PATE: Proximity-Aware Time series anomaly Evaluation

0
Sign in to get full access
Overview
- Proposes a new metric called PATE (Proximity-Aware Time series anomaly Evaluation) for evaluating time series anomaly detection models
- Addresses limitations of existing evaluation metrics like precision and recall
- Designed to better capture the proximity of detected anomalies to true anomalies in time series data
Plain English Explanation
Time series data, such as stock prices or sensor readings, can contain anomalies or unusual patterns that are important to detect. When evaluating models that try to identify these anomalies, the existing evaluation metrics like precision and recall have limitations. They don't fully capture how close the detected anomalies are to the true anomalies in the time series.
The PATE metric proposed in this paper aims to address this. It looks at not just whether the model correctly identified anomalies, but also how close those detected anomalies are to the true anomalies in time. This can provide a more nuanced understanding of the model's performance, especially for applications where the timing of anomaly detection is critical, like monitoring sensor data or detecting financial fraud.
Technical Explanation
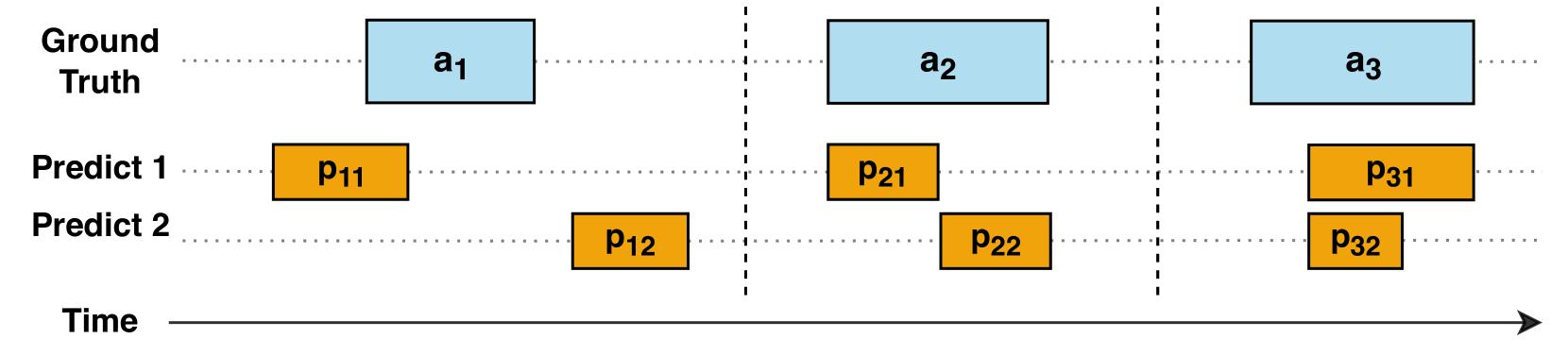
The key idea behind PATE is to not just look at whether the model correctly identified anomalies (like precision and recall do), but also consider how close the detected anomalies are to the true anomalies in the time series.
To calculate PATE, the authors first define a "proximity score" that measures how close each detected anomaly is to the nearest true anomaly. They then aggregate these proximity scores to compute the PATE metric, which reflects both the accuracy of the anomaly detections and their temporal proximity to the ground truth.
The authors evaluate PATE on several benchmark time series anomaly detection datasets and compare it to traditional metrics like precision and recall. They show that PATE can provide additional insights into model performance that are missed by other metrics, especially for applications where the timing of anomaly detection is critical.
Critical Analysis
The PATE metric proposed in this paper addresses an important limitation of existing time series anomaly detection evaluation approaches. By considering the temporal proximity of detected anomalies, it can provide a more nuanced and relevant assessment of model performance, especially for real-world applications.
However, the authors acknowledge that PATE relies on the availability of ground truth anomaly labels, which may not always be easy to obtain. Additionally, the choice of the proximity score function and the aggregation method used to compute PATE could have a significant impact on the results, and the authors don't provide much guidance on how to make these choices.
It would also be interesting to see how PATE compares to other recently proposed evaluation metrics for time series anomaly detection, such as those based on concept-based explanations or distribution shifts. Further research and comparisons could help establish the strengths and limitations of the PATE approach.
Conclusion
The PATE metric proposed in this paper represents an important step forward in the evaluation of time series anomaly detection models. By considering the temporal proximity of detected anomalies to the ground truth, it can provide a more meaningful and actionable assessment of model performance, especially for real-world applications where the timing of anomaly detection is critical.
While PATE has some limitations and areas for further research, it is a valuable addition to the toolkit of time series anomaly detection researchers and practitioners. As the field continues to evolve, metrics like PATE will be increasingly important for driving progress and ensuring that anomaly detection models are reliable and deployable in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PATE: Proximity-Aware Time series anomaly Evaluation
Ramin Ghorbani, Marcel J. T. Reinders, David M. J. Tax
Evaluating anomaly detection algorithms in time series data is critical as inaccuracies can lead to flawed decision-making in various domains where real-time analytics and data-driven strategies are essential. Traditional performance metrics assume iid data and fail to capture the complex temporal dynamics and specific characteristics of time series anomalies, such as early and delayed detections. We introduce Proximity-Aware Time series anomaly Evaluation (PATE), a novel evaluation metric that incorporates the temporal relationship between prediction and anomaly intervals. PATE uses proximity-based weighting considering buffer zones around anomaly intervals, enabling a more detailed and informed assessment of a detection. Using these weights, PATE computes a weighted version of the area under the Precision and Recall curve. Our experiments with synthetic and real-world datasets show the superiority of PATE in providing more sensible and accurate evaluations than other evaluation metrics. We also tested several state-of-the-art anomaly detectors across various benchmark datasets using the PATE evaluation scheme. The results show that a common metric like Point-Adjusted F1 Score fails to characterize the detection performances well, and that PATE is able to provide a more fair model comparison. By introducing PATE, we redefine the understanding of model efficacy that steers future studies toward developing more effective and accurate detection models.
Read more5/21/2024
🤷
0
Unsupervised Anomaly Detection in Time-series: An Extensive Evaluation and Analysis of State-of-the-art Methods
Nesryne Mejri, Laura Lopez-Fuentes, Kankana Roy, Pavel Chernakov, Enjie Ghorbel, Djamila Aouada
Unsupervised anomaly detection in time-series has been extensively investigated in the literature. Notwithstanding the relevance of this topic in numerous application fields, a comprehensive and extensive evaluation of recent state-of-the-art techniques taking into account real-world constraints is still needed. Some efforts have been made to compare existing unsupervised time-series anomaly detection methods rigorously. However, only standard performance metrics, namely precision, recall, and F1-score are usually considered. Essential aspects for assessing their practical relevance are therefore neglected. This paper proposes an in-depth evaluation study of recent unsupervised anomaly detection techniques in time-series. Instead of relying solely on standard performance metrics, additional yet informative metrics and protocols are taken into account. In particular, (i) more elaborate performance metrics specifically tailored for time-series are used; (ii) the model size and the model stability are studied; (iii) an analysis of the tested approaches with respect to the anomaly type is provided; and (iv) a clear and unique protocol is followed for all experiments. Overall, this extensive analysis aims to assess the maturity of state-of-the-art time-series anomaly detection, give insights regarding their applicability under real-world setups and provide to the community a more complete evaluation protocol.
Read more8/13/2024

0
TimeSeriesBench: An Industrial-Grade Benchmark for Time Series Anomaly Detection Models
Haotian Si, Jianhui Li, Changhua Pei, Hang Cui, Jingwen Yang, Yongqian Sun, Shenglin Zhang, Jingjing Li, Haiming Zhang, Jing Han, Dan Pei, Gaogang Xie
Time series anomaly detection (TSAD) has gained significant attention due to its real-world applications to improve the stability of modern software systems. However, there is no effective way to verify whether they can meet the requirements for real-world deployment. Firstly, current algorithms typically train a specific model for each time series. Maintaining such many models is impractical in a large-scale system with tens of thousands of curves. The performance of using merely one unified model to detect anomalies remains unknown. Secondly, most TSAD models are trained on the historical part of a time series and are tested on its future segment. In distributed systems, however, there are frequent system deployments and upgrades, with new, previously unseen time series emerging daily. The performance of testing newly incoming unseen time series on current TSAD algorithms remains unknown. Lastly, the assumptions of the evaluation metrics in existing benchmarks are far from practical demands. To solve the above-mentioned problems, we propose an industrial-grade benchmark TimeSeriesBench. We assess the performance of existing algorithms across more than 168 evaluation settings and provide comprehensive analysis for the future design of anomaly detection algorithms. An industrial dataset is also released along with TimeSeriesBench.
Read more9/4/2024
🔄
0
Hot PATE: Private Aggregation of Distributions for Diverse Task
Edith Cohen, Benjamin Cohen-Wang, Xin Lyu, Jelani Nelson, Tamas Sarlos, Uri Stemmer
The Private Aggregation of Teacher Ensembles (PATE) framework is a versatile approach to privacy-preserving machine learning. In PATE, teacher models that are not privacy-preserving are trained on distinct portions of sensitive data. Privacy-preserving knowledge transfer to a student model is then facilitated by privately aggregating teachers' predictions on new examples. Employing PATE with generative auto-regressive models presents both challenges and opportunities. These models excel in open ended emph{diverse} (aka hot) tasks with multiple valid responses. Moreover, the knowledge of models is often encapsulated in the response distribution itself and preserving this diversity is critical for fluid and effective knowledge transfer from teachers to student. In all prior designs, higher diversity resulted in lower teacher agreement and thus -- a tradeoff between diversity and privacy. Prior works with PATE thus focused on non-diverse settings or limiting diversity to improve utility. We propose emph{hot PATE}, a design tailored for the diverse setting. In hot PATE, each teacher model produces a response distribution that can be highly diverse. We mathematically model the notion of emph{preserving diversity} and propose an aggregation method, emph{coordinated ensembles}, that preserves privacy and transfers diversity with emph{no penalty} to privacy or efficiency. We demonstrate empirically the benefits of hot PATE for in-context learning via prompts and potential to unleash more of the capabilities of generative models.
Read more5/21/2024