Open Source Language Models Can Provide Feedback: Evaluating LLMs' Ability to Help Students Using GPT-4-As-A-Judge
2405.05253
0
0
💬
Abstract
Large language models (LLMs) have shown great potential for the automatic generation of feedback in a wide range of computing contexts. However, concerns have been voiced around the privacy and ethical implications of sending student work to proprietary models. This has sparked considerable interest in the use of open source LLMs in education, but the quality of the feedback that such open models can produce remains understudied. This is a concern as providing flawed or misleading generated feedback could be detrimental to student learning. Inspired by recent work that has utilised very powerful LLMs, such as GPT-4, to evaluate the outputs produced by less powerful models, we conduct an automated analysis of the quality of the feedback produced by several open source models using a dataset from an introductory programming course. First, we investigate the viability of employing GPT-4 as an automated evaluator by comparing its evaluations with those of a human expert. We observe that GPT-4 demonstrates a bias toward positively rating feedback while exhibiting moderate agreement with human raters, showcasing its potential as a feedback evaluator. Second, we explore the quality of feedback generated by several leading open-source LLMs by using GPT-4 to evaluate the feedback. We find that some models offer competitive performance with popular proprietary LLMs, such as ChatGPT, indicating opportunities for their responsible use in educational settings.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of large language models (LLMs) to automatically generate feedback on student work, particularly in educational settings.
- Concerns have been raised about the privacy and ethical implications of using proprietary LLMs like GPT-4 to evaluate student work.
- This has sparked interest in using open-source LLMs, but the quality of the feedback they can produce is not well-studied.
- The paper aims to evaluate the quality of feedback generated by several open-source LLMs and compare them to the feedback generated by the powerful GPT-4 model.
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text, and they have shown promise in automatically providing feedback on student work. However, there are concerns about using proprietary LLMs like GPT-4 to evaluate student work, as this could raise privacy and ethical issues.
To address this, researchers are interested in using open-source LLMs, which are freely available, to provide feedback. But it's not clear how well these open-source models can perform compared to more powerful proprietary LLMs. The researchers in this paper wanted to find out.
First, they used GPT-4 to evaluate the feedback generated by several open-source LLMs. They found that some of the open-source models performed quite well, even compared to the popular ChatGPT model. This suggests that open-source LLMs could be used responsibly in educational settings to provide feedback to students.
Technical Explanation
The researchers first investigated the viability of using GPT-4 as an automated evaluator of feedback quality by comparing its evaluations to those of a human expert. They found that GPT-4 tended to rate feedback more positively but still showed moderate agreement with the human rater, suggesting its potential as a feedback evaluator.
Next, the researchers used GPT-4 to evaluate the quality of feedback generated by several leading open-source LLMs, including BLOOM, Dolly, and GPT-J. They found that some of these open-source models offered competitive performance with the popular proprietary model, ChatGPT, indicating opportunities for their responsible use in educational settings.
Critical Analysis
The researchers acknowledged that while their findings suggest open-source LLMs can provide high-quality feedback, further research is needed to fully understand the implications and limitations of using these models in educational contexts. Factors such as potential biases, the consistency of feedback quality, and the impact on student learning should be examined more closely.
Additionally, the use of GPT-4 as an evaluator of feedback quality, while justified in this study, may not capture all nuances of human feedback. Exploring alternative evaluation methods, potentially involving larger panels of human raters, could provide a more comprehensive assessment of the feedback quality.
Conclusion
This research suggests that open-source LLMs, when properly evaluated and deployed, could offer a viable alternative to proprietary models for providing automated feedback in educational settings. By exploring the capabilities of these open-source models, the researchers have taken an important step towards addressing the privacy and ethical concerns associated with the use of proprietary LLMs in education. Further research in this area could lead to more equitable and accessible educational tools powered by large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
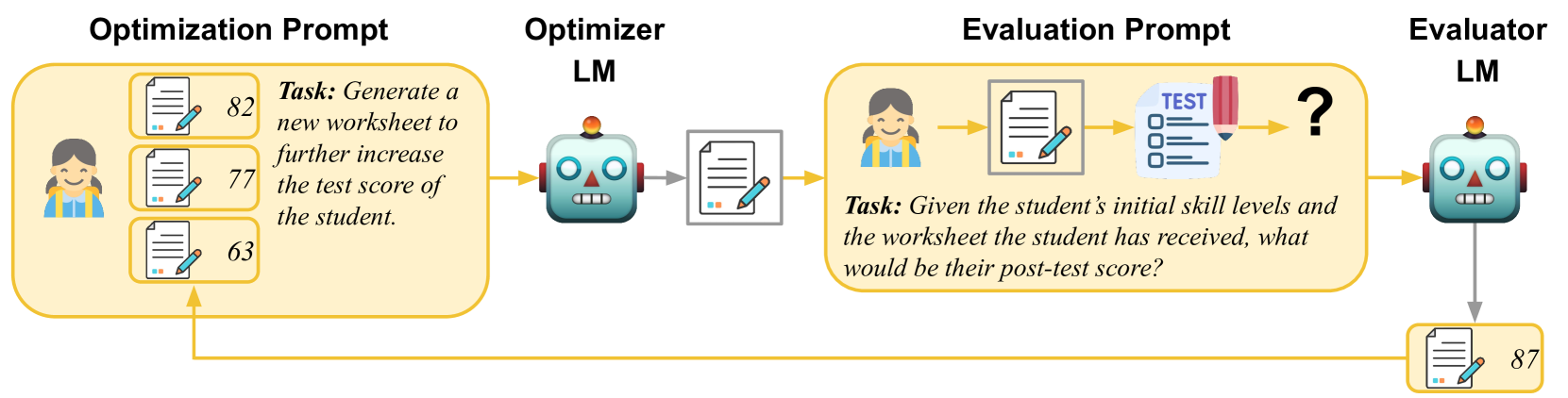
Evaluating and Optimizing Educational Content with Large Language Model Judgments
Joy He-Yueya, Noah D. Goodman, Emma Brunskill
0
0
Creating effective educational materials generally requires expensive and time-consuming studies of student learning outcomes. To overcome this barrier, one idea is to build computational models of student learning and use them to optimize instructional materials. However, it is difficult to model the cognitive processes of learning dynamics. We propose an alternative approach that uses Language Models (LMs) as educational experts to assess the impact of various instructions on learning outcomes. Specifically, we use GPT-3.5 to evaluate the overall effect of instructional materials on different student groups and find that it can replicate well-established educational findings such as the Expertise Reversal Effect and the Variability Effect. This demonstrates the potential of LMs as reliable evaluators of educational content. Building on this insight, we introduce an instruction optimization approach in which one LM generates instructional materials using the judgments of another LM as a reward function. We apply this approach to create math word problem worksheets aimed at maximizing student learning gains. Human teachers' evaluations of these LM-generated worksheets show a significant alignment between the LM judgments and human teacher preferences. We conclude by discussing potential divergences between human and LM opinions and the resulting pitfalls of automating instructional design.
5/7/2024
💬
Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
Owen Henkel, Adam Boxer, Libby Hills, Bill Roberts
0
0
This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
5/7/2024

The Effectiveness of LLMs as Annotators: A Comparative Overview and Empirical Analysis of Direct Representation
Maja Pavlovic, Massimo Poesio
0
0
Large Language Models (LLMs) have emerged as powerful support tools across various natural language tasks and a range of application domains. Recent studies focus on exploring their capabilities for data annotation. This paper provides a comparative overview of twelve studies investigating the potential of LLMs in labelling data. While the models demonstrate promising cost and time-saving benefits, there exist considerable limitations, such as representativeness, bias, sensitivity to prompt variations and English language preference. Leveraging insights from these studies, our empirical analysis further examines the alignment between human and GPT-generated opinion distributions across four subjective datasets. In contrast to the studies examining representation, our methodology directly obtains the opinion distribution from GPT. Our analysis thereby supports the minority of studies that are considering diverse perspectives when evaluating data annotation tasks and highlights the need for further research in this direction.
5/3/2024

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024