Contextual Emotion Recognition using Large Vision Language Models
2405.08992
0
0
Abstract
How does the person in the bounding box feel? Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
Create account to get full access
Overview
- This paper explores the use of large vision-language models (VLLMs) for contextual emotion recognition, which aims to understand the emotional state of a person based on their visual and textual cues.
- The researchers investigate how VLLMs, which are trained on vast amounts of multimodal data, can provide better context and understanding for emotion recognition compared to traditional unimodal approaches.
- The paper evaluates the performance of various VLLMs on several emotion recognition benchmarks and compares them to state-of-the-art text-only and image-only models.
Plain English Explanation
Emotions are complex and can be influenced by the context around us - the things we see and the words we hear. This paper examines how advanced AI models called vision-language models can be used to better understand human emotions by considering both visual and textual cues.
These vision-language models are trained on huge datasets that combine images and text, giving them a more holistic understanding of the world. The researchers wanted to see if these models could provide richer insights into a person's emotional state compared to approaches that only look at text or images alone.
They tested the performance of different vision-language models on standard emotion recognition benchmarks, which are datasets designed to evaluate how well AI systems can identify emotions. The results showed that the vision-language models outperformed text-only and image-only models, suggesting they are better able to capture the nuanced, contextual factors that shape human emotions.
This work connects to broader efforts to model emotions using large language models and leverage vision-language AI for fine-grained emotion detection. The findings indicate that considering both visual and textual information can lead to more accurate and insightful emotion recognition, which could have applications in areas like robot explanation, irony detection, and beyond.
Technical Explanation
The key contributions of this paper are:
- Evaluating the performance of various state-of-the-art vision-language models (VLLMs) on several emotion recognition benchmarks, including EMOTIC, EMOJIPEDIA, and TOEFL.
- Comparing the results of the VLLMs to text-only and image-only models to assess the benefit of the multimodal approach.
- Analyzing the strengths and limitations of VLLMs for contextual emotion recognition and identifying areas for future improvement.
The researchers experimented with models like ViLBERT, CLIP, and Unified-VLP, which are examples of large VLLMs trained on vast datasets that combine visual and textual information. They fine-tuned these models on the emotion recognition datasets and measured their performance on tasks like classifying the dominant emotion in an image-text pair.
The results showed that the VLLMs consistently outperformed text-only and image-only models, demonstrating the value of the multimodal approach for capturing the contextual cues that shape emotional experiences. The VLLMs were particularly adept at distinguishing more subtle or ambiguous emotions that may be difficult to detect from a single modality.
However, the paper also notes some limitations of the current VLLMs, such as their sensitivity to dataset biases and their tendency to struggle with rare or complex emotional states. The authors suggest that further research is needed to enhance the robustness and generalization capabilities of these models for real-world emotion recognition tasks.
Critical Analysis
The paper presents a compelling case for the use of vision-language models in contextual emotion recognition, but it also acknowledges several important caveats and areas for further exploration.
One key limitation is the reliance on curated benchmark datasets, which may not fully reflect the diversity and nuance of real-world emotional experiences. The authors note that the models could be biased towards the specific characteristics of the training data, and may struggle to generalize to more naturalistic or unconstrained scenarios.
Additionally, while the VLLMs outperformed unimodal approaches, the paper does not provide a deep analysis of the specific mechanisms by which the multimodal representations lead to improved emotion recognition. A more detailed investigation of the model's internal workings and the types of contextual cues it leverages could yield valuable insights.
Further research is also needed to understand the robustness of these models to noisy, ambiguous, or incomplete input data, as well as their ability to handle complex emotional states that may not neatly fit into predefined categories. Exploring ways to enhance the emotion recognition capabilities of large language models could also be a fruitful avenue for future work.
Overall, the paper makes a strong case for the potential of vision-language models in emotion recognition, but also highlights the need for continued research and development to address the limitations and unlock the full potential of this approach.
Conclusion
This paper demonstrates the benefits of using large vision-language models for contextual emotion recognition, where the combination of visual and textual information can provide richer insights into a person's emotional state compared to traditional unimodal approaches.
The results show that VLLMs outperform text-only and image-only models on several emotion recognition benchmarks, suggesting they are better able to capture the nuanced, contextual factors that shape human emotions. This work builds on efforts to leverage large language models for fine-grained emotion detection and enhance robot explanation capabilities through vision-language integration.
While the paper highlights the promise of VLLMs for emotion recognition, it also identifies key limitations and areas for further research, such as the need to address dataset biases, improve robustness to noisy or ambiguous inputs, and better understand the internal mechanisms driving the models' performance. Continued advancements in this area could lead to more accurate and contextually-aware emotion recognition systems with a wide range of applications, from irony detection to ethical considerations in large language model development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

VLLMs Provide Better Context for Emotion Understanding Through Common Sense Reasoning
Alexandros Xenos, Niki Maria Foteinopoulou, Ioanna Ntinou, Ioannis Patras, Georgios Tzimiropoulos
0
0
Recognising emotions in context involves identifying the apparent emotions of an individual, taking into account contextual cues from the surrounding scene. Previous approaches to this task have involved the design of explicit scene-encoding architectures or the incorporation of external scene-related information, such as captions. However, these methods often utilise limited contextual information or rely on intricate training pipelines. In this work, we leverage the groundbreaking capabilities of Vision-and-Large-Language Models (VLLMs) to enhance in-context emotion classification without introducing complexity to the training process in a two-stage approach. In the first stage, we propose prompting VLLMs to generate descriptions in natural language of the subject's apparent emotion relative to the visual context. In the second stage, the descriptions are used as contextual information and, along with the image input, are used to train a transformer-based architecture that fuses text and visual features before the final classification task. Our experimental results show that the text and image features have complementary information, and our fused architecture significantly outperforms the individual modalities without any complex training methods. We evaluate our approach on three different datasets, namely, EMOTIC, CAER-S, and BoLD, and achieve state-of-the-art or comparable accuracy across all datasets and metrics compared to much more complex approaches. The code will be made publicly available on github: https://github.com/NickyFot/EmoCommonSense.git
4/11/2024
⚙️
Emotional Theory of Mind: Bridging Fast Visual Processing with Slow Linguistic Reasoning
Yasaman Etesam, Ozge Nilay Yalc{c}{i}n, Chuxuan Zhang, Angelica Lim
0
0
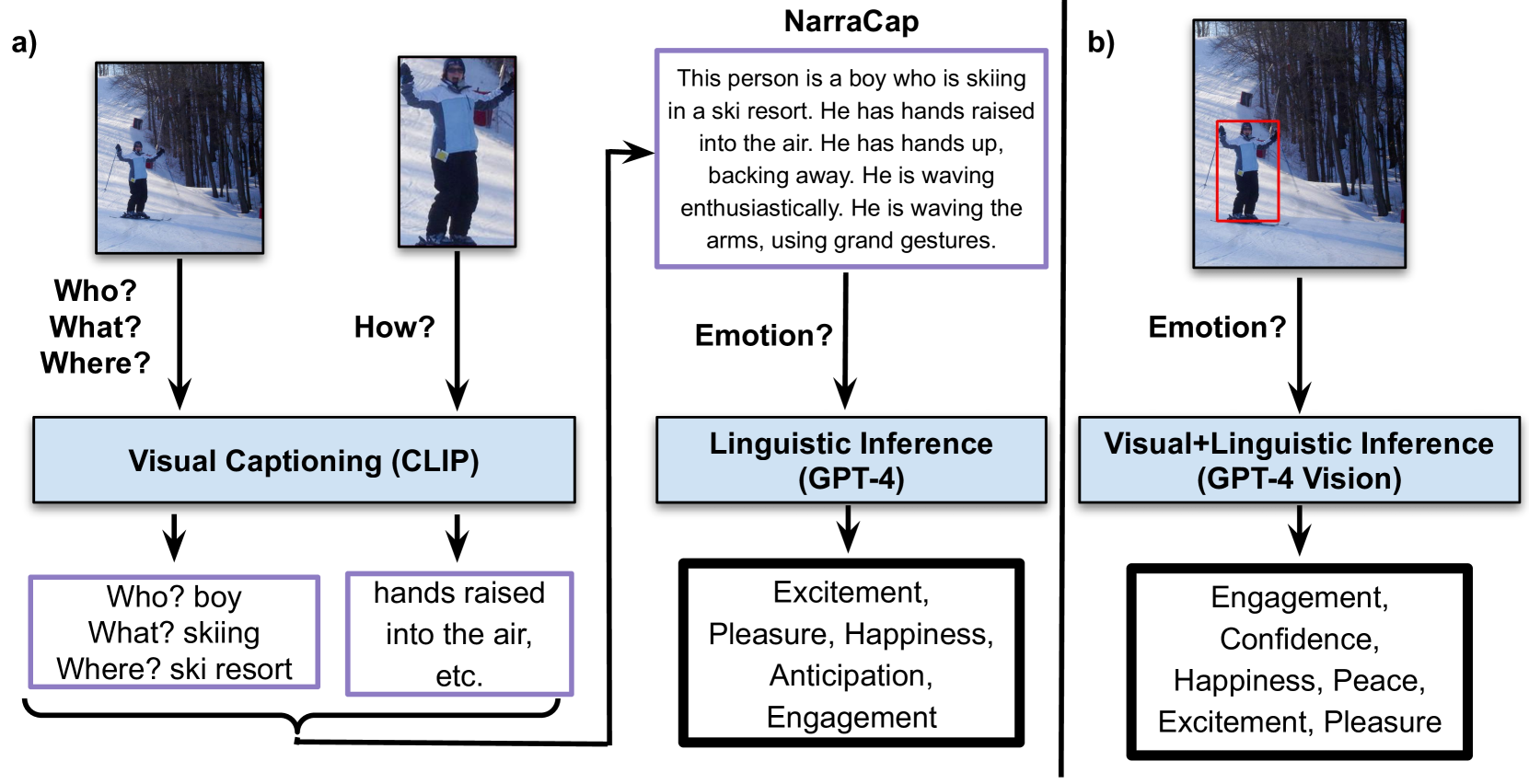
The emotional theory of mind problem requires facial expressions, body pose, contextual information and implicit commonsense knowledge to reason about the person's emotion and its causes, making it currently one of the most difficult problems in affective computing. In this work, we propose multiple methods to incorporate the emotional reasoning capabilities by constructing narrative captions relevant to emotion perception, that includes contextual and physical signal descriptors that focuses on Who, What, Where and How questions related to the image and emotions of the individual. We propose two distinct ways to construct these captions using zero-shot classifiers (CLIP) and fine-tuning visual-language models (LLaVA) over human generated descriptors. We further utilize these captions to guide the reasoning of language (GPT-4) and vision-language models (LLaVa, GPT-Vision). We evaluate the use of the resulting models in an image-to-language-to-emotion task. Our experiments showed that combining the Fast narrative descriptors and Slow reasoning of language models is a promising way to achieve emotional theory of mind.
6/18/2024
💬
Modeling Emotions and Ethics with Large Language Models
Edward Y. Chang
0
0
This paper explores the integration of human-like emotions and ethical considerations into Large Language Models (LLMs). We first model eight fundamental human emotions, presented as opposing pairs, and employ collaborative LLMs to reinterpret and express these emotions across a spectrum of intensity. Our focus extends to embedding a latent ethical dimension within LLMs, guided by a novel self-supervised learning algorithm with human feedback (SSHF). This approach enables LLMs to perform self-evaluations and adjustments concerning ethical guidelines, enhancing their capability to generate content that is not only emotionally resonant but also ethically aligned. The methodologies and case studies presented herein illustrate the potential of LLMs to transcend mere text and image generation, venturing into the realms of empathetic interaction and principled decision-making, thereby setting a new precedent in the development of emotionally aware and ethically conscious AI systems.
4/23/2024
TEII: Think, Explain, Interact and Iterate with Large Language Models to Solve Cross-lingual Emotion Detection
Long Cheng, Qihao Shao, Christine Zhao, Sheng Bi, Gina-Anne Levow
0
0
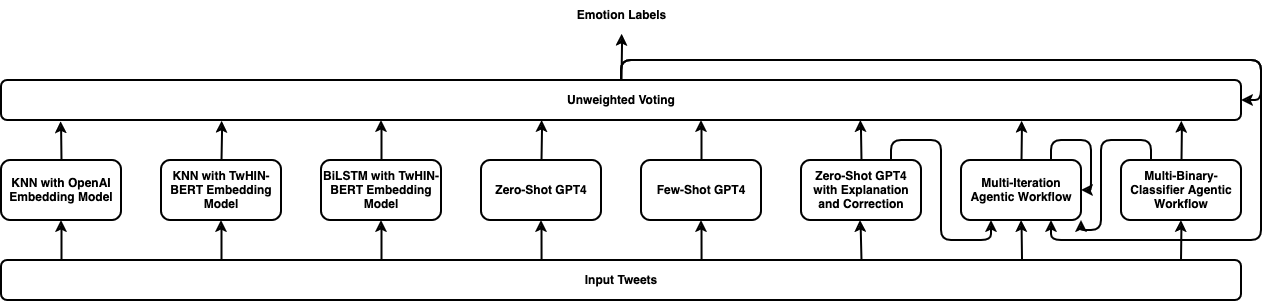
Cross-lingual emotion detection allows us to analyze global trends, public opinion, and social phenomena at scale. We participated in the Explainability of Cross-lingual Emotion Detection (EXALT) shared task, achieving an F1-score of 0.6046 on the evaluation set for the emotion detection sub-task. Our system outperformed the baseline by more than 0.16 F1-score absolute, and ranked second amongst competing systems. We conducted experiments using fine-tuning, zero-shot learning, and few-shot learning for Large Language Model (LLM)-based models as well as embedding-based BiLSTM and KNN for non-LLM-based techniques. Additionally, we introduced two novel methods: the Multi-Iteration Agentic Workflow and the Multi-Binary-Classifier Agentic Workflow. We found that LLM-based approaches provided good performance on multilingual emotion detection. Furthermore, ensembles combining all our experimented models yielded higher F1-scores than any single approach alone.
5/28/2024