AI Papers
Browse and discover the latest research papers on artificial intelligence, machine learning, and related fields.
🤯
Efficient LLM inference solution on Intel GPU
Hui Wu, Yi Gan, Feng Yuan, Jing Ma, Wei Zhu, Yutao Xu, Hong Zhu, Yuhua Zhu, Xiaoli Liu, Jinghui Gu, Peng Zhao
103
0
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency. In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.
6/26/2024
📊
New!From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data
Zheyang Xiong, Vasilis Papageorgiou, Kangwook Lee, Dimitris Papailiopoulos
71
0
Recent studies have shown that Large Language Models (LLMs) struggle to accurately retrieve information and maintain reasoning capabilities when processing long-context inputs. To address these limitations, we propose a finetuning approach utilizing a carefully designed synthetic dataset comprising numerical key-value retrieval tasks. Our experiments on models like GPT-3.5 Turbo and Mistral 7B demonstrate that finetuning LLMs on this dataset significantly improves LLMs' information retrieval and reasoning capabilities in longer-context settings. We present an analysis of the finetuned models, illustrating the transfer of skills from synthetic to real task evaluations (e.g., $10.5%$ improvement on $20$ documents MDQA at position $10$ for GPT-3.5 Turbo). We also find that finetuned LLMs' performance on general benchmarks remains almost constant while LLMs finetuned on other baseline long-context augmentation data can encourage hallucination (e.g., on TriviaQA, Mistral 7B finetuned on our synthetic data cause no performance drop while other baseline data can cause a drop that ranges from $2.33%$ to $6.19%$). Our study highlights the potential of finetuning on synthetic data for improving the performance of LLMs on longer-context tasks.
6/28/2024

Transparent Image Layer Diffusion using Latent Transparency
Lvmin Zhang, Maneesh Agrawala
43
0
We present LayerDiffuse, an approach enabling large-scale pretrained latent diffusion models to generate transparent images. The method allows generation of single transparent images or of multiple transparent layers. The method learns a latent transparency that encodes alpha channel transparency into the latent manifold of a pretrained latent diffusion model. It preserves the production-ready quality of the large diffusion model by regulating the added transparency as a latent offset with minimal changes to the original latent distribution of the pretrained model. In this way, any latent diffusion model can be converted into a transparent image generator by finetuning it with the adjusted latent space. We train the model with 1M transparent image layer pairs collected using a human-in-the-loop collection scheme. We show that latent transparency can be applied to different open source image generators, or be adapted to various conditional control systems to achieve applications like foreground/background-conditioned layer generation, joint layer generation, structural control of layer contents, etc. A user study finds that in most cases (97%) users prefer our natively generated transparent content over previous ad-hoc solutions such as generating and then matting. Users also report the quality of our generated transparent images is comparable to real commercial transparent assets like Adobe Stock.
6/26/2024

Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Chaojie Wang, Yanchen Deng, Zhiyi Lv, Zeng Liang, Jujie He, Shuicheng Yan, An Bo
32
0
Large Language Models (LLMs) have demonstrated impressive capability in many natural language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, by casting multi-step reasoning of LLMs as a heuristic search problem, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function for estimating expected future rewards, our Q* can effectively guide LLMs to select the most promising next reasoning step without fine-tuning LLMs for the current task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP demonstrate the superiority of our method, contributing to improving the reasoning performance of existing open-source LLMs.
6/28/2024
🤿
Deep Learning for Multi-Label Learning: A Comprehensive Survey
Adane Nega Tarekegn, Mohib Ullah, Faouzi Alaya Cheikh
23
0
Multi-label learning is a rapidly growing research area that aims to predict multiple labels from a single input data point. In the era of big data, tasks involving multi-label classification (MLC) or ranking present significant and intricate challenges, capturing considerable attention in diverse domains. Inherent difficulties in MLC include dealing with high-dimensional data, addressing label correlations, and handling partial labels, for which conventional methods prove ineffective. Recent years have witnessed a notable increase in adopting deep learning (DL) techniques to address these challenges more effectively in MLC. Notably, there is a burgeoning effort to harness the robust learning capabilities of DL for improved modelling of label dependencies and other challenges in MLC. However, it is noteworthy that comprehensive studies specifically dedicated to DL for multi-label learning are limited. Thus, this survey aims to thoroughly review recent progress in DL for multi-label learning, along with a summary of open research problems in MLC. The review consolidates existing research efforts in DL for MLC,including deep neural networks, transformers, autoencoders, and convolutional and recurrent architectures. Finally, the study presents a comparative analysis of the existing methods to provide insightful observations and stimulate future research directions in this domain.
6/27/2024
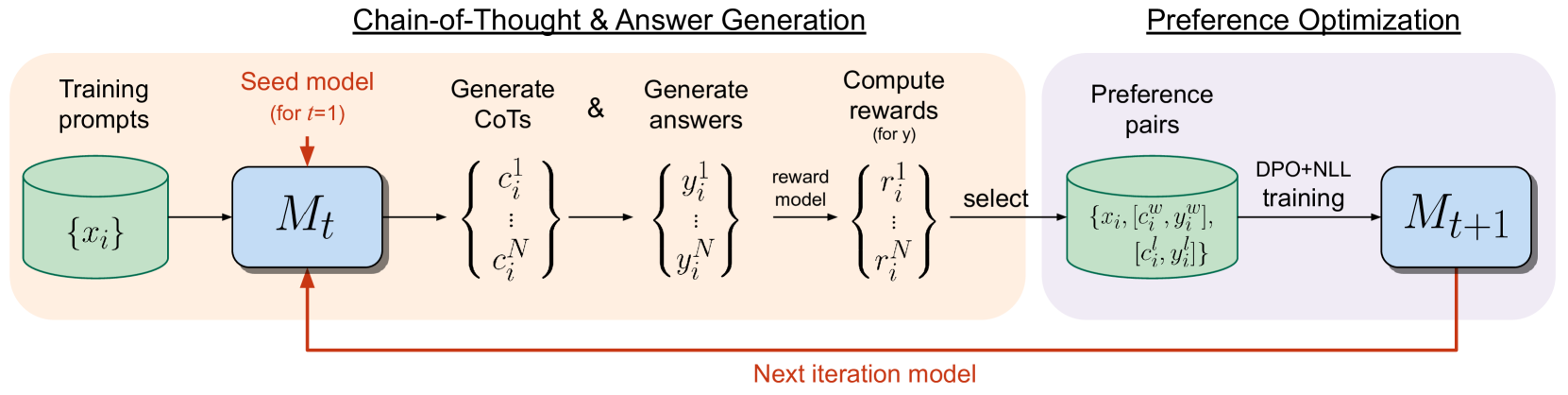
Iterative Reasoning Preference Optimization
Richard Yuanzhe Pang, Weizhe Yuan, Kyunghyun Cho, He He, Sainbayar Sukhbaatar, Jason Weston
19
0
Iterative preference optimization methods have recently been shown to perform well for general instruction tuning tasks, but typically make little improvement on reasoning tasks (Yuan et al., 2024, Chen et al., 2024). In this work we develop an iterative approach that optimizes the preference between competing generated Chain-of-Thought (CoT) candidates by optimizing for winning vs. losing reasoning steps that lead to the correct answer. We train using a modified DPO loss (Rafailov et al., 2023) with an additional negative log-likelihood term, which we find to be crucial. We show reasoning improves across repeated iterations of this scheme. While only relying on examples in the training set, our approach results in increasing accuracy on GSM8K, MATH, and ARC-Challenge for Llama-2-70B-Chat, outperforming other Llama-2-based models not relying on additionally sourced datasets. For example, we see a large improvement from 55.6% to 81.6% on GSM8K and an accuracy of 88.7% with majority voting out of 32 samples.
6/27/2024
🔗
New!Computational Life: How Well-formed, Self-replicating Programs Emerge from Simple Interaction
Blaise Aguera y Arcas, Jyrki Alakuijala, James Evans, Ben Laurie, Alexander Mordvintsev, Eyvind Niklasson, Ettore Randazzo, Luca Versari
11
0
The fields of Origin of Life and Artificial Life both question what life is and how it emerges from a distinct set of pre-life dynamics. One common feature of most substrates where life emerges is a marked shift in dynamics when self-replication appears. While there are some hypotheses regarding how self-replicators arose in nature, we know very little about the general dynamics, computational principles, and necessary conditions for self-replicators to emerge. This is especially true on computational substrates where interactions involve logical, mathematical, or programming rules. In this paper we take a step towards understanding how self-replicators arise by studying several computational substrates based on various simple programming languages and machine instruction sets. We show that when random, non self-replicating programs are placed in an environment lacking any explicit fitness landscape, self-replicators tend to arise. We demonstrate how this occurs due to random interactions and self-modification, and can happen with and without background random mutations. We also show how increasingly complex dynamics continue to emerge following the rise of self-replicators. Finally, we show a counterexample of a minimalistic programming language where self-replicators are possible, but so far have not been observed to arise.
6/28/2024
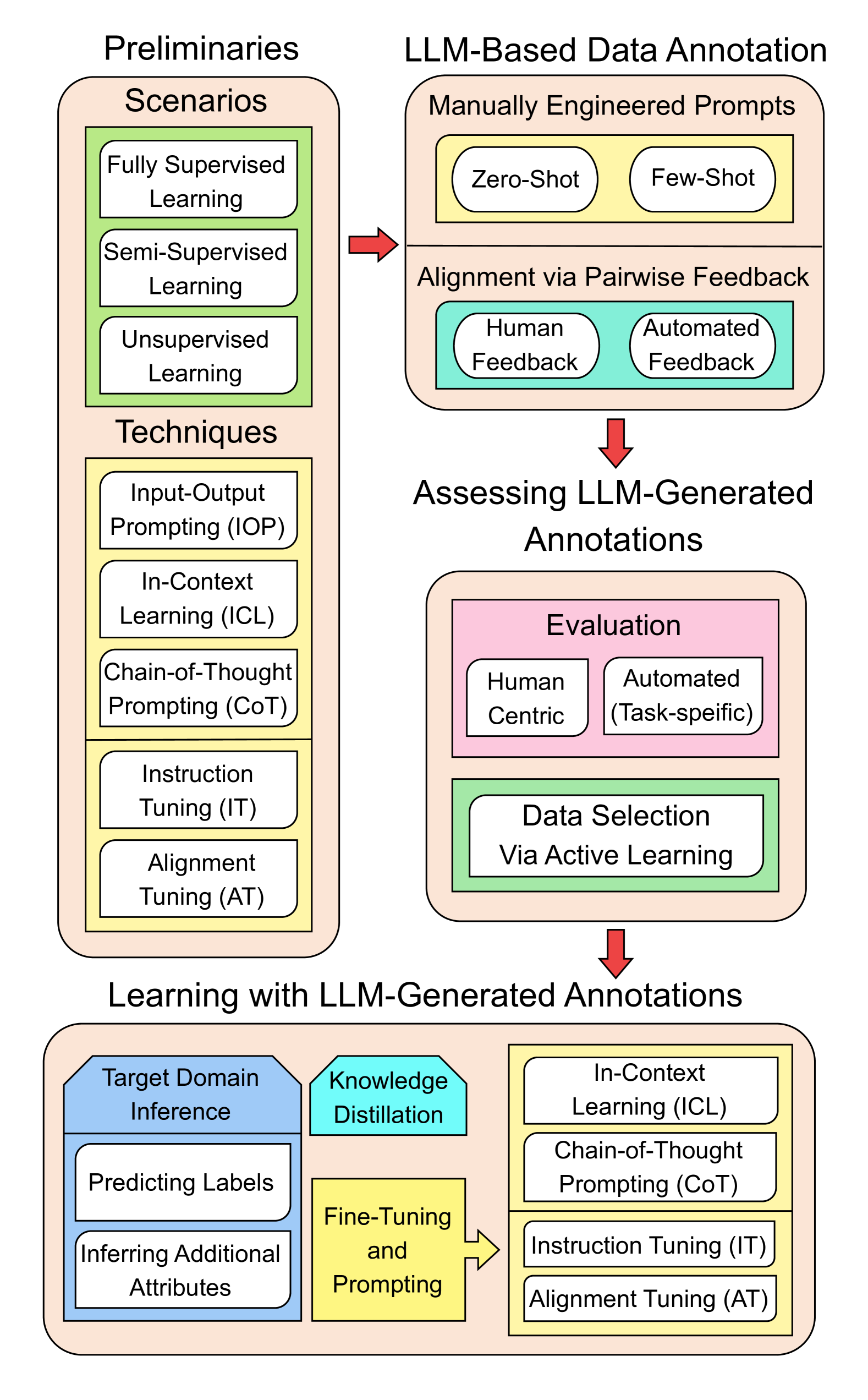
Large Language Models for Data Annotation: A Survey
Zhen Tan, Dawei Li, Song Wang, Alimohammad Beigi, Bohan Jiang, Amrita Bhattacharjee, Mansooreh Karami, Jundong Li, Lu Cheng, Huan Liu
2
6
Data annotation generally refers to the labeling or generating of raw data with relevant information, which could be used for improving the efficacy of machine learning models. The process, however, is labor-intensive and costly. The emergence of advanced Large Language Models (LLMs), exemplified by GPT-4, presents an unprecedented opportunity to automate the complicated process of data annotation. While existing surveys have extensively covered LLM architecture, training, and general applications, we uniquely focus on their specific utility for data annotation. This survey contributes to three core aspects: LLM-Based Annotation Generation, LLM-Generated Annotations Assessment, and LLM-Generated Annotations Utilization. Furthermore, this survey includes an in-depth taxonomy of data types that LLMs can annotate, a comprehensive review of learning strategies for models utilizing LLM-generated annotations, and a detailed discussion of the primary challenges and limitations associated with using LLMs for data annotation. Serving as a key guide, this survey aims to assist researchers and practitioners in exploring the potential of the latest LLMs for data annotation, thereby fostering future advancements in this critical field.
6/26/2024

Transcendence: Generative Models Can Outperform The Experts That Train Them
Edwin Zhang, Vincent Zhu, Naomi Saphra, Anat Kleiman, Benjamin L. Edelman, Milind Tambe, Sham M. Kakade, Eran Malach
4
0
Generative models are trained with the simple objective of imitating the conditional probability distribution induced by the data they are trained on. Therefore, when trained on data generated by humans, we may not expect the artificial model to outperform the humans on their original objectives. In this work, we study the phenomenon of transcendence: when a generative model achieves capabilities that surpass the abilities of the experts generating its data. We demonstrate transcendence by training an autoregressive transformer to play chess from game transcripts, and show that the trained model can sometimes achieve better performance than all players in the dataset. We theoretically prove that transcendence can be enabled by low-temperature sampling, and rigorously assess this claim experimentally. Finally, we discuss other sources of transcendence, laying the groundwork for future investigation of this phenomenon in a broader setting.
6/26/2024
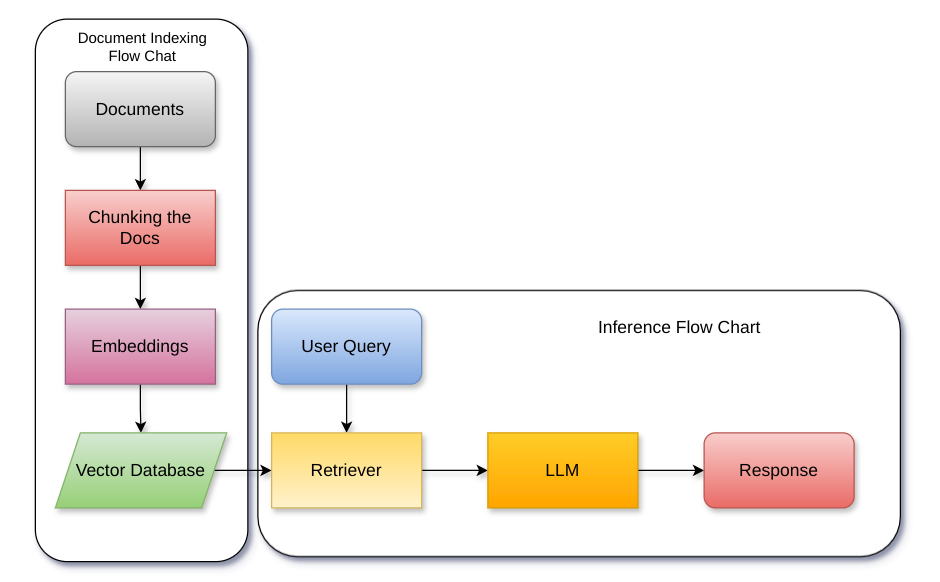
Context-augmented Retrieval: A Novel Framework for Fast Information Retrieval based Response Generation using Large Language Model
Sai Ganesh, Anupam Purwar, Gautam B
4
0
Generating high-quality answers consistently by providing contextual information embedded in the prompt passed to the Large Language Model (LLM) is dependent on the quality of information retrieval. As the corpus of contextual information grows, the answer/inference quality of Retrieval Augmented Generation (RAG) based Question Answering (QA) systems declines. This work solves this problem by combining classical text classification with the Large Language Model (LLM) to enable quick information retrieval from the vector store and ensure the relevancy of retrieved information. For the same, this work proposes a new approach Context Augmented retrieval (CAR), where partitioning of vector database by real-time classification of information flowing into the corpus is done. CAR demonstrates good quality answer generation along with significant reduction in information retrieval and answer generation time.
6/26/2024

Progress Towards Decoding Visual Imagery via fNIRS
Michel Adamic, Wellington Avelino, Anna Brandenberger, Bryan Chiang, Hunter Davis, Stephen Fay, Andrew Gregory, Aayush Gupta, Raphael Hotter, Grace Jiang, Fiona Leng, Stephen Polcyn, Thomas Ribeiro, Paul Scotti, Michelle Wang, Marley Xiong, Jonathan Xu
3
0
We demonstrate the possibility of reconstructing images from fNIRS brain activity and start building a prototype to match the required specs. By training an image reconstruction model on downsampled fMRI data, we discovered that cm-scale spatial resolution is sufficient for image generation. We obtained 71% retrieval accuracy with 1-cm resolution, compared to 93% on the full-resolution fMRI, and 20% with 2-cm resolution. With simulations and high-density tomography, we found that time-domain fNIRS can achieve 1-cm resolution, compared to 2-cm resolution for continuous-wave fNIRS. Lastly, we share designs for a prototype time-domain fNIRS device, consisting of a laser driver, a single photon detector, and a time-to-digital converter system.
6/26/2024
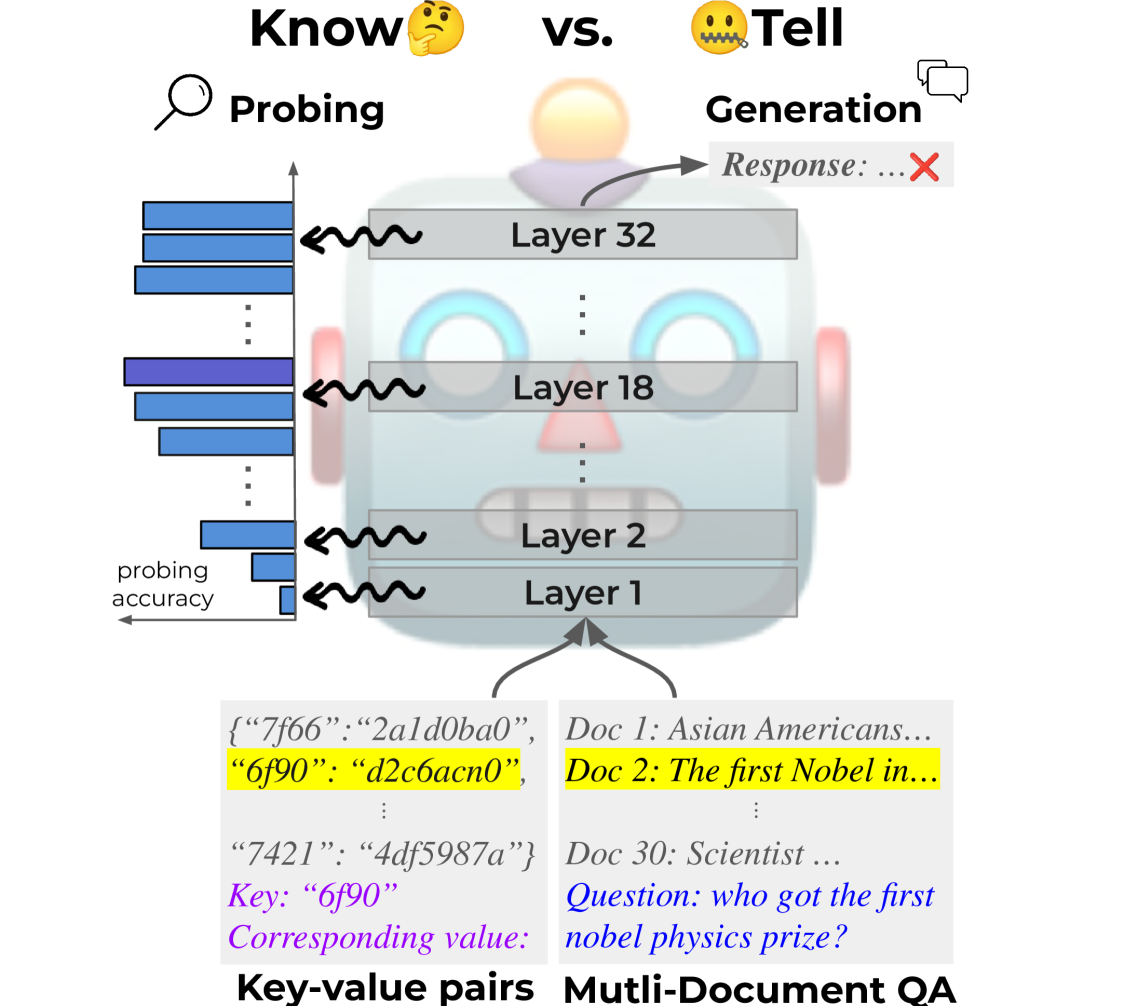
Insights into LLM Long-Context Failures: When Transformers Know but Don't Tell
Taiming Lu, Muhan Gao, Kuai Yu, Adam Byerly, Daniel Khashabi
3
0
Large Language Models (LLMs) exhibit positional bias, struggling to utilize information from the middle or end of long contexts. Our study explores LLMs' long-context reasoning by probing their hidden representations. We find that while LLMs encode the position of target information, they often fail to leverage this in generating accurate responses. This reveals a disconnect between information retrieval and utilization, a know but don't tell phenomenon. We further analyze the relationship between extraction time and final accuracy, offering insights into the underlying mechanics of transformer models.
6/24/2024

Generative AI Misuse: A Taxonomy of Tactics and Insights from Real-World Data
Nahema Marchal, Rachel Xu, Rasmi Elasmar, Iason Gabriel, Beth Goldberg, William Isaac
3
0
Generative, multimodal artificial intelligence (GenAI) offers transformative potential across industries, but its misuse poses significant risks. Prior research has shed light on the potential of advanced AI systems to be exploited for malicious purposes. However, we still lack a concrete understanding of how GenAI models are specifically exploited or abused in practice, including the tactics employed to inflict harm. In this paper, we present a taxonomy of GenAI misuse tactics, informed by existing academic literature and a qualitative analysis of approximately 200 observed incidents of misuse reported between January 2023 and March 2024. Through this analysis, we illuminate key and novel patterns in misuse during this time period, including potential motivations, strategies, and how attackers leverage and abuse system capabilities across modalities (e.g. image, text, audio, video) in the wild.
6/24/2024
💬
LMDX: Language Model-based Document Information Extraction and Localization
Vincent Perot, Kai Kang, Florian Luisier, Guolong Su, Xiaoyu Sun, Ramya Sree Boppana, Zilong Wang, Zifeng Wang, Jiaqi Mu, Hao Zhang, Chen-Yu Lee, Nan Hua
3
0
Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art and exhibiting emergent capabilities across various tasks. However, their application in extracting information from visually rich documents, which is at the core of many document processing workflows and involving the extraction of key entities from semi-structured documents, has not yet been successful. The main obstacles to adopting LLMs for this task include the absence of layout encoding within LLMs, which is critical for high quality extraction, and the lack of a grounding mechanism to localize the predicted entities within the document. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to reframe the document information extraction task for a LLM. LMDX enables extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. Finally, we apply LMDX to the PaLM 2-S and Gemini Pro LLMs and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
6/26/2024

Step-by-Step Diffusion: An Elementary Tutorial
Preetum Nakkiran, Arwen Bradley, Hattie Zhou, Madhu Advani
3
0
We present an accessible first course on diffusion models and flow matching for machine learning, aimed at a technical audience with no diffusion experience. We try to simplify the mathematical details as much as possible (sometimes heuristically), while retaining enough precision to derive correct algorithms.
6/26/2024
New!MAGIS: LLM-Based Multi-Agent Framework for GitHub Issue Resolution
Wei Tao, Yucheng Zhou, Yanlin Wang, Wenqiang Zhang, Hongyu Zhang, Yu Cheng
3
0
In software development, resolving the emergent issues within GitHub repositories is a complex challenge that involves not only the incorporation of new code but also the maintenance of existing code. Large Language Models (LLMs) have shown promise in code generation but face difficulties in resolving Github issues, particularly at the repository level. To overcome this challenge, we empirically study the reason why LLMs fail to resolve GitHub issues and analyze the major factors. Motivated by the empirical findings, we propose a novel LLM-based Multi-Agent framework for GitHub Issue reSolution, MAGIS, consisting of four agents customized for software evolution: Manager, Repository Custodian, Developer, and Quality Assurance Engineer agents. This framework leverages the collaboration of various agents in the planning and coding process to unlock the potential of LLMs to resolve GitHub issues. In experiments, we employ the SWE-bench benchmark to compare MAGIS with popular LLMs, including GPT-3.5, GPT-4, and Claude-2. MAGIS can resolve 13.94% GitHub issues, significantly outperforming the baselines. Specifically, MAGIS achieves an eight-fold increase in resolved ratio over the direct application of GPT-4, the advanced LLM.
6/28/2024
📈
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
Kenneth Li, Aspen K. Hopkins, David Bau, Fernanda Vi'egas, Hanspeter Pfister, Martin Wattenberg
3
0
Language models show a surprising range of capabilities, but the source of their apparent competence is unclear. Do these networks just memorize a collection of surface statistics, or do they rely on internal representations of the process that generates the sequences they see? We investigate this question by applying a variant of the GPT model to the task of predicting legal moves in a simple board game, Othello. Although the network has no a priori knowledge of the game or its rules, we uncover evidence of an emergent nonlinear internal representation of the board state. Interventional experiments indicate this representation can be used to control the output of the network and create latent saliency maps that can help explain predictions in human terms.
6/27/2024
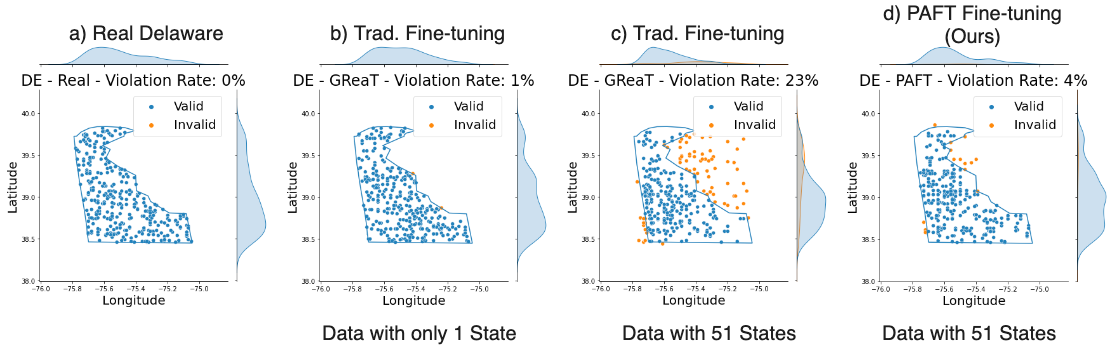
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Shengzhe Xu, Cho-Ting Lee, Mandar Sharma, Raquib Bin Yousuf, Nikhil Muralidhar, Naren Ramakrishnan
2
0
Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
6/24/2024
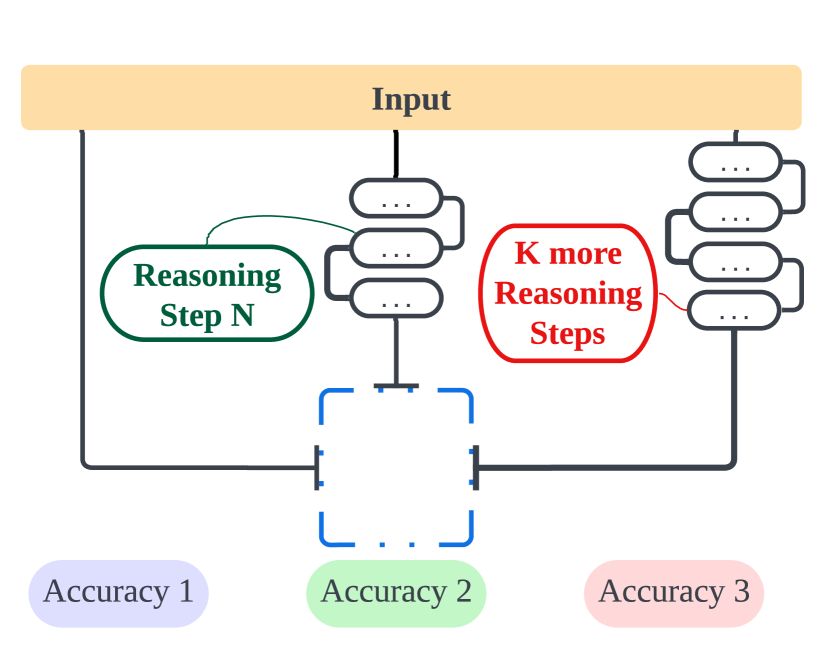
The Impact of Reasoning Step Length on Large Language Models
Mingyu Jin, Qinkai Yu, Dong Shu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, Mengnan Du
2
0
Chain of Thought (CoT) is significant in improving the reasoning abilities of large language models (LLMs). However, the correlation between the effectiveness of CoT and the length of reasoning steps in prompts remains largely unknown. To shed light on this, we have conducted several empirical experiments to explore the relations. Specifically, we design experiments that expand and compress the rationale reasoning steps within CoT demonstrations while keeping all other factors constant. We have the following key findings. First, the results indicate that lengthening the reasoning steps in prompts, even without adding new information into the prompt, considerably enhances LLMs' reasoning abilities across multiple datasets. Alternatively, shortening the reasoning steps, even while preserving the key information, significantly diminishes the reasoning abilities of models. This finding highlights the importance of the number of steps in CoT prompts and provides practical guidance to make better use of LLMs' potential in complex problem-solving scenarios. Second, we also investigated the relationship between the performance of CoT and the rationales used in demonstrations. Surprisingly, the result shows that even incorrect rationales can yield favorable outcomes if they maintain the requisite length of inference. Third, we observed that the advantages of increasing reasoning steps are task-dependent: simpler tasks require fewer steps, whereas complex tasks gain significantly from longer inference sequences. The code is available at https://github.com/MingyuJ666/The-Impact-of-Reasoning-Step-Length-on-Large-Language-Models
6/26/2024
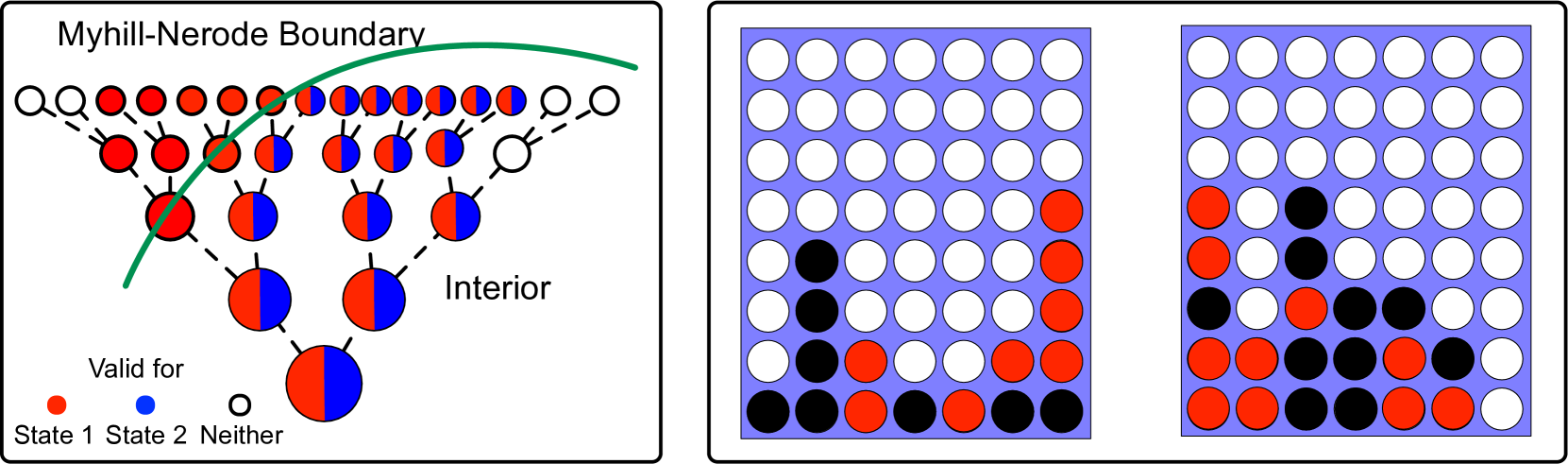
Evaluating the World Model Implicit in a Generative Model
Keyon Vafa, Justin Y. Chen, Jon Kleinberg, Sendhil Mullainathan, Ashesh Rambachan
2
0
Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead it to fail badly. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
6/26/2024