HoloDreamer: Holistic 3D Panoramic World Generation from Text Descriptions

0

Sign in to get full access
Overview
- This paper presents HoloDreamer, a novel system that can generate holistic 3D panoramic worlds from text descriptions.
- It uses a text-to-3D approach combined with 3D Gaussian Splatting to create detailed, realistic 360-degree panoramic scenes.
- The system can generate both indoor and outdoor environments based on natural language input, enabling text-driven 3D scene generation and inpainting.
- The generated panoramas can be viewed in 4K resolution and even animated over time.
Plain English Explanation
HoloDreamer is a system that can take text descriptions, like "a cozy cabin in a snowy forest," and turn them into fully realized 3D panoramic worlds. These panoramic scenes are like immersive 360-degree virtual environments that you can look around in.
The key innovation is how HoloDreamer combines two main techniques. First, it uses "text-to-3D" methods to translate the text description into an initial 3D scene. Then, it applies "3D Gaussian Splatting" to add realistic details and lighting to turn that initial 3D scene into a high-quality, photorealistic panorama.
This allows HoloDreamer to generate detailed, lifelike environments based on just a sentence or two of text input. Whether it's an outdoor landscape or an indoor room, the system can construct a full 360-degree virtual world that feels authentic and immersive.
The generated panoramas can even be viewed in high 4K resolution and animated over time, giving a true sense of depth and movement to the virtual scenes. This opens up new possibilities for applications like virtual tourism, interactive storytelling, and more.
Technical Explanation
HoloDreamer's architecture consists of several key components. First, it uses a text-to-3D module to translate the input text description into an initial 3D scene representation. This module leverages large language models and 3D shape priors to construct a basic 3D mesh based on the semantics of the text.
Next, the system applies 3D Gaussian Splatting to add detailed textures, lighting, and other visual elements to the 3D scene. This involves projecting 3D data points (called "splats") onto a 360-degree panoramic image, creating a realistic and immersive final output.
The overall text-driven 3D scene generation and inpainting pipeline allows HoloDreamer to construct both indoor and outdoor environments from natural language inputs. The generated panoramas can then be rendered at 4K resolution and even animated over time for a truly immersive experience.
Critical Analysis
The paper acknowledges some limitations of HoloDreamer, such as the challenges in accurately representing complex object interactions and dynamic scenes. Additionally, the system currently relies on a fixed set of 3D shape priors, which may limit its ability to generate highly novel or unconventional environments.
Further research could explore ways to expand the system's generative capabilities, such as incorporating more advanced language understanding or incorporating real-world 3D data. Evaluation of the system's performance across a wider range of text inputs and use cases would also help assess its practical utility.
Overall, HoloDreamer represents an impressive step forward in the field of text-to-3D generation, demonstrating the potential for language-driven virtual world creation. As the underlying technologies continue to evolve, systems like HoloDreamer may become increasingly important for applications in gaming, education, tourism, and beyond.
Conclusion
HoloDreamer is a novel system that can generate highly detailed, photorealistic 3D panoramic worlds from simple text descriptions. By combining text-to-3D methods with 3D Gaussian Splatting, the system is able to construct immersive virtual environments that can be viewed in high resolution and even animated.
This technological breakthrough opens up new possibilities for interactive storytelling, virtual tourism, and other applications that rely on realistic, language-driven 3D content generation. As the underlying techniques continue to advance, systems like HoloDreamer may become increasingly valuable tools for creating engaging, immersive digital experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HoloDreamer: Holistic 3D Panoramic World Generation from Text Descriptions
Haiyang Zhou, Xinhua Cheng, Wangbo Yu, Yonghong Tian, Li Yuan
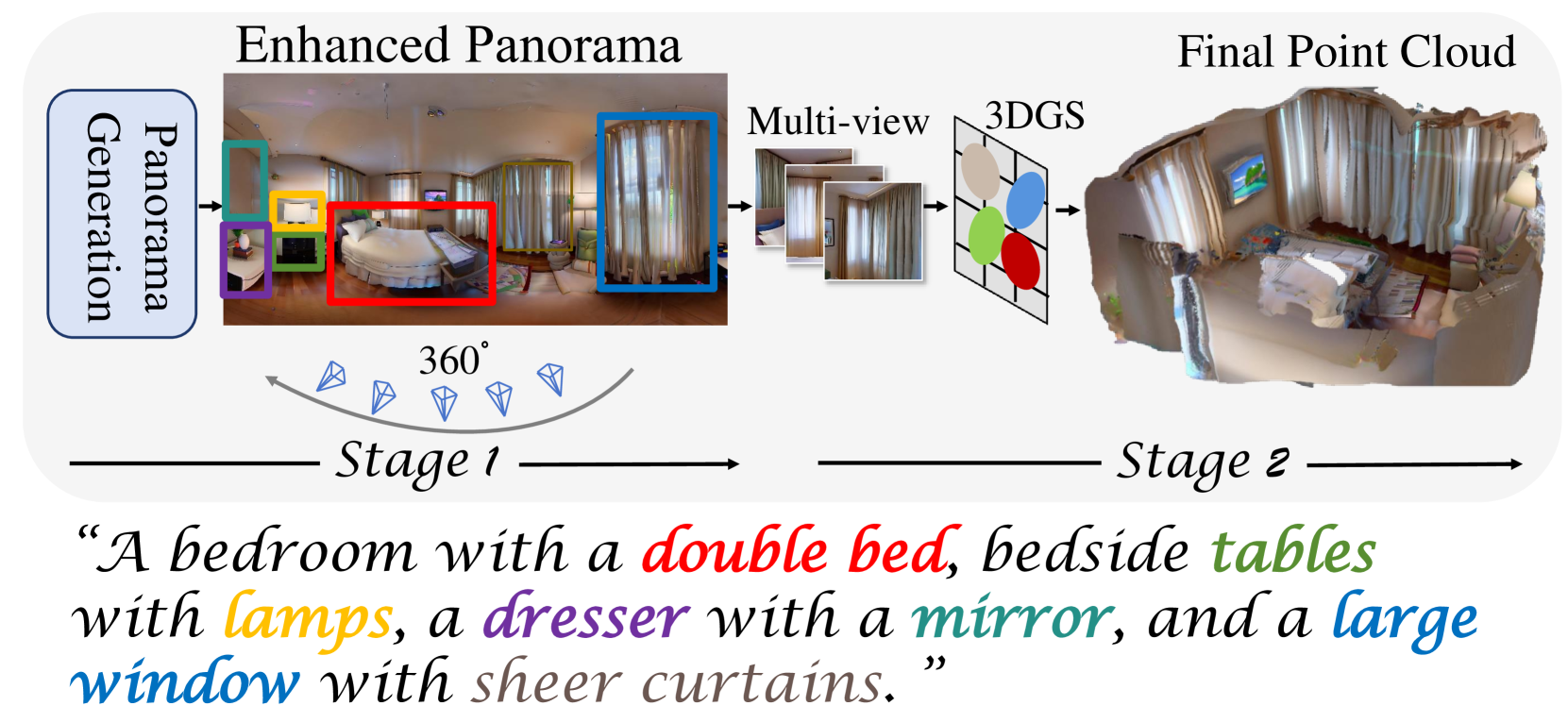
3D scene generation is in high demand across various domains, including virtual reality, gaming, and the film industry. Owing to the powerful generative capabilities of text-to-image diffusion models that provide reliable priors, the creation of 3D scenes using only text prompts has become viable, thereby significantly advancing researches in text-driven 3D scene generation. In order to obtain multiple-view supervision from 2D diffusion models, prevailing methods typically employ the diffusion model to generate an initial local image, followed by iteratively outpainting the local image using diffusion models to gradually generate scenes. Nevertheless, these outpainting-based approaches prone to produce global inconsistent scene generation results without high degree of completeness, restricting their broader applications. To tackle these problems, we introduce HoloDreamer, a framework that first generates high-definition panorama as a holistic initialization of the full 3D scene, then leverage 3D Gaussian Splatting (3D-GS) to quickly reconstruct the 3D scene, thereby facilitating the creation of view-consistent and fully enclosed 3D scenes. Specifically, we propose Stylized Equirectangular Panorama Generation, a pipeline that combines multiple diffusion models to enable stylized and detailed equirectangular panorama generation from complex text prompts. Subsequently, Enhanced Two-Stage Panorama Reconstruction is introduced, conducting a two-stage optimization of 3D-GS to inpaint the missing region and enhance the integrity of the scene. Comprehensive experiments demonstrated that our method outperforms prior works in terms of overall visual consistency and harmony as well as reconstruction quality and rendering robustness when generating fully enclosed scenes.
Read more7/23/2024
0
SceneDreamer360: Text-Driven 3D-Consistent Scene Generation with Panoramic Gaussian Splatting
Wenrui Li, Yapeng Mi, Fucheng Cai, Zhe Yang, Wangmeng Zuo, Xingtao Wang, Xiaopeng Fan
Text-driven 3D scene generation has seen significant advancements recently. However, most existing methods generate single-view images using generative models and then stitch them together in 3D space. This independent generation for each view often results in spatial inconsistency and implausibility in the 3D scenes. To address this challenge, we proposed a novel text-driven 3D-consistent scene generation model: SceneDreamer360. Our proposed method leverages a text-driven panoramic image generation model as a prior for 3D scene generation and employs 3D Gaussian Splatting (3DGS) to ensure consistency across multi-view panoramic images. Specifically, SceneDreamer360 enhances the fine-tuned Panfusion generator with a three-stage panoramic enhancement, enabling the generation of high-resolution, detail-rich panoramic images. During the 3D scene construction, a novel point cloud fusion initialization method is used, producing higher quality and spatially consistent point clouds. Our extensive experiments demonstrate that compared to other methods, SceneDreamer360 with its panoramic image generation and 3DGS can produce higher quality, spatially consistent, and visually appealing 3D scenes from any text prompt. Our codes are available at url{https://github.com/liwrui/SceneDreamer360}.
Read more8/27/2024

0
DreamScene360: Unconstrained Text-to-3D Scene Generation with Panoramic Gaussian Splatting
Shijie Zhou, Zhiwen Fan, Dejia Xu, Haoran Chang, Pradyumna Chari, Tejas Bharadwaj, Suya You, Zhangyang Wang, Achuta Kadambi
The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary flat (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{circ}$ perspective, providing an enhanced immersive experience over existing techniques. Project website at: http://dreamscene360.github.io/
Read more7/26/2024

0
RealmDreamer: Text-Driven 3D Scene Generation with Inpainting and Depth Diffusion
Jaidev Shriram, Alex Trevithick, Lingjie Liu, Ravi Ramamoorthi
We introduce RealmDreamer, a technique for generation of general forward-facing 3D scenes from text descriptions. Our technique optimizes a 3D Gaussian Splatting representation to match complex text prompts. We initialize these splats by utilizing the state-of-the-art text-to-image generators, lifting their samples into 3D, and computing the occlusion volume. We then optimize this representation across multiple views as a 3D inpainting task with image-conditional diffusion models. To learn correct geometric structure, we incorporate a depth diffusion model by conditioning on the samples from the inpainting model, giving rich geometric structure. Finally, we finetune the model using sharpened samples from image generators. Notably, our technique does not require video or multi-view data and can synthesize a variety of high-quality 3D scenes in different styles, consisting of multiple objects. Its generality additionally allows 3D synthesis from a single image.
Read more4/11/2024