Local Conditional Controlling for Text-to-Image Diffusion Models

0
Sign in to get full access
Overview
- This paper proposes a method called Local Conditional Controlling (LCC) to improve the controllability and quality of text-to-image diffusion models.
- LCC allows for fine-grained control over the output image by conditioning the diffusion process on local image regions and text descriptions.
- The method is evaluated on several benchmarks, demonstrating improved performance compared to previous approaches.
Plain English Explanation
The paper describes a technique called Local Conditional Controlling (LCC) that helps improve the ability to control and generate high-quality images from text descriptions using diffusion models. Diffusion models are a type of machine learning model that can create images from scratch.
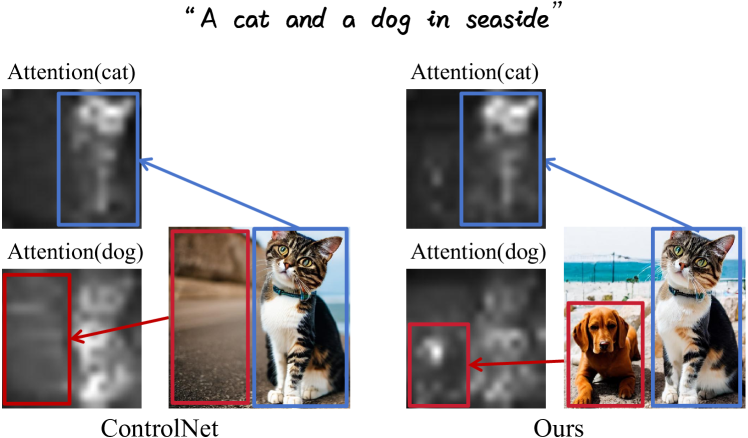
LCC works by breaking down the image into smaller local regions and then conditioning the diffusion process on both the text description and the properties of those local regions. This allows the model to have fine-grained control over the different parts of the final image, rather than just trying to create the whole image at once based on the text.
The researchers tested LCC on several standard benchmarks for text-to-image generation and found that it outperformed previous approaches in terms of the quality and controllability of the generated images. This suggests that the LCC technique is a promising way to improve the capabilities of text-to-image diffusion models.
Technical Explanation
The paper introduces a method called Local Conditional Controlling (LCC) to enhance the controllability and quality of text-to-image diffusion models. Text-to-image diffusion models are a type of machine learning model that can generate images from textual descriptions.
LCC works by conditioning the diffusion process not only on the global text description, but also on local image regions. Specifically, the model first divides the target image into a grid of local patches. It then conditions the diffusion process on both the text description and the properties of each local patch, allowing for fine-grained control over the final image.
The researchers evaluate LCC on several benchmark datasets for text-to-image generation, including COCO and FashionGen. The results show that LCC outperforms previous state-of-the-art approaches in terms of both image quality and controllability metrics. This suggests that the local conditioning approach is an effective way to improve the capabilities of text-to-image diffusion models.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the proposed LCC technique, testing it on multiple datasets and comparing it to prior methods. The results demonstrate clear performance improvements, which is promising for advancing the field of text-to-image generation.
However, the paper does not discuss any potential limitations or caveats of the LCC approach. For example, it's unclear how the method would scale to higher-resolution images or more complex text descriptions. Additionally, the paper does not explore potential biases or failures cases of the model, which would be important to understand.
Further research could investigate the interpretability of the LCC model, examining how the different local conditions influence the final image output. It would also be valuable to analyze the types of images and text prompts where LCC excels compared to other techniques.
Conclusion
This paper introduces a new method called Local Conditional Controlling (LCC) that improves the controllability and quality of text-to-image diffusion models. By conditioning the diffusion process on both the global text description and the local properties of image regions, LCC allows for fine-grained control over the generated output.
The experimental results show that LCC outperforms previous state-of-the-art approaches on several benchmark datasets. This suggests that the local conditioning approach is a promising direction for advancing the capabilities of text-to-image generation systems. Further research is needed to fully understand the strengths, limitations, and potential biases of the LCC technique.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Local Conditional Controlling for Text-to-Image Diffusion Models
Yibo Zhao, Liang Peng, Yang Yang, Zekai Luo, Hengjia Li, Yao Chen, Zheng Yang, Xiaofei He, Wei Zhao, qinglin lu, Boxi Wu, Wei Liu
Diffusion models have exhibited impressive prowess in the text-to-image task. Recent methods add image-level structure controls, e.g., edge and depth maps, to manipulate the generation process together with text prompts to obtain desired images. This controlling process is globally operated on the entire image, which limits the flexibility of control regions. In this paper, we explore a novel and practical task setting: local control. It focuses on controlling specific local region according to user-defined image conditions, while the remaining regions are only conditioned by the original text prompt. However, it is non-trivial to achieve local conditional controlling. The naive manner of directly adding local conditions may lead to the local control dominance problem, which forces the model to focus on the controlled region and neglect object generation in other regions. To mitigate this problem, we propose Regional Discriminate Loss to update the noised latents, aiming at enhanced object generation in non-control regions. Furthermore, the proposed Focused Token Response suppresses weaker attention scores which lack the strongest response to enhance object distinction and reduce duplication. Lastly, we adopt Feature Mask Constraint to reduce quality degradation in images caused by information differences across the local control region. All proposed strategies are operated at the inference stage. Extensive experiments demonstrate that our method can synthesize high-quality images aligned with the text prompt under local control conditions.
Read more8/23/2024
🖼️
0
Enhancing Image Layout Control with Loss-Guided Diffusion Models
Zakaria Patel, Kirill Serkh
Diffusion models are a powerful class of generative models capable of producing high-quality images from pure noise using a simple text prompt. While most methods which introduce additional spatial constraints into the generated images (e.g., bounding boxes) require fine-tuning, a smaller and more recent subset of these methods take advantage of the models' attention mechanism, and are training-free. These methods generally fall into one of two categories. The first entails modifying the cross-attention maps of specific tokens directly to enhance the signal in certain regions of the image. The second works by defining a loss function over the cross-attention maps, and using the gradient of this loss to guide the latent. While previous work explores these as alternative strategies, we provide an interpretation for these methods which highlights their complimentary features, and demonstrate that it is possible to obtain superior performance when both methods are used in concert.
Read more9/18/2024

0
Mask-ControlNet: Higher-Quality Image Generation with An Additional Mask Prompt
Zhiqi Huang, Huixin Xiong, Haoyu Wang, Longguang Wang, Zhiheng Li
Text-to-image generation has witnessed great progress, especially with the recent advancements in diffusion models. Since texts cannot provide detailed conditions like object appearance, reference images are usually leveraged for the control of objects in the generated images. However, existing methods still suffer limited accuracy when the relationship between the foreground and background is complicated. To address this issue, we develop a framework termed Mask-ControlNet by introducing an additional mask prompt. Specifically, we first employ large vision models to obtain masks to segment the objects of interest in the reference image. Then, the object images are employed as additional prompts to facilitate the diffusion model to better understand the relationship between foreground and background regions during image generation. Experiments show that the mask prompts enhance the controllability of the diffusion model to maintain higher fidelity to the reference image while achieving better image quality. Comparison with previous text-to-image generation methods demonstrates our method's superior quantitative and qualitative performance on the benchmark datasets.
Read more4/9/2024

0
How Control Information Influences Multilingual Text Image Generation and Editing?
Boqiang Zhang, Zuan Gao, Yadong Qu, Hongtao Xie
Visual text generation has significantly advanced through diffusion models aimed at producing images with readable and realistic text. Recent works primarily use a ControlNet-based framework, employing standard font text images to control diffusion models. Recognizing the critical role of control information in generating high-quality text, we investigate its influence from three perspectives: input encoding, role at different stages, and output features. Our findings reveal that: 1) Input control information has unique characteristics compared to conventional inputs like Canny edges and depth maps. 2) Control information plays distinct roles at different stages of the denoising process. 3) Output control features significantly differ from the base and skip features of the U-Net decoder in the frequency domain. Based on these insights, we propose TextGen, a novel framework designed to enhance generation quality by optimizing control information. We improve input and output features using Fourier analysis to emphasize relevant information and reduce noise. Additionally, we employ a two-stage generation framework to align the different roles of control information at different stages. Furthermore, we introduce an effective and lightweight dataset for training. Our method achieves state-of-the-art performance in both Chinese and English text generation. The code and dataset available at https://github.com/CyrilSterling/TextGen.
Read more7/23/2024