How Control Information Influences Multilingual Text Image Generation and Editing?

0

Sign in to get full access
Overview
- This paper investigates how control information influences the generation and editing of multilingual text-to-image models.
- The authors explore using different types of control information, such as AnyControl, FlexeControl, Mask-ControlNet, Ctrl-X, and ControlNet, to guide the text-to-image generation and editing process.
- The paper presents experiments and analyses to understand the impact of different control information on the quality, diversity, and coherence of the generated images.
Plain English Explanation
This research explores how providing extra information, or "control information," can influence the way text-to-image AI models generate and edit images. Text-to-image models are AI systems that can create images based on text descriptions. The researchers looked at different types of control information, like providing detailed instructions or sketches, and studied how that affected the quality, variety, and consistency of the generated images.
The key idea is that by giving the AI more guidance and constraints, it can produce images that better match the intended description or desired visual style. For example, providing a rough sketch of the scene could help the AI generate an image that captures the overall layout and composition, rather than just randomly generating an image from the text alone.
The researchers tested several approaches to incorporating control information, like AnyControl, FlexeControl, and ControlNet. They then analyzed the quality, diversity, and coherence of the generated images to understand the impact of these different control strategies.
Overall, the findings suggest that providing the right type and amount of control information can significantly improve the capabilities of text-to-image AI systems, making them more useful for practical applications like digital art creation, product design, and even education.
Technical Explanation
The paper investigates how different types of control information can influence the performance of multilingual text-to-image generation and editing models. The authors explore the use of various control strategies, including AnyControl, FlexeControl, Mask-ControlNet, Ctrl-X, and ControlNet.
The experiments involve generating and editing images in multiple languages, and evaluating the generated images based on metrics such as quality, diversity, and coherence. The authors analyze the impact of different control information on these metrics, providing insights into the trade-offs and best practices for incorporating control strategies into text-to-image models.
The findings suggest that the choice of control information can have a significant impact on the performance of text-to-image systems, and that there is no one-size-fits-all solution. The researchers identify specific strengths and weaknesses of the various control strategies, and discuss the implications for the design and deployment of practical text-to-image applications.
Critical Analysis
The paper provides a comprehensive and rigorous investigation of the impact of control information on multilingual text-to-image generation and editing. The authors have carefully designed their experiments and used appropriate evaluation metrics to assess the performance of the different control strategies.
One potential limitation of the study is that it focuses primarily on quantitative metrics, such as image quality and diversity, and does not delve deeply into the qualitative aspects of the generated images. It would be interesting to see a more detailed analysis of the semantic and aesthetic properties of the images, as well as user-centric evaluations to understand the practical usefulness of the control strategies.
Additionally, the paper does not explore the potential biases or fairness implications of the different control strategies, particularly in the context of multilingual text-to-image generation. As these models become more widely deployed, it will be important to investigate how control information may amplify or mitigate biases in the generated content.
Overall, the paper makes a valuable contribution to the understanding of how control information can influence the performance of text-to-image models. The findings could inform the design of more effective and versatile text-to-image systems for a variety of applications, while also highlighting the need for continued research into the ethical and societal implications of these technologies.
Conclusion
This research paper investigates how different types of control information can impact the generation and editing of multilingual text-to-image models. The authors explore the use of various control strategies, such as AnyControl, FlexeControl, and ControlNet, and analyze their effects on the quality, diversity, and coherence of the generated images.
The findings suggest that the choice of control information can have a significant influence on the performance of text-to-image systems, and that there is no one-size-fits-all solution. The researchers provide insights into the trade-offs and best practices for incorporating control strategies, which could inform the design of more effective and versatile text-to-image applications.
At the same time, the paper highlights the need for further research into the qualitative and ethical implications of these technologies, particularly in the context of multilingual and diverse user populations. As text-to-image models become more widely deployed, it will be crucial to ensure that they are designed and used in a way that promotes fairness, inclusivity, and responsible innovation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Control Information Influences Multilingual Text Image Generation and Editing?
Boqiang Zhang, Zuan Gao, Yadong Qu, Hongtao Xie
Visual text generation has significantly advanced through diffusion models aimed at producing images with readable and realistic text. Recent works primarily use a ControlNet-based framework, employing standard font text images to control diffusion models. Recognizing the critical role of control information in generating high-quality text, we investigate its influence from three perspectives: input encoding, role at different stages, and output features. Our findings reveal that: 1) Input control information has unique characteristics compared to conventional inputs like Canny edges and depth maps. 2) Control information plays distinct roles at different stages of the denoising process. 3) Output control features significantly differ from the base and skip features of the U-Net decoder in the frequency domain. Based on these insights, we propose TextGen, a novel framework designed to enhance generation quality by optimizing control information. We improve input and output features using Fourier analysis to emphasize relevant information and reduce noise. Additionally, we employ a two-stage generation framework to align the different roles of control information at different stages. Furthermore, we introduce an effective and lightweight dataset for training. Our method achieves state-of-the-art performance in both Chinese and English text generation. The code and dataset available at https://github.com/CyrilSterling/TextGen.
Read more7/23/2024

0
ControlNet-XS: Rethinking the Control of Text-to-Image Diffusion Models as Feedback-Control Systems
Denis Zavadski, Johann-Friedrich Feiden, Carsten Rother
The field of image synthesis has made tremendous strides forward in the last years. Besides defining the desired output image with text-prompts, an intuitive approach is to additionally use spatial guidance in form of an image, such as a depth map. In state-of-the-art approaches, this guidance is realized by a separate controlling model that controls a pre-trained image generation network, such as a latent diffusion model. Understanding this process from a control system perspective shows that it forms a feedback-control system, where the control module receives a feedback signal from the generation process and sends a corrective signal back. When analysing existing systems, we observe that the feedback signals are timely sparse and have a small number of bits. As a consequence, there can be long delays between newly generated features and the respective corrective signals for these features. It is known that this delay is the most unwanted aspect of any control system. In this work, we take an existing controlling network (ControlNet) and change the communication between the controlling network and the generation process to be of high-frequency and with large-bandwidth. By doing so, we are able to considerably improve the quality of the generated images, as well as the fidelity of the control. Also, the controlling network needs noticeably fewer parameters and hence is about twice as fast during inference and training time. Another benefit of small-sized models is that they help to democratise our field and are likely easier to understand. We call our proposed network ControlNet-XS. When comparing with the state-of-the-art approaches, we outperform them for pixel-level guidance, such as depth, canny-edges, and semantic segmentation, and are on a par for loose keypoint-guidance of human poses. All code and pre-trained models will be made publicly available.
Read more8/13/2024
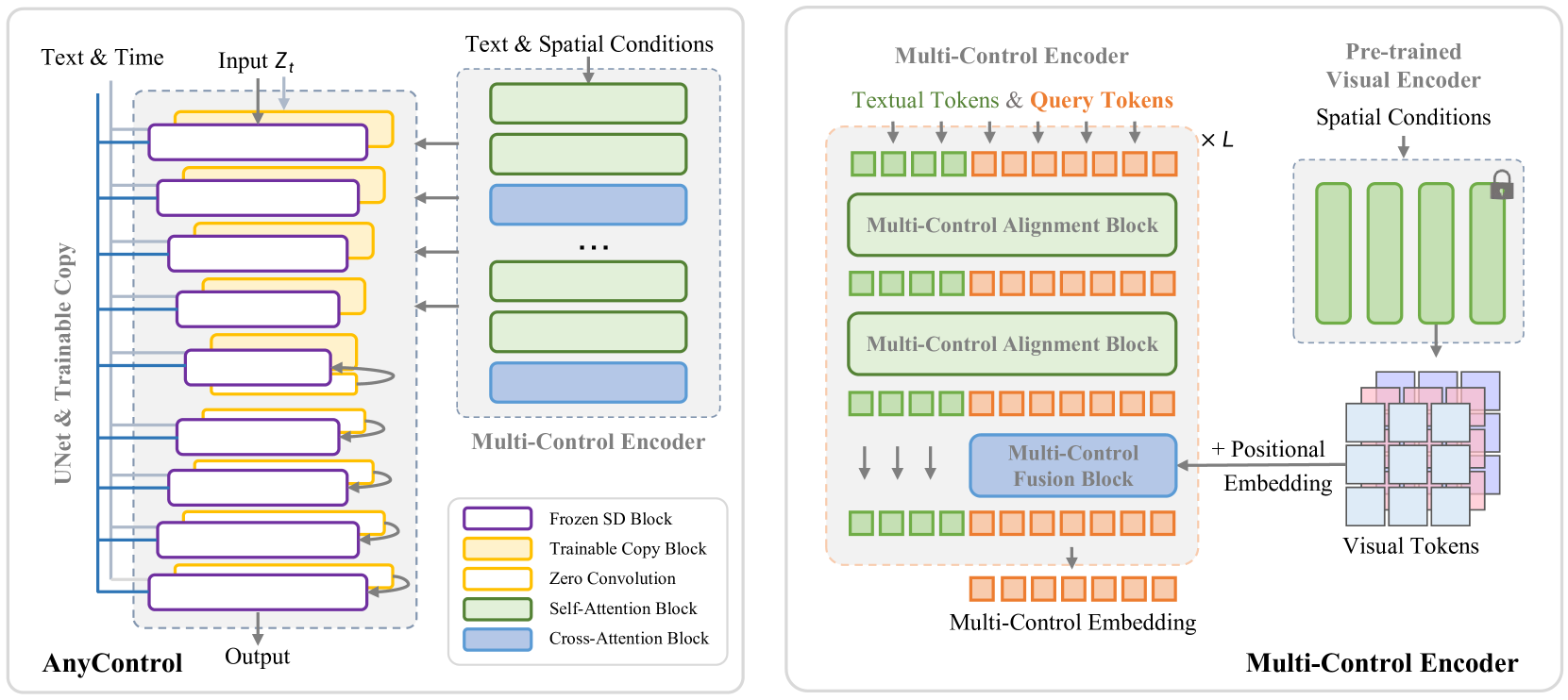
0
AnyControl: Create Your Artwork with Versatile Control on Text-to-Image Generation
Yanan Sun, Yanchen Liu, Yinhao Tang, Wenjie Pei, Kai Chen
The field of text-to-image (T2I) generation has made significant progress in recent years, largely driven by advancements in diffusion models. Linguistic control enables effective content creation, but struggles with fine-grained control over image generation. This challenge has been explored, to a great extent, by incorporating additional user-supplied spatial conditions, such as depth maps and edge maps, into pre-trained T2I models through extra encoding. However, multi-control image synthesis still faces several challenges. Specifically, current approaches are limited in handling free combinations of diverse input control signals, overlook the complex relationships among multiple spatial conditions, and often fail to maintain semantic alignment with provided textual prompts. This can lead to suboptimal user experiences. To address these challenges, we propose AnyControl, a multi-control image synthesis framework that supports arbitrary combinations of diverse control signals. AnyControl develops a novel Multi-Control Encoder that extracts a unified multi-modal embedding to guide the generation process. This approach enables a holistic understanding of user inputs, and produces high-quality, faithful results under versatile control signals, as demonstrated by extensive quantitative and qualitative evaluations. Our project page is available in https://any-control.github.io.
Read more7/19/2024
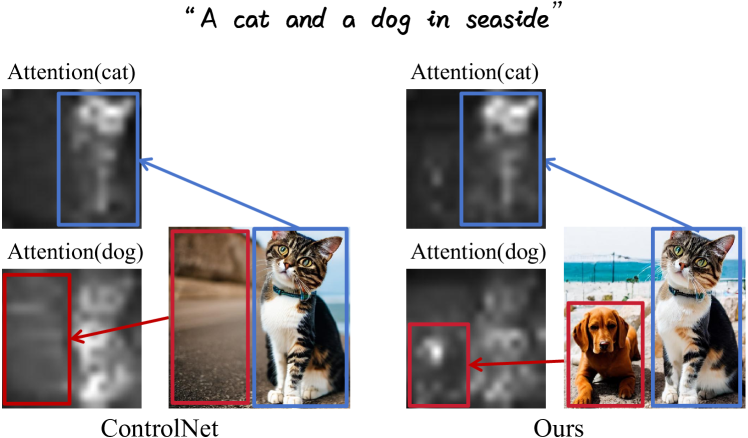
0
Local Conditional Controlling for Text-to-Image Diffusion Models
Yibo Zhao, Liang Peng, Yang Yang, Zekai Luo, Hengjia Li, Yao Chen, Zheng Yang, Xiaofei He, Wei Zhao, qinglin lu, Boxi Wu, Wei Liu
Diffusion models have exhibited impressive prowess in the text-to-image task. Recent methods add image-level structure controls, e.g., edge and depth maps, to manipulate the generation process together with text prompts to obtain desired images. This controlling process is globally operated on the entire image, which limits the flexibility of control regions. In this paper, we explore a novel and practical task setting: local control. It focuses on controlling specific local region according to user-defined image conditions, while the remaining regions are only conditioned by the original text prompt. However, it is non-trivial to achieve local conditional controlling. The naive manner of directly adding local conditions may lead to the local control dominance problem, which forces the model to focus on the controlled region and neglect object generation in other regions. To mitigate this problem, we propose Regional Discriminate Loss to update the noised latents, aiming at enhanced object generation in non-control regions. Furthermore, the proposed Focused Token Response suppresses weaker attention scores which lack the strongest response to enhance object distinction and reduce duplication. Lastly, we adopt Feature Mask Constraint to reduce quality degradation in images caused by information differences across the local control region. All proposed strategies are operated at the inference stage. Extensive experiments demonstrate that our method can synthesize high-quality images aligned with the text prompt under local control conditions.
Read more8/23/2024