On the Stability of Iterative Retraining of Generative Models on their own Data
2310.00429
0
0
📊
Abstract
Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models will be trained on both clean and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets -- from classical training on real data to self-consuming generative models trained on purely synthetic data. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Deep generative models have made remarkable progress in generating high-quality synthetic data that can be hard for humans to distinguish from real samples.
- This progress has been enabled by training these models on massive amounts of web-scale data.
- As a result, the web is likely to become increasingly populated with synthetic content generated by these models.
- This raises the possibility that future generations of generative models could be trained on a mix of real and synthetic data, potentially leading to new challenges.
Plain English Explanation
Deep generative models are a type of artificial intelligence that can create new, realistic-looking data like images, text, or audio. These models have become incredibly good at their task, to the point where it can be difficult for people to tell the difference between the synthetic data they generate and real data.
The key reason these models have become so capable is that they have been trained on huge amounts of data from the internet and other sources. This has allowed them to learn the patterns and characteristics of real-world data, enabling them to create new samples that mimic the original data very closely.
However, as these models become more widespread and their outputs become more indistinguishable from reality, the internet and other digital spaces are likely to become flooded with synthetic content. This raises the possibility that future generations of generative models could be trained on a mix of real data and the synthetic data created by earlier models.
Researchers are now trying to understand the implications of this scenario and how it might impact the development of generative models going forward.
Technical Explanation
The paper explores the impact of training deep generative models on a mixed dataset consisting of both real and synthetic data. The researchers first prove the theoretical stability of this iterative training process, showing that it will converge as long as the initial generative model approximates the real data distribution well enough and the proportion of clean (real) training data is sufficiently large.
They then validate their theory through experiments on both synthetic and natural image datasets, such as CIFAR10 and FFHQ. Specifically, they train normalizing flow and diffusion models in an iterative fashion, starting with real data and gradually incorporating more synthetic data generated by previous model iterations.
The results demonstrate that generative models can indeed be successfully trained on a combination of real and synthetic data, with the models maintaining high generation quality even as the proportion of synthetic data increases. This suggests that the web's transition towards synthetic content may not necessarily undermine the capabilities of future generative models.
Critical Analysis
The paper provides a rigorous theoretical and empirical analysis of an important issue facing the development of deep generative models. By considering the implications of training on mixed datasets, the researchers have identified a potential challenge that the field will likely need to grapple with as synthetic content becomes more prevalent.
However, the paper does not address several key concerns that could arise in real-world scenarios. For instance, it does not consider the potential for the synthetic data to contain biases, errors, or other undesirable properties that could then be amplified in later model iterations. Additionally, the researchers only tested their approach on relatively simple image datasets, and it's unclear how it would scale to more complex, high-stakes domains like medical imaging or financial data.
Further research is needed to better understand the long-term consequences of training generative models on mixed datasets, particularly as these models become more influential in shaping the digital landscape. Careful consideration must be given to the ethical implications and potential misuse of such technologies.
Conclusion
This paper presents an important first step in studying the impact of training deep generative models on a mix of real and synthetic data. The researchers have demonstrated the theoretical and empirical feasibility of this approach, suggesting that the growth of synthetic content on the web may not necessarily undermine the capabilities of future generative models.
However, the work also highlights the need for continued vigilance and further research to address the potential challenges and ethical concerns that could arise as these technologies become more ubiquitous. As the field of deep generative modeling continues to advance, it will be crucial to consider the broader societal implications and develop safeguards to ensure these powerful tools are used responsibly.
Related Papers
📈
Self-Correcting Self-Consuming Loops for Generative Model Training
Nate Gillman, Michael Freeman, Daksh Aggarwal, Chia-Hong Hsu, Calvin Luo, Yonglong Tian, Chen Sun
0
0
As synthetic data becomes higher quality and proliferates on the internet, machine learning models are increasingly trained on a mix of human- and machine-generated data. Despite the successful stories of using synthetic data for representation learning, using synthetic data for generative model training creates self-consuming loops which may lead to training instability or even collapse, unless certain conditions are met. Our paper aims to stabilize self-consuming generative model training. Our theoretical results demonstrate that by introducing an idealized correction function, which maps a data point to be more likely under the true data distribution, self-consuming loops can be made exponentially more stable. We then propose self-correction functions, which rely on expert knowledge (e.g. the laws of physics programmed in a simulator), and aim to approximate the idealized corrector automatically and at scale. We empirically validate the effectiveness of self-correcting self-consuming loops on the challenging human motion synthesis task, and observe that it successfully avoids model collapse, even when the ratio of synthetic data to real data is as high as 100%.
4/8/2024
🔄
Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data
Leonhard Hennicke, Christian Medeiros Adriano, Holger Giese, Jan Mathias Koehler, Lukas Schott
0
0
Generative foundation models like Stable Diffusion comprise a diverse spectrum of knowledge in computer vision with the potential for transfer learning, e.g., via generating data to train student models for downstream tasks. This could circumvent the necessity of collecting labeled real-world data, thereby presenting a form of data-free knowledge distillation. However, the resultant student models show a significant drop in accuracy compared to models trained on real data. We investigate possible causes for this drop and focus on the role of the different layers of the student model. By training these layers using either real or synthetic data, we reveal that the drop mainly stems from the model's final layers. Further, we briefly investigate other factors, such as differences in data-normalization between synthetic and real, the impact of data augmentations, texture vs. shape learning, and assuming oracle prompts. While we find that some of those factors can have an impact, they are not sufficient to close the gap towards real data. Building upon our insights that mainly later layers are responsible for the drop, we investigate the data-efficiency of fine-tuning a synthetically trained model with real data applied to only those last layers. Our results suggest an improved trade-off between the amount of real training data used and the model's accuracy. Our findings contribute to the understanding of the gap between synthetic and real data and indicate solutions to mitigate the scarcity of labeled real data.
5/7/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024
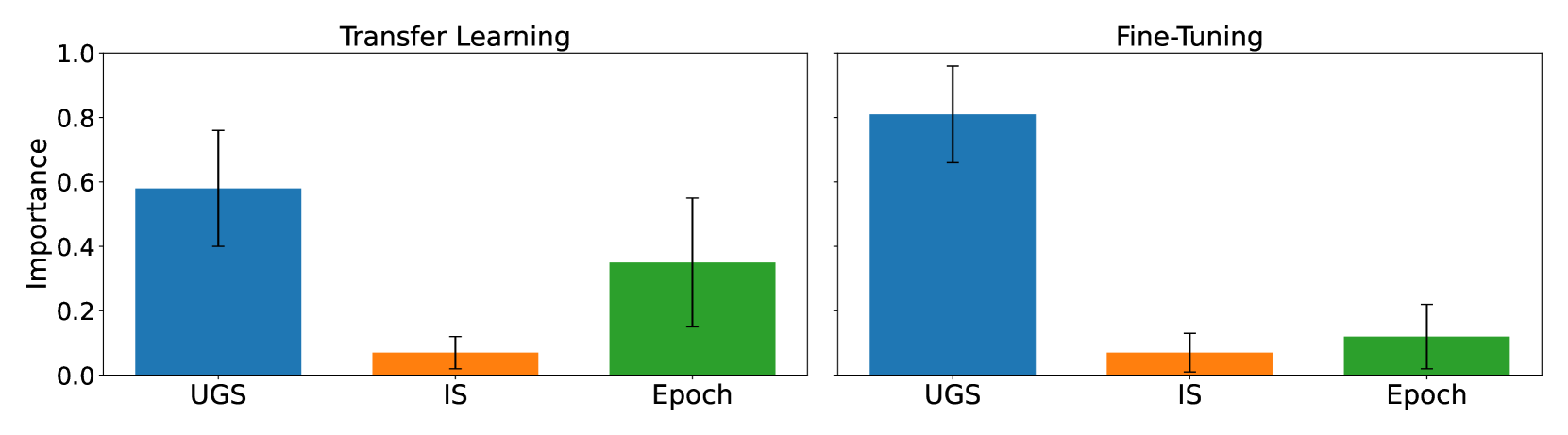
Stable Diffusion Dataset Generation for Downstream Classification Tasks
Eugenio Lomurno, Matteo D'Oria, Matteo Matteucci
0
0
Recent advances in generative artificial intelligence have enabled the creation of high-quality synthetic data that closely mimics real-world data. This paper explores the adaptation of the Stable Diffusion 2.0 model for generating synthetic datasets, using Transfer Learning, Fine-Tuning and generation parameter optimisation techniques to improve the utility of the dataset for downstream classification tasks. We present a class-conditional version of the model that exploits a Class-Encoder and optimisation of key generation parameters. Our methodology led to synthetic datasets that, in a third of cases, produced models that outperformed those trained on real datasets.
5/7/2024