How Do You Perceive My Face? Recognizing Facial Expressions in Multi-Modal Context by Modeling Mental Representations

0
🛠️
Sign in to get full access
Overview
- Facial expressions are an important means of communication, but their perception relies on prior knowledge and contextual cues.
- Multi-modal emotional context, such as voice, text, and body language, can influence how people perceive facial expressions.
- This paper introduces a novel approach for facial expression classification that goes beyond simple classification tasks.
- The model accurately classifies a perceived face and synthesizes the corresponding mental representation perceived by a human when observing a face in context.
Plain English Explanation
When we see a person's face, we don't just look at the features - we also take into account other cues like their tone of voice, the words they're using, and their body language. All of these things influence how we interpret the emotion behind their facial expression. This paper presents a new way of classifying facial expressions that aims to capture this more nuanced, contextual understanding.
The model in this paper doesn't just identify the emotion being expressed on a face. It also tries to recreate the mental representation that a human would have when seeing that face in a particular context. So it's not just about recognizing the expression, but understanding how a person would perceive and interpret that expression.
To do this, the model learns two separate representations - one for the content of the face itself, and one for the context around it. It then uses a novel attention mechanism to adapt the facial features based on the context, which allows it to generate a version of the expression that reflects how a human would see it.
The researchers tested this model on two popular facial expression datasets and found that it was able to achieve state-of-the-art classification accuracy. They also had people evaluate the synthesized expressions, and found that the model was able to effectively approximate human mental representations.
Technical Explanation
The key innovation in this paper is the use of a VAE-GAN architecture to learn separate representations for the content (the facial features) and context (such as voice, text, body language) of a facial expression. This allows the model to adapt the facial features based on the surrounding context, which is crucial for accurately capturing how humans perceive emotional expressions.
The context-dependent feature adaptation is achieved through a novel attention mechanism that selectively attends to relevant contextual cues when processing the facial features. This adapted representation is then used for both classification of the expression and generation of a context-augmented version of the expression.
The researchers evaluated their model on the RAVDESS and MEAD datasets, achieving state-of-the-art classification accuracies of 81.01% and 79.34% respectively. They also conducted a human study to assess the synthesized expressions, finding that the model was able to effectively produce approximations of human mental representations.
Critical Analysis
The paper presents a compelling approach to facial expression recognition that goes beyond simple classification by incorporating contextual information. The use of separate content and context representations, along with the novel attention mechanism, is a clever way to capture the nuanced way humans perceive emotions.
However, the paper does not address some potential limitations of this approach. For example, the model may struggle to generalize to contexts or expressions that are not well-represented in the training data. Additionally, the reliance on relatively small, curated datasets like RAVDESS and MEAD raises questions about the model's performance in more realistic, unconstrained settings.
It would also be interesting to see how this approach compares to other multimodal or knowledge-based techniques for facial expression recognition. Exploring the model's ability to integrate 3D face representations could also be a fruitful area for further research.
Conclusion
This paper presents an innovative approach to facial expression classification that goes beyond simple recognition by incorporating contextual information. By learning separate representations for content and context, and using a novel attention mechanism to adapt the facial features, the model is able to generate synthesized expressions that effectively approximate human mental representations.
While the paper demonstrates state-of-the-art performance on curated datasets, further research is needed to understand the model's limitations and explore how it compares to other multimodal and knowledge-based techniques. Nonetheless, this work represents an important step forward in the field of facial expression recognition, with potential applications in areas like human-computer interaction, mental health monitoring, and social robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
How Do You Perceive My Face? Recognizing Facial Expressions in Multi-Modal Context by Modeling Mental Representations
Florian Blume, Runfeng Qu, Pia Bideau, Martin Maier, Rasha Abdel Rahman, Olaf Hellwich
Facial expression perception in humans inherently relies on prior knowledge and contextual cues, contributing to efficient and flexible processing. For instance, multi-modal emotional context (such as voice color, affective text, body pose, etc.) can prompt people to perceive emotional expressions in objectively neutral faces. Drawing inspiration from this, we introduce a novel approach for facial expression classification that goes beyond simple classification tasks. Our model accurately classifies a perceived face and synthesizes the corresponding mental representation perceived by a human when observing a face in context. With this, our model offers visual insights into its internal decision-making process. We achieve this by learning two independent representations of content and context using a VAE-GAN architecture. Subsequently, we propose a novel attention mechanism for context-dependent feature adaptation. The adapted representation is used for classification and to generate a context-augmented expression. We evaluate synthesized expressions in a human study, showing that our model effectively produces approximations of human mental representations. We achieve State-of-the-Art classification accuracies of 81.01% on the RAVDESS dataset and 79.34% on the MEAD dataset. We make our code publicly available.
Read more9/5/2024
0
Multi-Task Multi-Modal Self-Supervised Learning for Facial Expression Recognition
Marah Halawa, Florian Blume, Pia Bideau, Martin Maier, Rasha Abdel Rahman, Olaf Hellwich
Human communication is multi-modal; e.g., face-to-face interaction involves auditory signals (speech) and visual signals (face movements and hand gestures). Hence, it is essential to exploit multiple modalities when designing machine learning-based facial expression recognition systems. In addition, given the ever-growing quantities of video data that capture human facial expressions, such systems should utilize raw unlabeled videos without requiring expensive annotations. Therefore, in this work, we employ a multitask multi-modal self-supervised learning method for facial expression recognition from in-the-wild video data. Our model combines three self-supervised objective functions: First, a multi-modal contrastive loss, that pulls diverse data modalities of the same video together in the representation space. Second, a multi-modal clustering loss that preserves the semantic structure of input data in the representation space. Finally, a multi-modal data reconstruction loss. We conduct a comprehensive study on this multimodal multi-task self-supervised learning method on three facial expression recognition benchmarks. To that end, we examine the performance of learning through different combinations of self-supervised tasks on the facial expression recognition downstream task. Our model ConCluGen outperforms several multi-modal self-supervised and fully supervised baselines on the CMU-MOSEI dataset. Our results generally show that multi-modal self-supervision tasks offer large performance gains for challenging tasks such as facial expression recognition, while also reducing the amount of manual annotations required. We release our pre-trained models as well as source code publicly
Read more9/5/2024

0
Post-hoc and manifold explanations analysis of facial expression data based on deep learning
Yang Xiao
The complex information processing system of humans generates a lot of objective and subjective evaluations, making the exploration of human cognitive products of great cutting-edge theoretical value. In recent years, deep learning technologies, which are inspired by biological brain mechanisms, have made significant strides in the application of psychological or cognitive scientific research, particularly in the memorization and recognition of facial data. This paper investigates through experimental research how neural networks process and store facial expression data and associate these data with a range of psychological attributes produced by humans. Researchers utilized deep learning model VGG16, demonstrating that neural networks can learn and reproduce key features of facial data, thereby storing image memories. Moreover, the experimental results reveal the potential of deep learning models in understanding human emotions and cognitive processes and establish a manifold visualization interpretation of cognitive products or psychological attributes from a non-Euclidean space perspective, offering new insights into enhancing the explainability of AI. This study not only advances the application of AI technology in the field of psychology but also provides a new psychological theoretical understanding the information processing of the AI. The code is available in here: https://github.com/NKUShaw/Psychoinformatics.
Read more4/30/2024
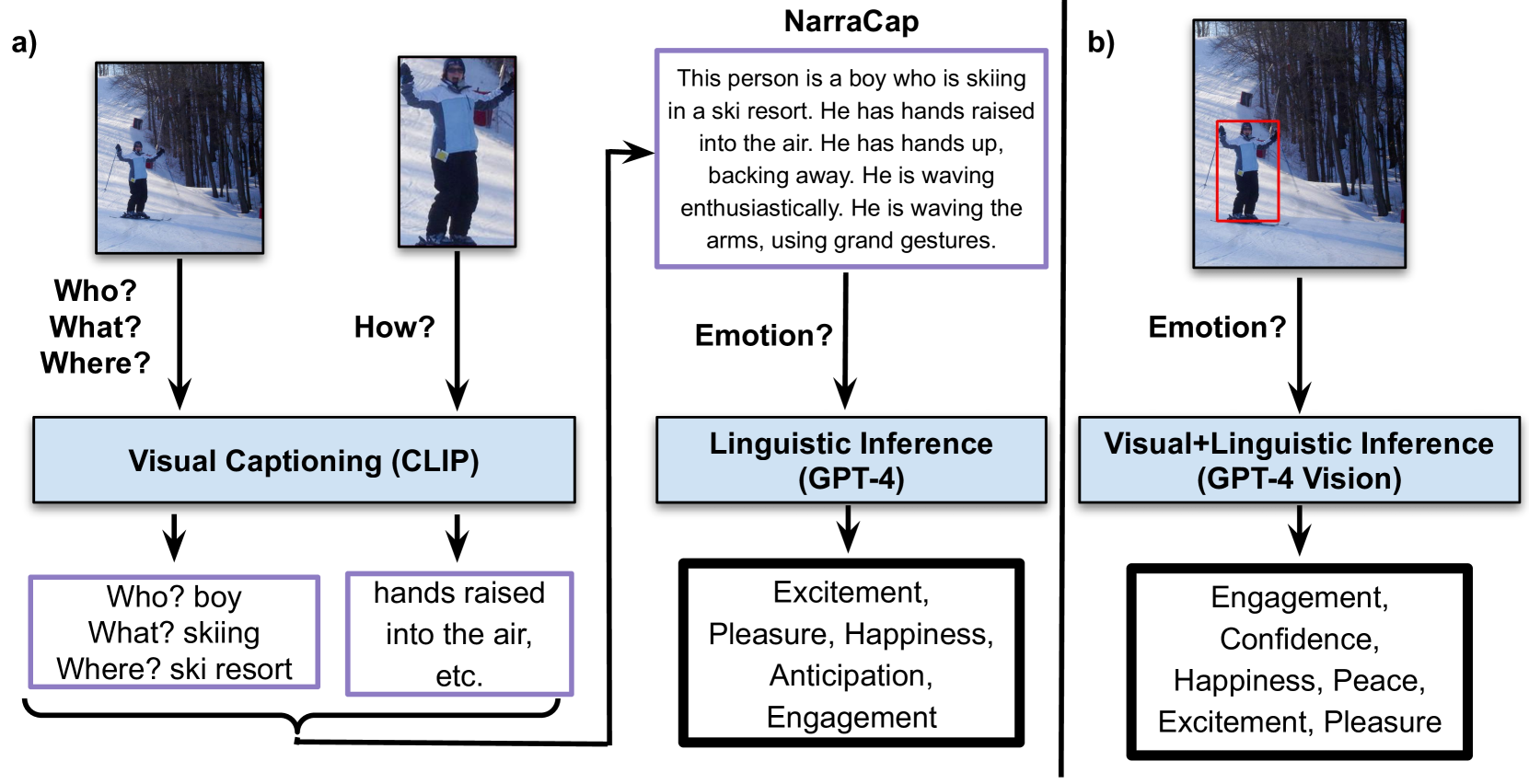
0
Contextual Emotion Recognition using Large Vision Language Models
Yasaman Etesam, Ozge Nilay Yalc{c}{i}n, Chuxuan Zhang, Angelica Lim
How does the person in the bounding box feel? Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
Read more5/16/2024