How big is Big Data?

0
Sign in to get full access
Overview
- The paper discusses the challenges of developing and deploying machine learning models in practical applications.
- It explores the transferability of machine learning models across different datasets and tasks, as well as the importance of dataset development and human-AI collaboration in the machine learning process.
- The paper also covers techniques for processing MRI data and the unique challenges facing large language model development and deployment.
Plain English Explanation
The paper explores some of the key challenges in the field of machine learning. One of the main topics is transferability of models - the ability of a machine learning model trained on one dataset or task to perform well on a different dataset or task. This is an important consideration, as it can be costly and time-consuming to retrain models from scratch for every new application.
The paper also discusses the importance of dataset development and human-AI collaboration in the machine learning process. Developing high-quality datasets is crucial for training effective models, but this can be a complex and labor-intensive task. The paper suggests that involving humans in the data collection and annotation process can help improve the quality and diversity of datasets.
Another area covered in the paper is techniques for processing MRI data. MRI data poses unique challenges due to its high dimensionality and the need to preserve important spatial and temporal information. The paper explores various machine learning approaches for handling this type of data.
Finally, the paper discusses the challenges of deploying machine learning models in real-world applications. Deploying models in production environments can be significantly more complex than developing them in a research setting, and the paper examines some of the key issues that need to be addressed.
Technical Explanation
The paper begins by exploring the transferability of machine learning models. The authors discuss the importance of understanding how well a model trained on one dataset or task can perform on a different dataset or task, as this can have significant implications for the cost and efficiency of deploying models in practical applications.
The paper then delves into the topic of dataset development and human-AI collaboration. The authors argue that the quality and diversity of datasets are crucial for training effective machine learning models, but that developing high-quality datasets can be a complex and labor-intensive task. They suggest that involving humans in the data collection and annotation process can help improve the quality and diversity of datasets.
The paper also covers techniques for processing MRI data. MRI data poses unique challenges due to its high dimensionality and the need to preserve important spatial and temporal information. The authors explore various machine learning approaches, such as convolutional neural networks and recurrent neural networks, for handling this type of data.
Finally, the paper discusses the challenges of deploying machine learning models in real-world applications. The authors examine the differences between developing models in a research setting and deploying them in production environments, and the key issues that need to be addressed, such as scalability, robustness, and interpretability.
Critical Analysis
The paper presents a comprehensive overview of some of the key challenges in the field of machine learning, and the authors have done a commendable job of highlighting the importance of these issues. However, the paper does not delve deeply into potential solutions or future research directions.
For example, while the paper discusses the challenges of transferability of models, it does not provide much insight into the specific techniques or approaches that can be used to improve model transferability. Similarly, the discussion of dataset development and human-AI collaboration could be expanded to include more concrete strategies for involving humans in the data collection and annotation process.
Additionally, the techniques for processing MRI data section could be strengthened by a more thorough evaluation of the performance and limitations of the various approaches discussed, as well as a comparison to other state-of-the-art techniques in this domain.
Finally, while the paper does a good job of highlighting the challenges of deploying machine learning models in real-world applications, it could have delved deeper into potential solutions or best practices for addressing these challenges.
Overall, the paper provides a solid foundation for understanding some of the key issues in the field of machine learning, but there is room for further exploration and analysis.
Conclusion
This paper highlights several important challenges in the field of machine learning, including the transferability of models, the importance of dataset development and human-AI collaboration, techniques for processing MRI data, and the challenges of deploying machine learning models in real-world applications.
These issues are critical for the continued advancement and practical application of machine learning technologies. By addressing these challenges, researchers and practitioners can develop more robust, transferable, and deployable machine learning systems that can have a significant impact across a wide range of domains.
While the paper provides a solid foundation for understanding these key issues, there is still room for further exploration and analysis. Potential areas for future research could include developing more effective techniques for improving model transferability, designing more efficient and scalable approaches for dataset development and human-AI collaboration, and addressing the unique challenges of deploying machine learning models in complex, real-world environments.
Overall, this paper offers valuable insights into some of the critical challenges facing the machine learning community, and it serves as an important starting point for continued research and innovation in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How big is Big Data?
Daniel T. Speckhard, Tim Bechtel, Luca M. Ghiringhelli, Martin Kuban, Santiago Rigamonti, Claudia Draxl
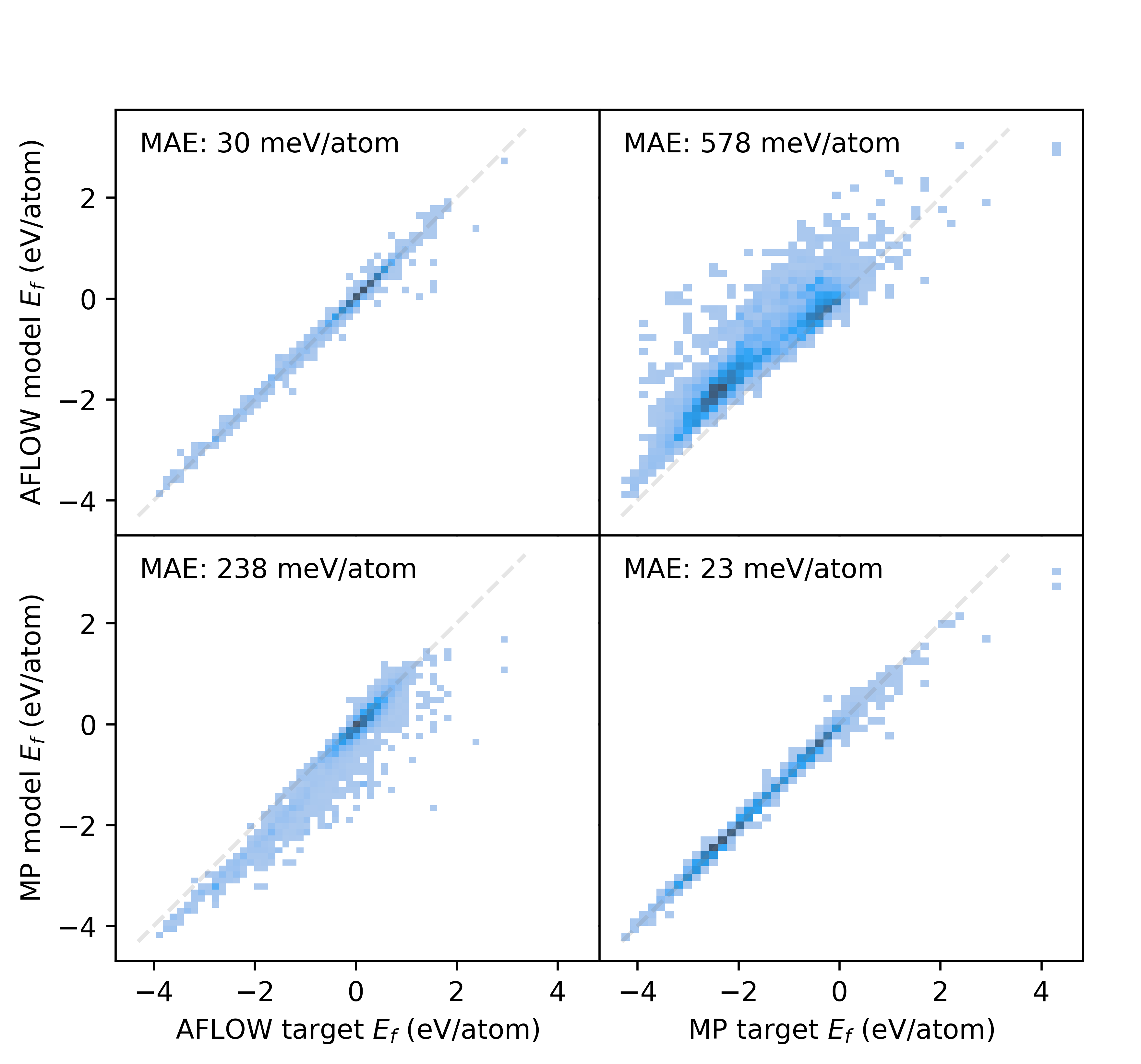
Big data has ushered in a new wave of predictive power using machine learning models. In this work, we assess what {it big} means in the context of typical materials-science machine-learning problems. This concerns not only data volume, but also data quality and veracity as much as infrastructure issues. With selected examples, we ask (i) how models generalize to similar datasets, (ii) how high-quality datasets can be gathered from heterogenous sources, (iii) how the feature set and complexity of a model can affect expressivity, and (iv) what infrastructure requirements are needed to create larger datasets and train models on them. In sum, we find that big data present unique challenges along very different aspects that should serve to motivate further work.
Read more5/21/2024

0
Data Quality in Edge Machine Learning: A State-of-the-Art Survey
Mohammed Djameleddine Belgoumri, Mohamed Reda Bouadjenek, Sunil Aryal, Hakim Hacid
Data-driven Artificial Intelligence (AI) systems trained using Machine Learning (ML) are shaping an ever-increasing (in size and importance) portion of our lives, including, but not limited to, recommendation systems, autonomous driving technologies, healthcare diagnostics, financial services, and personalized marketing. On the one hand, the outsized influence of these systems imposes a high standard of quality, particularly in the data used to train them. On the other hand, establishing and maintaining standards of Data Quality (DQ) becomes more challenging due to the proliferation of Edge Computing and Internet of Things devices, along with their increasing adoption for training and deploying ML models. The nature of the edge environment -- characterized by limited resources, decentralized data storage, and processing -- exacerbates data-related issues, making them more frequent, severe, and difficult to detect and mitigate. From these observations, it follows that DQ research for edge ML is a critical and urgent exploration track for the safety and robust usefulness of present and future AI systems. Despite this fact, DQ research for edge ML is still in its infancy. The literature on this subject remains fragmented and scattered across different research communities, with no comprehensive survey to date. Hence, this paper aims to fill this gap by providing a global view of the existing literature from multiple disciplines that can be grouped under the umbrella of DQ for edge ML. Specifically, we present a tentative definition of data quality in Edge computing, which we use to establish a set of DQ dimensions. We explore each dimension in detail, including existing solutions for mitigation.
Read more6/6/2024

0
AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Read more4/16/2024
💬
0
Challenges and Responses in the Practice of Large Language Models
Hongyin Zhu
This paper carefully summarizes extensive and profound questions from all walks of life, focusing on the current high-profile AI field, covering multiple dimensions such as industry trends, academic research, technological innovation and business applications. This paper meticulously curates questions that are both thought-provoking and practically relevant, providing nuanced and insightful answers to each. To facilitate readers' understanding and reference, this paper specifically classifies and organizes these questions systematically and meticulously from the five core dimensions of computing power infrastructure, software architecture, data resources, application scenarios, and brain science. This work aims to provide readers with a comprehensive, in-depth and cutting-edge AI knowledge framework to help people from all walks of life grasp the pulse of AI development, stimulate innovative thinking, and promote industrial progress.
Read more8/22/2024