HoneyBee: A Scalable Modular Framework for Creating Multimodal Oncology Datasets with Foundational Embedding Models

0
🐍
Sign in to get full access
Overview
- Developing accurate machine learning models for oncology requires large, high-quality multimodal datasets, but creating such datasets is challenging due to the complexity and heterogeneity of medical data.
- To address this, the authors introduce HoneyBee, a scalable modular framework for building multimodal oncology datasets that leverages foundational models to generate representative embeddings.
- HoneyBee integrates various data modalities, including clinical records, imaging data, and patient outcomes, and uses data preprocessing techniques and transformer-based architectures to generate embeddings.
- The generated embeddings are stored in a structured format for accessibility, and vector databases enable efficient querying and retrieval for machine learning applications.
- The framework is designed to be extensible to other medical domains and aims to accelerate oncology research by providing high-quality, machine learning-ready datasets.
Plain English Explanation
Building accurate machine learning models for cancer (oncology) requires large, high-quality datasets that include different types of medical data, like medical records, medical images, and patient outcomes. However, creating these datasets is difficult because medical data is complex and comes in many different forms.
To solve this problem, the researchers created a new system called HoneyBee. HoneyBee is a flexible framework that can be used to build multimodal oncology datasets. It takes various types of medical data and uses advanced techniques, like transformer-based architectures, to extract key features and relationships from the raw data. These extracted features are stored in a structured format that makes them easy to use for machine learning.
The HoneyBee framework is designed to be expandable to other medical fields, not just oncology. By providing high-quality, machine learning-ready datasets, HoneyBee aims to accelerate oncology research and help develop more accurate cancer-related machine learning models.
Technical Explanation
HoneyBee integrates various data modalities, including clinical records, imaging data, and patient outcomes. It employs data preprocessing techniques and transformer-based architectures to generate embeddings that capture the essential features and relationships within the raw medical data. The generated embeddings are stored in a structured format using Hugging Face datasets and PyTorch dataloaders for accessibility, and vector databases enable efficient querying and retrieval for machine learning applications.
The researchers demonstrate the effectiveness of HoneyBee through experiments assessing the quality and representativeness of the generated embeddings. The framework is designed to be extensible to other medical domains and aims to accelerate oncology research by providing high-quality, machine learning-ready datasets.
Critical Analysis
The paper provides a comprehensive overview of the HoneyBee framework and demonstrates its potential to address the challenges of creating large-scale, high-quality multimodal datasets for oncology research. However, the authors do not discuss any potential limitations or caveats of their approach.
For example, the paper does not address how HoneyBee handles the privacy and ethical concerns associated with using sensitive medical data. Additionally, the authors do not discuss the computational resources required to run the framework or the potential biases that may be introduced by the data preprocessing and embedding generation techniques.
Further research is needed to evaluate the long-term effectiveness of HoneyBee in accelerating oncology research and supporting the development of accurate machine learning models. Reproducibility and generalizability of the results across different medical domains should also be assessed.
Conclusion
The HoneyBee framework represents a promising step towards addressing the challenge of creating large-scale, high-quality multimodal datasets for oncology research. By leveraging foundational models and advanced data processing techniques, HoneyBee can generate representative embeddings that capture the essential features and relationships within complex medical data. This, in turn, can accelerate the development of accurate machine learning models for cancer diagnosis, treatment, and management.
While the paper demonstrates the potential of HoneyBee, further research is needed to address the framework's limitations and ensure its long-term sustainability and impact on the field of oncology. As an ongoing open-source effort, HoneyBee's continued development and adoption by the research community will be crucial in realizing its goal of providing high-quality, machine learning-ready datasets to drive advancements in cancer research and care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
HoneyBee: A Scalable Modular Framework for Creating Multimodal Oncology Datasets with Foundational Embedding Models
Aakash Tripathi, Asim Waqas, Yasin Yilmaz, Ghulam Rasool
Developing accurate machine learning models for oncology requires large-scale, high-quality multimodal datasets. However, creating such datasets remains challenging due to the complexity and heterogeneity of medical data. To address this challenge, we introduce HoneyBee, a scalable modular framework for building multimodal oncology datasets that leverages foundation models to generate representative embeddings. HoneyBee integrates various data modalities, including clinical diagnostic and pathology imaging data, medical notes, reports, records, and molecular data. It employs data preprocessing techniques and foundation models to generate embeddings that capture the essential features and relationships within the raw medical data. The generated embeddings are stored in a structured format using Hugging Face datasets and PyTorch dataloaders for accessibility. Vector databases enable efficient querying and retrieval for machine learning applications. We demonstrate the effectiveness of HoneyBee through experiments assessing the quality and representativeness of these embeddings. The framework is designed to be extensible to other medical domains and aims to accelerate oncology research by providing high-quality, machine learning-ready datasets. HoneyBee is an ongoing open-source effort, and the code, datasets, and models are available at the project repository.
Read more6/14/2024

0
UrBAN: Urban Beehive Acoustics and PheNotyping Dataset
Mahsa Abdollahi, Yi Zhu, Heitor R. Guimar~aes, Nico Coallier, S'egol`ene Maucourt, Pierre Giovenazzo, Tiago H. Falk
In this paper, we present a multimodal dataset obtained from a honey bee colony in Montr'eal, Quebec, Canada, spanning the years of 2021 to 2022. This apiary comprised 10 beehives, with microphones recording more than 2000 hours of high quality raw audio, and also sensors capturing temperature, and humidity. Periodic hive inspections involved monitoring colony honey bee population changes, assessing queen-related conditions, and documenting overall hive health. Additionally, health metrics, such as Varroa mite infestation rates and winter mortality assessments were recorded, offering valuable insights into factors affecting hive health status and resilience. In this study, we first outline the data collection process, sensor data description, and dataset structure. Furthermore, we demonstrate a practical application of this dataset by extracting various features from the raw audio to predict colony population using the number of frames of bees as a proxy.
Read more6/21/2024
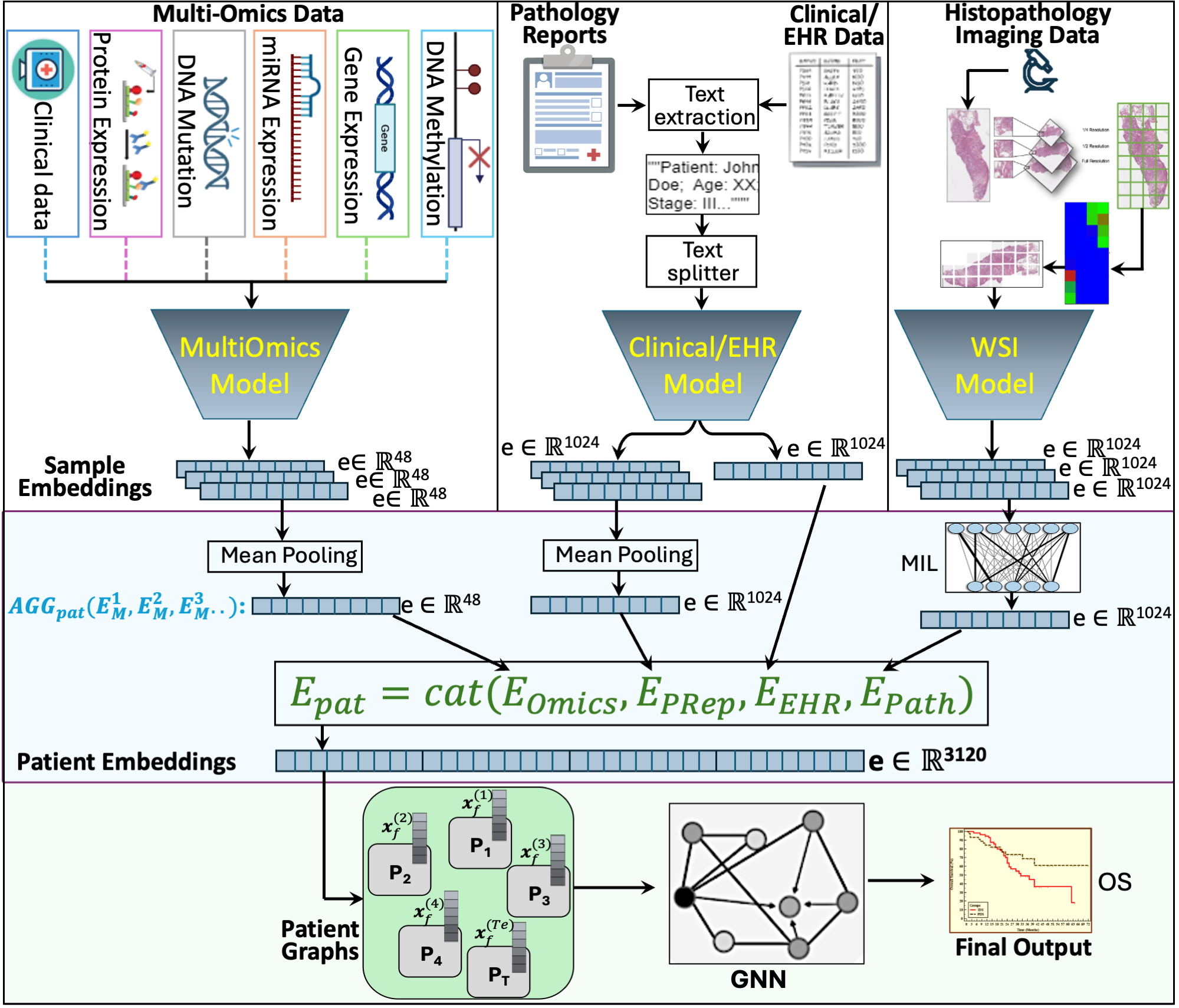
0
Embedding-based Multimodal Learning on Pan-Squamous Cell Carcinomas for Improved Survival Outcomes
Asim Waqas, Aakash Tripathi, Paul Stewart, Mia Naeini, Ghulam Rasool
Cancer clinics capture disease data at various scales, from genetic to organ level. Current bioinformatic methods struggle to handle the heterogeneous nature of this data, especially with missing modalities. We propose PARADIGM, a Graph Neural Network (GNN) framework that learns from multimodal, heterogeneous datasets to improve clinical outcome prediction. PARADIGM generates embeddings from multi-resolution data using foundation models, aggregates them into patient-level representations, fuses them into a unified graph, and enhances performance for tasks like survival analysis. We train GNNs on pan-Squamous Cell Carcinomas and validate our approach on Moffitt Cancer Center lung SCC data. Multimodal GNN outperforms other models in patient survival prediction. Converging individual data modalities across varying scales provides a more insightful disease view. Our solution aims to understand the patient's circumstances comprehensively, offering insights on heterogeneous data integration and the benefits of converging maximum data views.
Read more6/14/2024
💬
0
M3H: Multimodal Multitask Machine Learning for Healthcare
Dimitris Bertsimas, Yu Ma
Developing an integrated many-to-many framework leveraging multimodal data for multiple tasks is crucial to unifying healthcare applications ranging from diagnoses to operations. In resource-constrained hospital environments, a scalable and unified machine learning framework that improves previous forecast performances could improve hospital operations and save costs. We introduce M3H, an explainable Multimodal Multitask Machine Learning for Healthcare framework that consolidates learning from tabular, time-series, language, and vision data for supervised binary/multiclass classification, regression, and unsupervised clustering. It features a novel attention mechanism balancing self-exploitation (learning source-task), and cross-exploration (learning cross-tasks), and offers explainability through a proposed TIM score, shedding light on the dynamics of task learning interdependencies. M3H encompasses an unprecedented range of medical tasks and machine learning problem classes and consistently outperforms traditional single-task models by on average 11.6% across 40 disease diagnoses from 16 medical departments, three hospital operation forecasts, and one patient phenotyping task. The modular design of the framework ensures its generalizability in data processing, task definition, and rapid model prototyping, making it production ready for both clinical and operational healthcare settings, especially those in constrained environments.
Read more6/11/2024