Model Collapse Demystified: The Case of Regression
2402.07712
0
0
Abstract
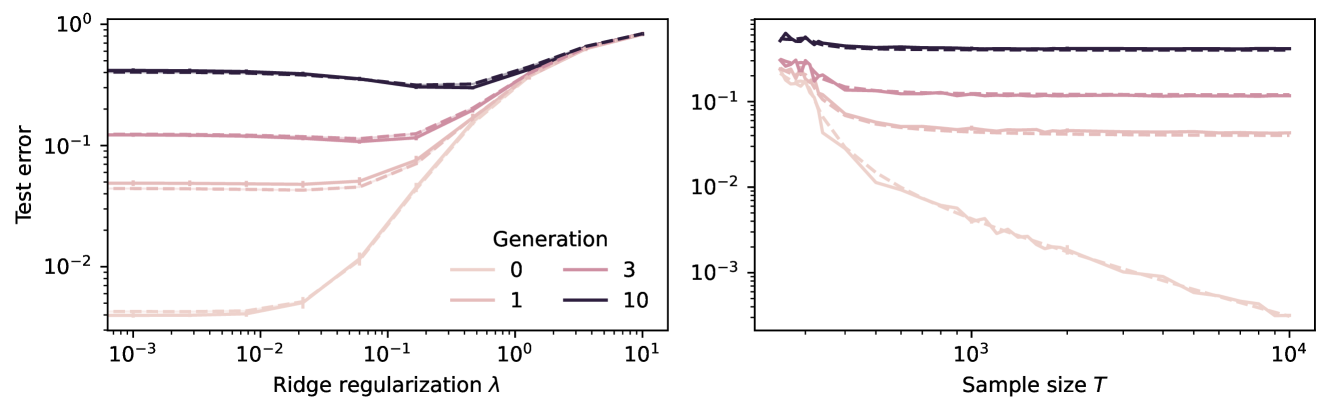
In the era of proliferation of large language and image generation models, the phenomenon of model collapse refers to the situation whereby as a model is trained recursively on data generated from previous generations of itself over time, its performance degrades until the model eventually becomes completely useless, i.e the model collapses. In this work, we study this phenomenon in the setting of high-dimensional regression and obtain analytic formulae which quantitatively outline this phenomenon in a broad range of regimes. In the special case of polynomial decaying spectral and source conditions, we obtain modified scaling laws which exhibit new crossover phenomena from fast to slow rates. We also propose a simple strategy based on adaptive regularization to mitigate model collapse. Our theoretical results are validated with experiments.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper examines the phenomenon of "model collapse" in the context of regression problems.
- Model collapse occurs when a machine learning model fails to learn the underlying patterns in the data and instead converges to a simple, uninformative solution.
- The authors provide a theoretical and empirical analysis of model collapse in regression tasks, offering insights into the factors that contribute to this issue.
Plain English Explanation
Machine learning models are commonly used to solve a wide range of problems, including regression tasks, where the goal is to predict a continuous output variable based on input data. However, sometimes these models can fail to learn the true patterns in the data and instead converge to a simple, uninformative solution. This phenomenon is known as "model collapse."
The authors of this paper delve into the problem of model collapse in regression tasks, aiming to demystify the underlying causes and provide a better understanding of this issue. They use a combination of theoretical analysis and empirical investigations to shed light on the factors that can lead to model collapse, such as the complexity of the data, the choice of model architecture, and the optimization process.
By exploring the nuances of model collapse in regression, the researchers hope to help machine learning practitioners develop more robust and reliable models that can effectively capture the relevant patterns in the data, even in the face of challenging scenarios that might otherwise lead to model collapse.
Technical Explanation
The paper presents a comprehensive analysis of model collapse in the context of regression tasks. The authors begin by reviewing the existing literature on model collapse, including related studies on how bad is training on synthetic data, the inevitability of model collapse, and the collapse of self-trained language models [collapse-self-trained-language-models].
Through a detailed theoretical investigation, the researchers demonstrate that model collapse can occur even in simple regression settings, where the true underlying function is linear. They identify key factors that contribute to this phenomenon, such as the curse of recursion and the presence of certain types of noise in the data.
To validate their theoretical findings, the authors conduct extensive experiments using synthetic and real-world datasets. They explore the impact of various model architectures, optimization algorithms, and hyperparameter settings on the likelihood and severity of model collapse. The results provide empirical evidence for the theoretical insights and offer practical guidance for mitigating the problem.
Critical Analysis
The paper presents a thorough and insightful analysis of model collapse in regression tasks, which is an important and often overlooked issue in machine learning. The authors' theoretical and empirical investigations offer valuable contributions to the understanding of this phenomenon.
One potential limitation of the study is that it focuses exclusively on regression problems, and the findings may not directly translate to other machine learning tasks, such as classification or generative modeling. The researchers acknowledge this and suggest that further research is needed to explore the generalizability of their insights.
Additionally, the paper does not delve into the potential societal implications of model collapse, such as the risks of deploying faulty models in real-world applications. Exploring these broader implications could be a fruitful area for future research.
Overall, the paper is a well-executed and insightful contribution to the field of machine learning. The authors' solvable model for the emergence of scaling laws and their nuanced analysis of the factors leading to model collapse provide a solid foundation for further investigations and practical applications.
Conclusion
This paper offers a comprehensive examination of the problem of model collapse in regression tasks, providing both theoretical and empirical insights into the underlying causes and contributing factors. The researchers' findings shed light on the complexities of model training and serve as a valuable resource for machine learning practitioners who strive to develop robust and reliable models, even in the face of challenging data scenarios.
By demystifying the mechanisms behind model collapse, this study paves the way for the development of more advanced techniques and strategies to mitigate this issue, ultimately leading to improvements in the performance and reliability of machine learning systems across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

How Bad is Training on Synthetic Data? A Statistical Analysis of Language Model Collapse
Mohamed El Amine Seddik, Suei-Wen Chen, Soufiane Hayou, Pierre Youssef, Merouane Debbah
0
0
The phenomenon of model collapse, introduced in (Shumailov et al., 2023), refers to the deterioration in performance that occurs when new models are trained on synthetic data generated from previously trained models. This recursive training loop makes the tails of the original distribution disappear, thereby making future-generation models forget about the initial (real) distribution. With the aim of rigorously understanding model collapse in language models, we consider in this paper a statistical model that allows us to characterize the impact of various recursive training scenarios. Specifically, we demonstrate that model collapse cannot be avoided when training solely on synthetic data. However, when mixing both real and synthetic data, we provide an estimate of a maximal amount of synthetic data below which model collapse can eventually be avoided. Our theoretical conclusions are further supported by empirical validations.
4/9/2024
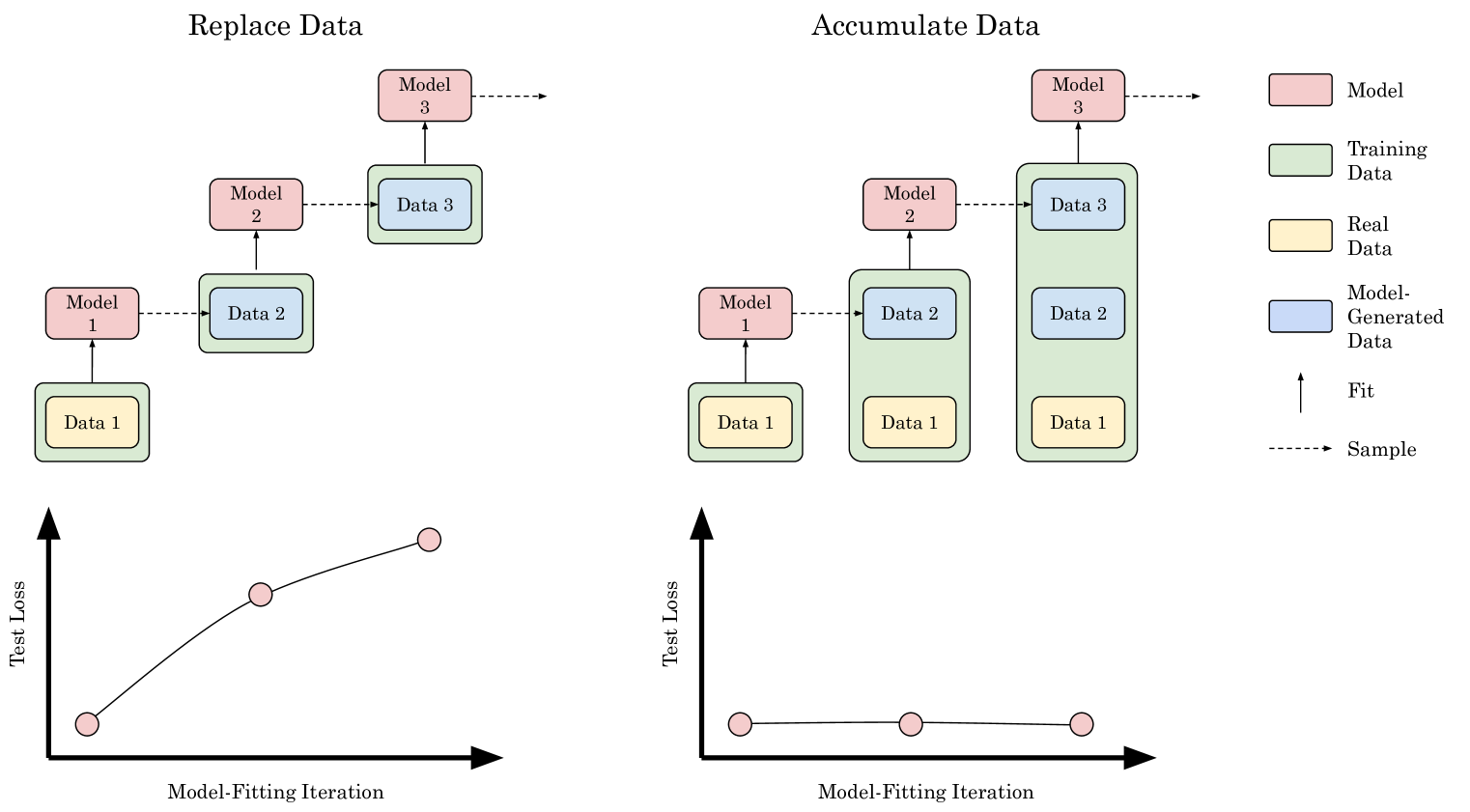
Is Model Collapse Inevitable? Breaking the Curse of Recursion by Accumulating Real and Synthetic Data
Matthias Gerstgrasser, Rylan Schaeffer, Apratim Dey, Rafael Rafailov, Henry Sleight, John Hughes, Tomasz Korbak, Rajashree Agrawal, Dhruv Pai, Andrey Gromov, Daniel A. Roberts, Diyi Yang, David L. Donoho, Sanmi Koyejo
0
0
The proliferation of generative models, combined with pretraining on web-scale data, raises a timely question: what happens when these models are trained on their own generated outputs? Recent investigations into model-data feedback loops proposed that such loops would lead to a phenomenon termed model collapse, under which performance progressively degrades with each model-data feedback iteration until fitted models become useless. However, those studies largely assumed that new data replace old data over time, where an arguably more realistic assumption is that data accumulate over time. In this paper, we ask: what effect does accumulating data have on model collapse? We empirically study this question by pretraining sequences of language models on text corpora. We confirm that replacing the original real data by each generation's synthetic data does indeed tend towards model collapse, then demonstrate that accumulating the successive generations of synthetic data alongside the original real data avoids model collapse; these results hold across a range of model sizes, architectures, and hyperparameters. We obtain similar results for deep generative models on other types of real data: diffusion models for molecule conformation generation and variational autoencoders for image generation. To understand why accumulating data can avoid model collapse, we use an analytically tractable framework introduced by prior work in which a sequence of linear models are fit to the previous models' outputs. Previous work used this framework to show that if data are replaced, the test error increases with the number of model-fitting iterations; we extend this argument to prove that if data instead accumulate, the test error has a finite upper bound independent of the number of iterations, meaning model collapse no longer occurs.
5/1/2024
Collapse of Self-trained Language Models
David Herel, Tomas Mikolov
0
0
In various fields of knowledge creation, including science, new ideas often build on pre-existing information. In this work, we explore this concept within the context of language models. Specifically, we explore the potential of self-training models on their own outputs, akin to how humans learn and build on their previous thoughts and actions. While this approach is intuitively appealing, our research reveals its practical limitations. We find that extended self-training of the GPT-2 model leads to a significant degradation in performance, resulting in repetitive and collapsed token output.
4/4/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024