by tackling the memory explosion problem and incorporating topological information into memory replay, PDGNNs with TEM significantly outperform state-of-the-art techniques, especially in the challenging class-incremental setting.
Read more7/2/2024

0
Holistic Memory Diversification for Incremental Learning in Growing Graphs
Ziyue Qiao, Junren Xiao, Qingqiang Sun, Meng Xiao, Hui Xiong
This paper addresses the challenge of incremental learning in growing graphs with increasingly complex tasks. The goal is to continually train a graph model to handle new tasks while retaining its inference ability on previous tasks. Existing methods usually neglect the importance of memory diversity, limiting in effectively selecting high-quality memory from previous tasks and remembering broad previous knowledge within the scarce memory on graphs. To address that, we introduce a novel holistic Diversified Memory Selection and Generation (DMSG) framework for incremental learning in graphs, which first introduces a buffer selection strategy that considers both intra-class and inter-class diversities, employing an efficient greedy algorithm for sampling representative training nodes from graphs into memory buffers after learning each new task. Then, to adequately rememorize the knowledge preserved in the memory buffer when learning new tasks, we propose a diversified memory generation replay method. This method first utilizes a variational layer to generate the distribution of buffer node embeddings and sample synthesized ones for replaying. Furthermore, an adversarial variational embedding learning method and a reconstruction-based decoder are proposed to maintain the integrity and consolidate the generalization of the synthesized node embeddings, respectively. Finally, we evaluate our model on node classification tasks involving increasing class numbers. Extensive experimental results on publicly accessible datasets demonstrate the superiority of DMSG over state-of-the-art methods.
Read more6/12/2024
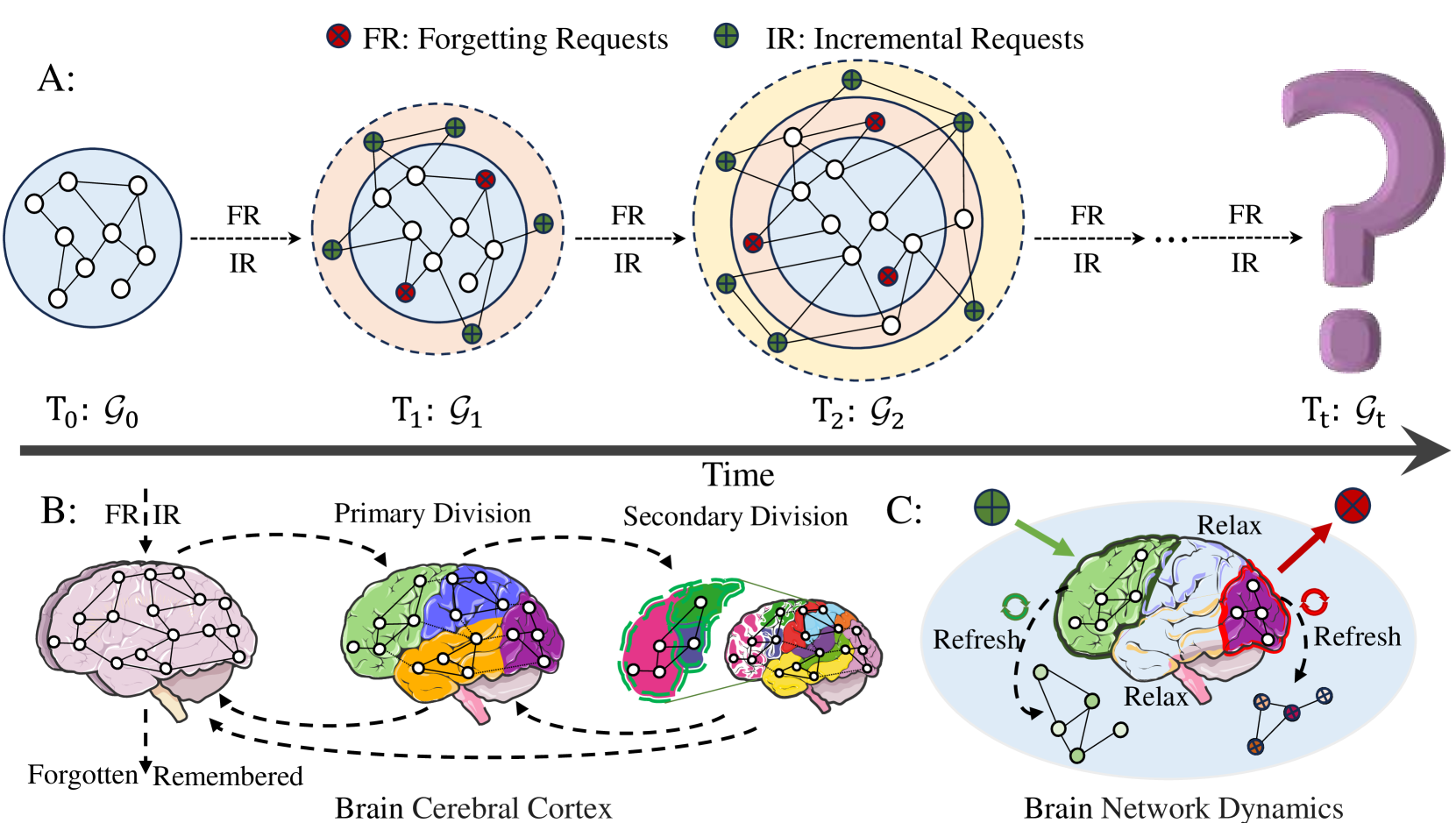
0
Graph Memory Learning: Imitating Lifelong Remembering and Forgetting of Brain Networks
Jiaxing Miao, Liang Hu, Qi Zhang, Longbing Cao
Graph data in real-world scenarios undergo rapid and frequent changes, making it challenging for existing graph models to effectively handle the continuous influx of new data and accommodate data withdrawal requests. The approach to frequently retraining graph models is resource intensive and impractical. To address this pressing challenge, this paper introduces a new concept of graph memory learning. Its core idea is to enable a graph model to selectively remember new knowledge but forget old knowledge. Building on this approach, the paper presents a novel graph memory learning framework - Brain-inspired Graph Memory Learning (BGML), inspired by brain network dynamics and function-structure coupling strategies. BGML incorporates a multi-granular hierarchical progressive learning mechanism rooted in feature graph grain learning to mitigate potential conflict between memorization and forgetting in graph memory learning. This mechanism allows for a comprehensive and multi-level perception of local details within evolving graphs. In addition, to tackle the issue of unreliable structures in newly added incremental information, the paper introduces an information self-assessment ownership mechanism. This mechanism not only facilitates the propagation of incremental information within the model but also effectively preserves the integrity of past experiences. We design five types of graph memory learning tasks: regular, memory, unlearning, data-incremental, and class-incremental to evaluate BGML. Its excellent performance is confirmed through extensive experiments on multiple real-world node classification datasets.
Read more7/30/2024
🏷️
0
On the Limitation and Experience Replay for GNNs in Continual Learning
Junwei Su, Difan Zou, Chuan Wu
Continual learning seeks to empower models to progressively acquire information from a sequence of tasks. This approach is crucial for many real-world systems, which are dynamic and evolve over time. Recent research has witnessed a surge in the exploration of Graph Neural Networks (GNN) in Node-wise Graph Continual Learning (NGCL), a practical yet challenging paradigm involving the continual training of a GNN on node-related tasks. Despite recent advancements in continual learning strategies for GNNs in NGCL, a thorough theoretical understanding, especially regarding its learnability, is lacking. Learnability concerns the existence of a learning algorithm that can produce a good candidate model from the hypothesis/weight space, which is crucial for model selection in NGCL development. This paper introduces the first theoretical exploration of the learnability of GNN in NGCL, revealing that learnability is heavily influenced by structural shifts due to the interconnected nature of graph data. Specifically, GNNs may not be viable for NGCL under significant structural changes, emphasizing the need to manage structural shifts. To mitigate the impact of structural shifts, we propose a novel experience replay method termed Structure-Evolution-Aware Experience Replay (SEA-ER). SEA-ER features an innovative experience selection strategy that capitalizes on the topological awareness of GNNs, alongside a unique replay strategy that employs structural alignment to effectively counter catastrophic forgetting and diminish the impact of structural shifts on GNNs in NGCL. Our extensive experiments validate our theoretical insights and the effectiveness of SEA-ER.
Read more7/10/2024