How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse
2404.05090
0
0

Abstract
The phenomenon of model collapse, introduced in (Shumailov et al., 2023), refers to the deterioration in performance that occurs when new models are trained on synthetic data generated from previously trained models. This recursive training loop makes the tails of the original distribution disappear, thereby making future-generation models forget about the initial (real) distribution. With the aim of rigorously understanding model collapse in language models, we consider in this paper a statistical model that allows us to characterize the impact of various recursive training scenarios. Specifically, we demonstrate that model collapse cannot be avoided when training solely on synthetic data. However, when mixing both real and synthetic data, we provide an estimate of a maximal amount of synthetic data below which model collapse can eventually be avoided. Our theoretical conclusions are further supported by empirical validations.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the phenomenon of "language model collapse" - a situation where language models trained on synthetic data fail to generalize and instead simply reproduce the training data.
- The researchers use statistical analysis to study the factors that can contribute to language model collapse, providing insights into the challenges of training on synthetic data.
- The findings have implications for the development of robust and reliable language models, which are crucial for a wide range of natural language processing applications.
Plain English Explanation
Language models are artificial intelligence systems that are trained on large amounts of text data to learn the patterns and structure of human language. These models are then used in various applications, such as chatbots, text generation, and language translation.
One of the challenges in training language models is the use of synthetic data - data that is artificially generated rather than being drawn from real-world sources. While synthetic data can be useful for supplementing limited real-world data, it can also lead to a phenomenon called "language model collapse."
Language model collapse occurs when the model trained on synthetic data fails to generalize and instead simply reproduces the training data, without learning the broader patterns and nuances of human language. This can result in the model producing text that sounds artificial or unnatural, limiting its effectiveness in real-world applications.
In this paper, the researchers use statistical analysis to investigate the factors that can contribute to language model collapse. They examine how the properties of the synthetic data, the training process, and the model architecture can all influence the likelihood of collapse. By understanding these factors, the researchers hope to provide insights that can help developers create more robust and reliable language models, even when working with synthetic data.
Technical Explanation
The paper begins by discussing the related work on the challenges of training language models on synthetic data, including the problem of knowledge collapse and the stability issues associated with self-training approaches.
The researchers then introduce their theoretical setup, which involves modeling the language model training process as a Markov chain. They analyze the conditions under which the language model can converge to a "collapsed" state, where it simply reproduces the training data, rather than learning the broader patterns of language.
The analysis considers factors such as the properties of the synthetic data (e.g., the level of diversity and coherence), the training algorithm (e.g., the learning rate and optimization method), and the model architecture (e.g., the capacity and inductive biases). The researchers derive mathematical conditions that predict the likelihood of language model collapse under different configurations of these factors.
Through numerical simulations and experiments, the researchers validate their theoretical predictions and provide insights into the practical implications of language model collapse. For example, they show that overly simplistic synthetic data and certain architectural choices can make language models more susceptible to collapse, even in the presence of real-world training data.
The paper also discusses potential mitigation strategies, such as carefully curating the synthetic data, adjusting the training procedure, and designing model architectures that are more robust to the biases and limitations of synthetic data.
Critical Analysis
The paper provides a rigorous statistical analysis of the language model collapse phenomenon, which is an important and timely issue in the field of natural language processing. The researchers' theoretical framework and mathematical analysis offer a solid foundation for understanding the factors that contribute to this problem.
However, the paper does not address all the potential complexities and nuances of real-world language model training. For example, the analysis focuses on relatively simple synthetic data and model architectures, whereas practical language models often involve much more complex and heterogeneous training data, as well as more sophisticated neural network architectures.
Additionally, the paper does not explore the potential trade-offs and practical considerations that may arise when implementing the proposed mitigation strategies. For instance, some techniques for improving the robustness of language models may come at the cost of reduced performance or increased computational complexity.
Further research is needed to extend the analysis to more realistic scenarios and to investigate the practical implications and trade-offs of the proposed solutions. Nevertheless, this paper represents an important step forward in understanding and addressing the challenges of training language models on synthetic data.
Conclusion
This paper provides a statistical analysis of the language model collapse phenomenon, where language models trained on synthetic data fail to generalize and instead simply reproduce the training data. The researchers use a Markov chain-based framework to investigate the factors that can contribute to this problem, including the properties of the synthetic data, the training algorithm, and the model architecture.
The findings from this research offer valuable insights for the development of robust and reliable language models, which are crucial for a wide range of natural language processing applications. By understanding the conditions that can lead to language model collapse, researchers and practitioners can develop more effective strategies for training language models, even when relying on synthetic data to supplement limited real-world data.
While the paper presents a solid theoretical foundation, further research is needed to address the complexities and practical considerations of real-world language model training. Nevertheless, this work represents an important contribution to the ongoing efforts to improve the performance and reliability of language models, with potential implications for the broader field of artificial intelligence.
Related Papers
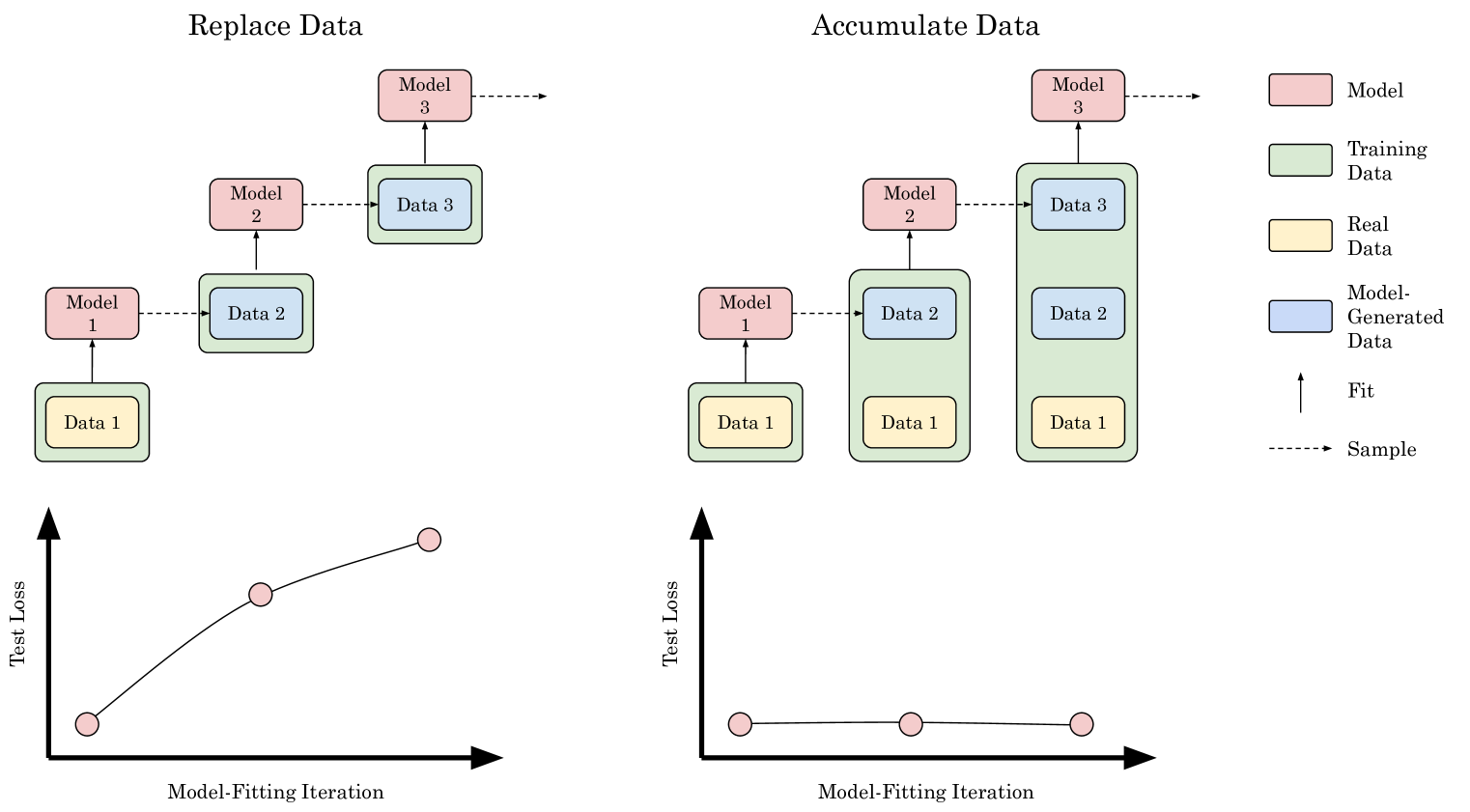
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, Henry Sleight, John Hughes, Tomasz Korbak, Rajashree Agrawal, Dhruv Pai, Andrey Gromov, Daniel A. Roberts, Diyi Yang, David L. Donoho, Sanmi Koyejo
0
0
The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops proposed that such loops would lead to a phenomenon termed model collapse, under which performance progressively degrades with each model-data feedback iteration until fitted models become useless. However, those studies largely assumed that new data replace old data over time, where an arguably more realistic assumption is that data accumulate over time. In this paper, we ask: what effect does accumulating data have on model collapse? We empirically study this question by pretraining sequences of language models on text corpora. We confirm that replacing the original real data by each generation's synthetic data does indeed tend towards model collapse, then demonstrate that accumulating the successive generations of synthetic data alongside the original real data avoids model collapse; these results hold across a range of model sizes, architectures, and hyperparameters. We obtain similar results for deep generative models on other types of real data: diffusion models for molecule conformation generation and variational autoencoders for image generation. To understand why accumulating data can avoid model collapse, we use an analytically tractable framework introduced by prior work in which a sequence of linear models are fit to the previous models' outputs. Previous work used this framework to show that if data are replaced, the test error increases with the number of model-fitting iterations; we extend this argument to prove that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations, meaning model collapse no longer occurs.
5/1/2024
🏋️
The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text
Yanzhu Guo, Guokan Shang, Michalis Vazirgiannis, Chlo'e Clavel
0
0
This study investigates the consequences of training language models on synthetic data generated by their predecessors, an increasingly prevalent practice given the prominence of powerful generative models. Diverging from the usual emphasis on performance metrics, we focus on the impact of this training methodology on linguistic diversity, especially when conducted recursively over time. To assess this, we adapt and develop a set of novel metrics targeting lexical, syntactic, and semantic diversity, applying them in recursive finetuning experiments across various natural language generation tasks in English. Our findings reveal a consistent decrease in the diversity of the model outputs through successive iterations, especially remarkable for tasks demanding high levels of creativity. This trend underscores the potential risks of training language models on synthetic text, particularly concerning the preservation of linguistic richness. Our study highlights the need for careful consideration of the long-term effects of such training approaches on the linguistic capabilities of language models.
4/17/2024
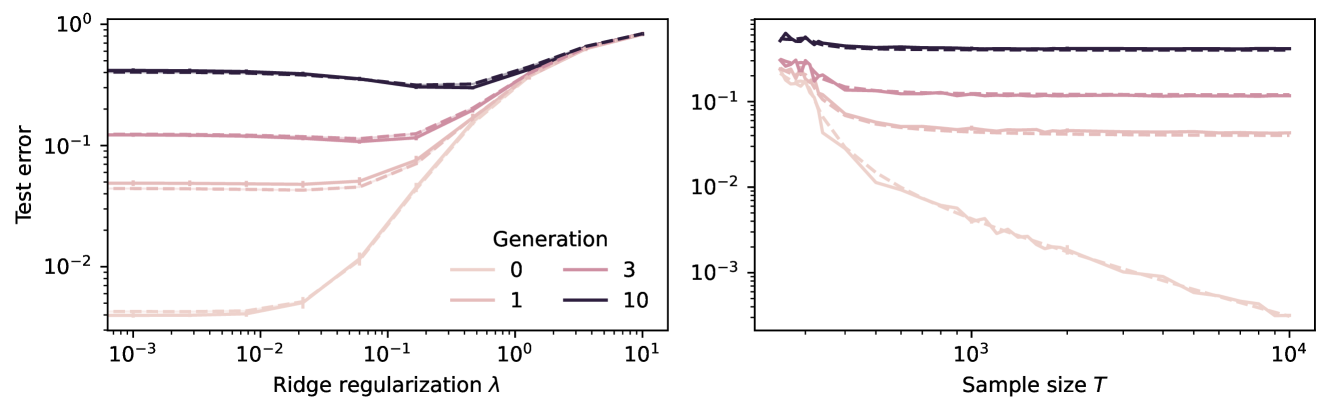
Model Collapse Demystified: The Case of Regression
Elvis Dohmatob, Yunzhen Feng, Julia Kempe
0
0
In the era of proliferation of large language and image generation models, the phenomenon of model collapse refers to the situation whereby as a model is trained recursively on data generated from previous generations of itself over time, its performance degrades until the model eventually becomes completely useless, i.e the model collapses. In this work, we study this phenomenon in the setting of high-dimensional regression and obtain analytic formulae which quantitatively outline this phenomenon in a broad range of regimes. In the special case of polynomial decaying spectral and source conditions, we obtain modified scaling laws which exhibit new crossover phenomena from fast to slow rates. We also propose a simple strategy based on adaptive regularization to mitigate model collapse. Our theoretical results are validated with experiments.
5/2/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024