How Can I Improve? Using GPT to Highlight the Desired and Undesired Parts of Open-ended Responses
2405.00291
0
0
Abstract
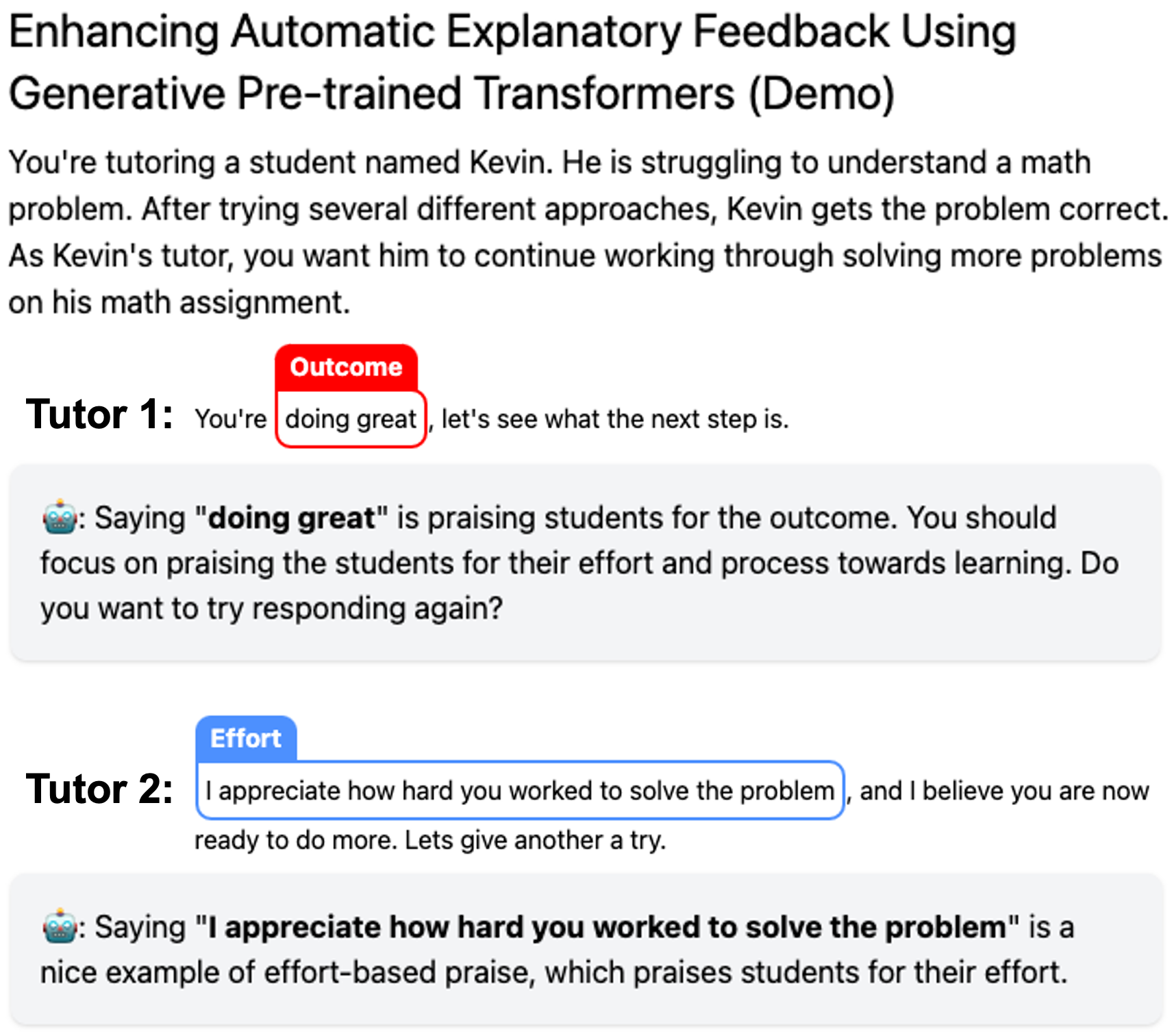
Automated explanatory feedback systems play a crucial role in facilitating learning for a large cohort of learners by offering feedback that incorporates explanations, significantly enhancing the learning process. However, delivering such explanatory feedback in real-time poses challenges, particularly when high classification accuracy for domain-specific, nuanced responses is essential. Our study leverages the capabilities of large language models, specifically Generative Pre-Trained Transformers (GPT), to explore a sequence labeling approach focused on identifying components of desired and less desired praise for providing explanatory feedback within a tutor training dataset. Our aim is to equip tutors with actionable, explanatory feedback during online training lessons. To investigate the potential of GPT models for providing the explanatory feedback, we employed two commonly-used approaches: prompting and fine-tuning. To quantify the quality of highlighted praise components identified by GPT models, we introduced a Modified Intersection over Union (M-IoU) score. Our findings demonstrate that: (1) the M-IoU score effectively correlates with human judgment in evaluating sequence quality; (2) using two-shot prompting on GPT-3.5 resulted in decent performance in recognizing effort-based (M-IoU of 0.46) and outcome-based praise (M-IoU of 0.68); and (3) our optimally fine-tuned GPT-3.5 model achieved M-IoU scores of 0.64 for effort-based praise and 0.84 for outcome-based praise, aligning with the satisfaction levels evaluated by human coders. Our results show promise for using GPT models to provide feedback that focuses on specific elements in their open-ended responses that are desirable or could use improvement.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores using GPT (Generative Pre-trained Transformer) models to automatically highlight the desired and undesired parts of open-ended responses.
- The goal is to provide feedback and suggestions for improving responses, which could be useful in educational, professional, or conversational settings.
- The authors propose a novel approach that trains a GPT model to distinguish between high-quality and low-quality responses, and then uses this model to provide targeted feedback.
Plain English Explanation
The researchers in this paper wanted to find a way to automatically identify the strong and weak parts of people's written responses, so they could get feedback on how to improve. They used a powerful language model called GPT to do this.
The basic idea is to train the GPT model to recognize the difference between "good" responses and "bad" responses. Once the model has learned this, it can then be used to analyze new responses and highlight the parts that are well-written versus the parts that need work.
This could be really helpful in situations like education, where teachers could use this tool to give students targeted feedback on their writing. It could also be useful in professional settings, where people want to improve their communication skills. Even in casual conversations, this type of feedback could help people become better at expressing themselves.
The key innovation here is using an advanced AI model like GPT to do the evaluation, rather than relying on manual review or simplistic rules. This allows the system to capture the nuances and complexities of good writing, going beyond just checking for spelling and grammar.
Technical Explanation
The authors first trained a GPT model to distinguish between high-quality and low-quality responses, using a dataset of open-ended responses that had been manually labeled. This "quality classifier" model was then used to analyze new responses and identify the specific parts that were desirable or undesirable.
To do this, the authors used a technique called "guided attention," which allowed the model to focus on the most important words or phrases when making its quality assessment. By highlighting these key parts, the system could provide targeted feedback to the user on how to improve their response.
The authors evaluated their approach on several datasets, including responses to interview questions and creative writing prompts. They found that the GPT-based system was able to accurately identify the desired and undesired elements, and that users found the feedback helpful for improving their responses.
Critical Analysis
One potential limitation of this approach is that the quality assessment is ultimately based on the subjective judgments used to label the training data. While the authors attempted to ensure consistency, there may still be some inherent biases or inconsistencies in those labels.
Additionally, the system may struggle to provide meaningful feedback on highly creative or open-ended responses that don't closely match the style of the training data. Further research would be needed to understand the boundaries of this approach and how it might be extended to handle a wider range of response types.
It's also worth considering the potential ethical implications of using an AI system to evaluate and critique human language. While the goal is to provide helpful feedback, there is a risk of the system being perceived as overly judgmental or even biased. Careful design and user testing would be needed to ensure a positive and empowering user experience.
Conclusion
Overall, this research represents an interesting step forward in using advanced language models like GPT to provide constructive feedback on open-ended responses. By automatically identifying the strengths and weaknesses of a piece of writing, the system could be a valuable tool for improving communication skills in a wide range of contexts.
However, the approach does have some limitations and potential pitfalls that would need to be carefully addressed. As AI systems become more integrated into our daily lives, it will be important to develop them in a way that is ethical, transparent, and ultimately empowering for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
How Can I Get It Right? Using GPT to Rephrase Incorrect Trainee Responses
Jionghao Lin, Zifei Han, Danielle R. Thomas, Ashish Gurung, Shivang Gupta, Vincent Aleven, Kenneth R. Koedinger
0
0
One-on-one tutoring is widely acknowledged as an effective instructional method, conditioned on qualified tutors. However, the high demand for qualified tutors remains a challenge, often necessitating the training of novice tutors (i.e., trainees) to ensure effective tutoring. Research suggests that providing timely explanatory feedback can facilitate the training process for trainees. However, it presents challenges due to the time-consuming nature of assessing trainee performance by human experts. Inspired by the recent advancements of large language models (LLMs), our study employed the GPT-4 model to build an explanatory feedback system. This system identifies trainees' responses in binary form (i.e., correct/incorrect) and automatically provides template-based feedback with responses appropriately rephrased by the GPT-4 model. We conducted our study on 410 responses from trainees across three training lessons: Giving Effective Praise, Reacting to Errors, and Determining What Students Know. Our findings indicate that: 1) using a few-shot approach, the GPT-4 model effectively identifies correct/incorrect trainees' responses from three training lessons with an average F1 score of 0.84 and an AUC score of 0.85; and 2) using the few-shot approach, the GPT-4 model adeptly rephrases incorrect trainees' responses into desired responses, achieving performance comparable to that of human experts.
5/3/2024
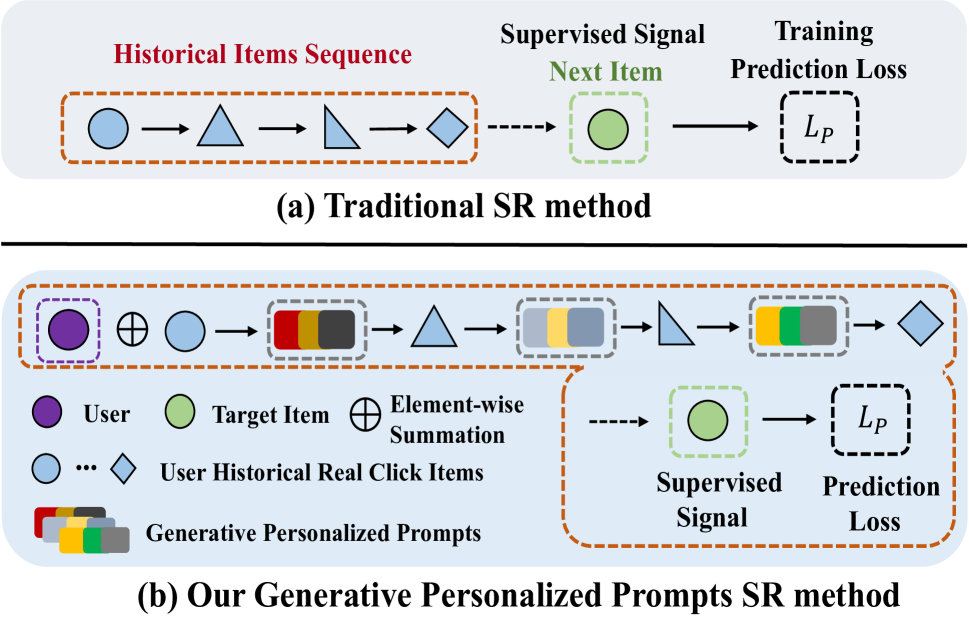
RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
Yabin Zhang, Wenhui Yu, Erhan Zhang, Xu Chen, Lantao Hu, Peng Jiang, Kun Gai
0
0
ChatGPT has achieved remarkable success in natural language understanding. Considering that recommendation is indeed a conversation between users and the system with items as words, which has similar underlying pattern with ChatGPT, we design a new chat framework in item index level for the recommendation task. Our novelty mainly contains three parts: model, training and inference. For the model part, we adopt Generative Pre-training Transformer (GPT) as the sequential recommendation model and design a user modular to capture personalized information. For the training part, we adopt the two-stage paradigm of ChatGPT, including pre-training and fine-tuning. In the pre-training stage, we train GPT model by auto-regression. In the fine-tuning stage, we train the model with prompts, which include both the newly-generated results from the model and the user's feedback. For the inference part, we predict several user interests as user representations in an autoregressive manner. For each interest vector, we recall several items with the highest similarity and merge the items recalled by all interest vectors into the final result. We conduct experiments with both offline public datasets and online A/B test to demonstrate the effectiveness of our proposed method.
4/16/2024
📊
Beyond Generating Code: Evaluating GPT on a Data Visualization Course
Chen Zhu-Tian, Chenyang Zhang, Qianwen Wang, Jakob Troidl, Simon Warchol, Johanna Beyer, Nils Gehlenborg, Hanspeter Pfister
0
0
This paper presents an empirical evaluation of the performance of the Generative Pre-trained Transformer (GPT) model in Harvard's CS171 data visualization course. While previous studies have focused on GPT's ability to generate code for visualizations, this study goes beyond code generation to evaluate GPT's abilities in various visualization tasks, such as data interpretation, visualization design, visual data exploration, and insight communication. The evaluation utilized GPT-3.5 and GPT-4 to complete assignments of CS171, and included a quantitative assessment based on the established course rubrics, a qualitative analysis informed by the feedback of three experienced graders, and an exploratory study of GPT's capabilities in completing border visualization tasks. Findings show that GPT-4 scored 80% on quizzes and homework, and TFs could distinguish between GPT- and human-generated homework with 70% accuracy. The study also demonstrates GPT's potential in completing various visualization tasks, such as data cleanup, interaction with visualizations, and insight communication. The paper concludes by discussing the strengths and limitations of GPT in data visualization, potential avenues for incorporating GPT in broader visualization tasks, and the need to redesign visualization education.
5/14/2024
💬
Open Source Language Models Can Provide Feedback: Evaluating LLMs' Ability to Help Students Using GPT-4-As-A-Judge
Charles Koutcheme, Nicola Dainese, Sami Sarsa, Arto Hellas, Juho Leinonen, Paul Denny
0
0
Large language models (LLMs) have shown great potential for the automatic generation of feedback in a wide range of computing contexts. However, concerns have been voiced around the privacy and ethical implications of sending student work to proprietary models. This has sparked considerable interest in the use of open source LLMs in education, but the quality of the feedback that such open models can produce remains understudied. This is a concern as providing flawed or misleading generated feedback could be detrimental to student learning. Inspired by recent work that has utilised very powerful LLMs, such as GPT-4, to evaluate the outputs produced by less powerful models, we conduct an automated analysis of the quality of the feedback produced by several open source models using a dataset from an introductory programming course. First, we investigate the viability of employing GPT-4 as an automated evaluator by comparing its evaluations with those of a human expert. We observe that GPT-4 demonstrates a bias toward positively rating feedback while exhibiting moderate agreement with human raters, showcasing its potential as a feedback evaluator. Second, we explore the quality of feedback generated by several leading open-source LLMs by using GPT-4 to evaluate the feedback. We find that some models offer competitive performance with popular proprietary LLMs, such as ChatGPT, indicating opportunities for their responsible use in educational settings.
5/9/2024