Hot PATE: Private Aggregation of Distributions for Diverse Task

0
🔄
Sign in to get full access
Overview
- The Private Aggregation of Teacher Ensembles (PATE) framework is a versatile approach to privacy-preserving machine learning.
- In PATE, teacher models that are not privacy-preserving are trained on distinct portions of sensitive data.
- Privacy-preserving knowledge transfer to a student model is then facilitated by privately aggregating teachers' predictions on new examples.
- Employing PATE with generative auto-regressive models presents both challenges and opportunities.
- These models excel in open-ended "diverse" (aka "hot") tasks with multiple valid responses.
- The knowledge of models is often encapsulated in the response distribution itself, and preserving this diversity is critical for effective knowledge transfer from teachers to student.
- Prior PATE designs have faced a tradeoff between diversity and privacy, with higher diversity resulting in lower teacher agreement.
Plain English Explanation
The PATE framework is a way to do machine learning while protecting people's privacy. In PATE, there are "teacher" models that are trained on sensitive data, but these models don't protect privacy. The knowledge from these teachers is then shared with a "student" model in a private way, by aggregating the teachers' predictions on new examples.
Using PATE with generative models, which can create diverse and open-ended responses, presents some challenges and opportunities. These models are great at "hot" tasks where there are many valid answers, and their knowledge is often captured in the distribution of their responses. Preserving this diversity is crucial for effectively transferring knowledge from the teachers to the student.
However, prior PATE designs have struggled with a tradeoff between diversity and privacy. When the teachers produced more diverse responses, there was less agreement among them, which made it harder to transfer the knowledge privately.
Technical Explanation
The authors propose "hot PATE," a PATE design tailored for diverse settings. In hot PATE, each teacher model produces a highly diverse response distribution. The authors mathematically model the notion of "preserving diversity" and propose an aggregation method called "coordinated ensembles" that preserves privacy and transfers diversity without any penalty to privacy or efficiency.
The authors demonstrate the benefits of hot PATE empirically for in-context learning via prompts, and they show the potential to unlock more of the capabilities of generative models while preserving privacy.
Critical Analysis
The paper addresses an important challenge in privacy-preserving machine learning, namely how to effectively transfer knowledge from non-private teacher models to a private student model when the teachers produce diverse responses. The authors' proposed "hot PATE" design and "coordinated ensembles" aggregation method are novel contributions that could have significant implications for the field.
However, the paper does not discuss potential limitations or caveats of the hot PATE approach. For example, it's unclear how the method would scale to very large or complex teacher models, or how sensitive it might be to the quality and diversity of the teacher models. Additionally, the paper does not explore potential societal implications or real-world use cases for this technology.
Further research could investigate the robustness and generalizability of hot PATE, as well as its practical applications and broader impact. Readers are encouraged to think critically about the tradeoffs and considerations involved in privacy-preserving machine learning techniques like those presented in this paper.
Conclusion
The PATE framework provides a versatile approach to privacy-preserving machine learning, and the authors' proposed "hot PATE" design offers a way to effectively transfer knowledge from diverse teacher models to a private student model. This work has the potential to unlock more of the capabilities of generative models while preserving individual privacy, which could be valuable for a wide range of applications. As with any emerging technology, it will be important to continue exploring the implications and limitations of this approach to ensure it is developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Hot PATE: Private Aggregation of Distributions for Diverse Task
Edith Cohen, Benjamin Cohen-Wang, Xin Lyu, Jelani Nelson, Tamas Sarlos, Uri Stemmer
The Private Aggregation of Teacher Ensembles (PATE) framework is a versatile approach to privacy-preserving machine learning. In PATE, teacher models that are not privacy-preserving are trained on distinct portions of sensitive data. Privacy-preserving knowledge transfer to a student model is then facilitated by privately aggregating teachers' predictions on new examples. Employing PATE with generative auto-regressive models presents both challenges and opportunities. These models excel in open ended emph{diverse} (aka hot) tasks with multiple valid responses. Moreover, the knowledge of models is often encapsulated in the response distribution itself and preserving this diversity is critical for fluid and effective knowledge transfer from teachers to student. In all prior designs, higher diversity resulted in lower teacher agreement and thus -- a tradeoff between diversity and privacy. Prior works with PATE thus focused on non-diverse settings or limiting diversity to improve utility. We propose emph{hot PATE}, a design tailored for the diverse setting. In hot PATE, each teacher model produces a response distribution that can be highly diverse. We mathematically model the notion of emph{preserving diversity} and propose an aggregation method, emph{coordinated ensembles}, that preserves privacy and transfers diversity with emph{no penalty} to privacy or efficiency. We demonstrate empirically the benefits of hot PATE for in-context learning via prompts and potential to unleash more of the capabilities of generative models.
Read more5/21/2024

0
The Elusive Pursuit of Replicating PATE-GAN: Benchmarking, Auditing, Debugging
Georgi Ganev, Meenatchi Sundaram Muthu Selva Annamalai, Emiliano De Cristofaro
Synthetic data created by differentially private (DP) generative models is increasingly used in real-world settings. In this context, PATE-GAN has emerged as a popular algorithm, combining Generative Adversarial Networks (GANs) with the private training approach of PATE (Private Aggregation of Teacher Ensembles). In this paper, we analyze and benchmark six open-source PATE-GAN implementations, including three by (a subset of) the original authors. First, we shed light on architecture deviations and empirically demonstrate that none replicate the utility performance reported in the original paper. Then, we present an in-depth privacy evaluation, including DP auditing, showing that all implementations leak more privacy than intended and uncovering 17 privacy violations and 5 other bugs. Our codebase is available from https://github.com/spalabucr/pategan-audit.
Read more6/21/2024
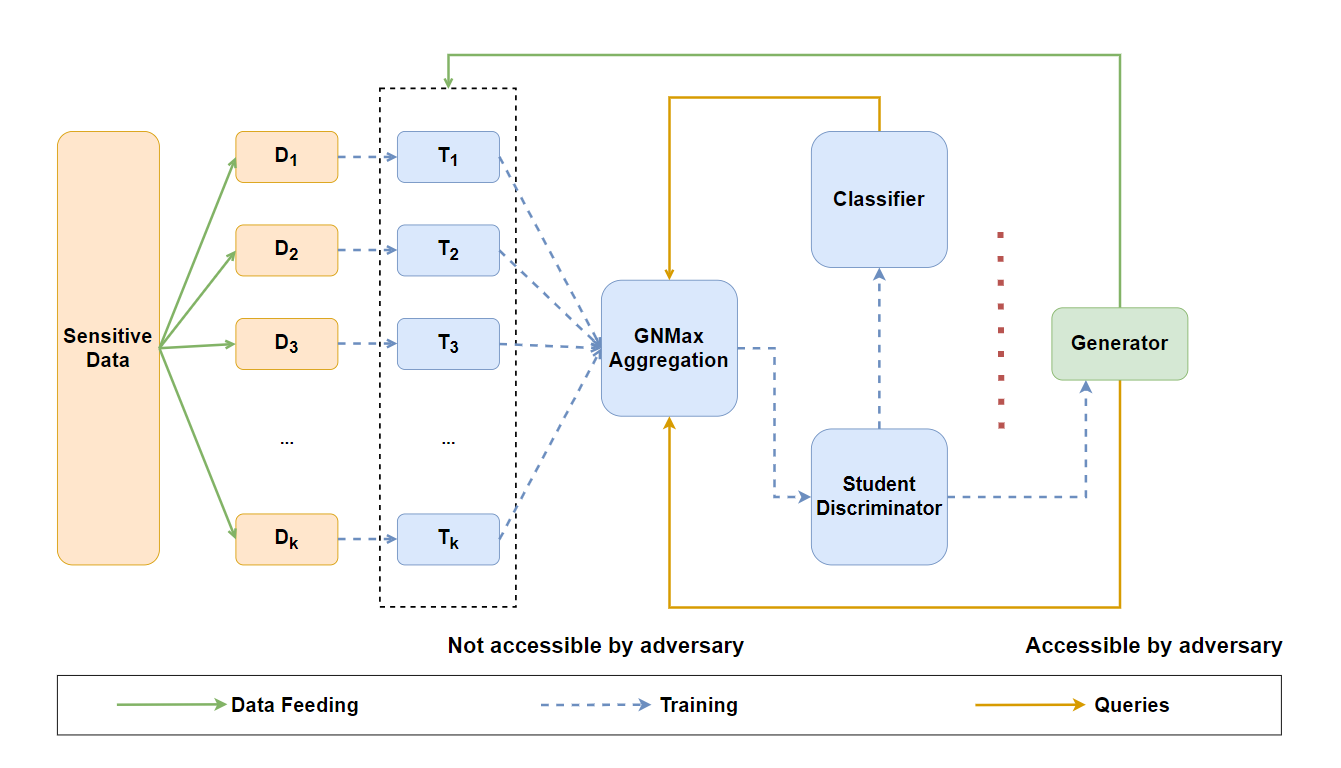
0
PATE-TripleGAN: Privacy-Preserving Image Synthesis with Gaussian Differential Privacy
Zepeng Jiang, Weiwei Ni, Yifan Zhang
Conditional Generative Adversarial Networks (CGANs) exhibit significant potential in supervised learning model training by virtue of their ability to generate realistic labeled images. However, numerous studies have indicated the privacy leakage risk in CGANs models. The solution DPCGAN, incorporating the differential privacy framework, faces challenges such as heavy reliance on labeled data for model training and potential disruptions to original gradient information due to excessive gradient clipping, making it difficult to ensure model accuracy. To address these challenges, we present a privacy-preserving training framework called PATE-TripleGAN. This framework incorporates a classifier to pre-classify unlabeled data, establishing a three-party min-max game to reduce dependence on labeled data. Furthermore, we present a hybrid gradient desensitization algorithm based on the Private Aggregation of Teacher Ensembles (PATE) framework and Differential Private Stochastic Gradient Descent (DPSGD) method. This algorithm allows the model to retain gradient information more effectively while ensuring privacy protection, thereby enhancing the model's utility. Privacy analysis and extensive experiments affirm that the PATE-TripleGAN model can generate a higher quality labeled image dataset while ensuring the privacy of the training data.
Read more4/22/2024
📉
0
Estimation of conditional average treatment effects on distributed data: A privacy-preserving approach
Yuji Kawamata, Ryoki Motai, Yukihiko Okada, Akira Imakura, Tetsuya Sakurai
Estimation of conditional average treatment effects (CATEs) is an important topic in sciences. CATEs can be estimated with high accuracy if distributed data across multiple parties can be centralized. However, it is difficult to aggregate such data owing to confidential or privacy concerns. To address this issue, we proposed data collaboration double machine learning, a method that can estimate CATE models from privacy-preserving fusion data constructed from distributed data, and evaluated our method through simulations. Our contributions are summarized in the following three points. First, our method enables estimation and testing of semi-parametric CATE models without iterative communication on distributed data. Our semi-parametric CATE method enable estimation and testing that is more robust to model mis-specification than parametric methods. Second, our method enables collaborative estimation between multiple time points and different parties through the accumulation of a knowledge base. Third, our method performed equally or better than other methods in simulations using synthetic, semi-synthetic and real-world datasets.
Read more9/11/2024