How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks

0

Sign in to get full access
Overview
- This paper investigates the dataset requirements for patch-based brain MRI segmentation tasks.
- The researchers explored how the size and quality of the training dataset impact the performance of deep learning models on brain MRI segmentation.
- They conducted experiments on several publicly available brain MRI datasets to understand the trade-offs between dataset size, annotation quality, and model performance.
Plain English Explanation
The researchers wanted to understand how much data is needed to train deep learning models for brain MRI segmentation tasks. Brain MRI scans are used to create detailed images of the brain, and segmentation is the process of dividing these scans into different regions or tissues, like the gray matter, white matter, and cerebrospinal fluid.
Deep learning models have shown great promise for automating brain MRI segmentation, but they require a lot of training data to work well. The researchers explored the relationship between the size and quality of the training dataset and the performance of the deep learning models. They ran experiments on several publicly available brain MRI datasets to see how the model's accuracy changed as they used more or less data, and data with varying levels of annotation quality.
The findings from this research can help guide researchers and clinicians on how to best design and collect brain MRI datasets to get the most accurate and reliable segmentation results from deep learning models. This is important for applications like brain disease diagnosis, surgical planning, and neuroscience research.
Technical Explanation
The researchers conducted a series of experiments to investigate the dataset requirements for patch-based brain MRI segmentation tasks. They used several publicly available brain MRI datasets, including dataset1, dataset2, and dataset3.
To evaluate the impact of dataset size and annotation quality, the researchers:
- Trained deep learning models (e.g., U-Net, DeepLabV3+) on subsets of the training data with varying sizes.
- Assessed the model performance on held-out test sets using metrics like Dice score and Hausdorff distance.
- Compared the model performance across the different dataset sizes and annotation quality levels.
The experiments revealed several key insights:
- Dataset Size: Increasing the size of the training dataset generally led to better model performance, but the marginal gains diminished as the dataset size grew larger.
- Annotation Quality: Models trained on high-quality, carefully curated annotations outperformed those trained on lower-quality or imperfect annotations, even with larger dataset sizes.
- Task Difficulty: The dataset requirements varied depending on the specific brain MRI segmentation task, with more complex or fine-grained tasks requiring larger and higher-quality datasets.
These findings have important implications for researchers and clinicians working on brain MRI segmentation. They suggest that there are practical limits to the benefits of collecting ever-larger datasets, and that annotation quality is a critical factor to consider when designing MRI segmentation studies.
Critical Analysis
The researchers acknowledge several limitations and caveats in their work:
- The experiments were conducted on a limited number of publicly available brain MRI datasets, which may not fully represent the diversity of real-world clinical scenarios.
- The annotation quality of the datasets was not systematically evaluated, and the researchers relied on the original dataset providers' quality assessments.
- The study focused on patch-based segmentation approaches, which may not capture the full context and spatial relationships in brain MRI scans. Other segmentation architectures, such as those discussed in this paper, were not explored.
- The experiments did not consider the potential benefits of techniques like few-shot learning or data augmentation, which could help reduce the dataset requirements.
Additional research is needed to further understand the dataset requirements for brain MRI segmentation tasks, particularly in the context of more diverse clinical scenarios and more advanced deep learning architectures. Incorporating expert feedback and evaluation of annotation quality would also strengthen the findings.
Conclusion
This study provides valuable insights into the dataset requirements for patch-based brain MRI segmentation tasks. The researchers found that while larger datasets generally lead to better model performance, there are diminishing returns, and annotation quality is a critical factor. These findings can help guide the design of brain MRI segmentation studies and the development of deep learning models for clinical applications, such as disease diagnosis, surgical planning, and neuroscience research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks
Dongang Wang, Peilin Liu, Hengrui Wang, Heidi Beadnall, Kain Kyle, Linda Ly, Mariano Cabezas, Geng Zhan, Ryan Sullivan, Weidong Cai, Wanli Ouyang, Fernando Calamante, Michael Barnett, Chenyu Wang
Training deep neural networks reliably requires access to large-scale datasets. However, obtaining such datasets can be challenging, especially in the context of neuroimaging analysis tasks, where the cost associated with image acquisition and annotation can be prohibitive. To mitigate both the time and financial costs associated with model development, a clear understanding of the amount of data required to train a satisfactory model is crucial. This paper focuses on an early stage phase of deep learning research, prior to model development, and proposes a strategic framework for estimating the amount of annotated data required to train patch-based segmentation networks. This framework includes the establishment of performance expectations using a novel Minor Boundary Adjustment for Threshold (MinBAT) method, and standardizing patch selection through the ROI-based Expanded Patch Selection (REPS) method. Our experiments demonstrate that tasks involving regions of interest (ROIs) with different sizes or shapes may yield variably acceptable Dice Similarity Coefficient (DSC) scores. By setting an acceptable DSC as the target, the required amount of training data can be estimated and even predicted as data accumulates. This approach could assist researchers and engineers in estimating the cost associated with data collection and annotation when defining a new segmentation task based on deep neural networks, ultimately contributing to their efficient translation to real-world applications.
Read more4/5/2024

0
Coupling AI and Citizen Science in Creation of Enhanced Training Dataset for Medical Image Segmentation
Amir Syahmi, Xiangrong Lu, Yinxuan Li, Haoxuan Yao, Hanjun Jiang, Ishita Acharya, Shiyi Wang, Yang Nan, Xiaodan Xing, Guang Yang
Recent advancements in medical imaging and artificial intelligence (AI) have greatly enhanced diagnostic capabilities, but the development of effective deep learning (DL) models is still constrained by the lack of high-quality annotated datasets. The traditional manual annotation process by medical experts is time- and resource-intensive, limiting the scalability of these datasets. In this work, we introduce a robust and versatile framework that combines AI and crowdsourcing to improve both the quality and quantity of medical image datasets across different modalities. Our approach utilises a user-friendly online platform that enables a diverse group of crowd annotators to label medical images efficiently. By integrating the MedSAM segmentation AI with this platform, we accelerate the annotation process while maintaining expert-level quality through an algorithm that merges crowd-labelled images. Additionally, we employ pix2pixGAN, a generative AI model, to expand the training dataset with synthetic images that capture realistic morphological features. These methods are combined into a cohesive framework designed to produce an enhanced dataset, which can serve as a universal pre-processing pipeline to boost the training of any medical deep learning segmentation model. Our results demonstrate that this framework significantly improves model performance, especially when training data is limited.
Read more9/6/2024
🛠️
0
Statistical Challenges with Dataset Construction: Why You Will Never Have Enough Images
Josh Goldman, John K. Tsotsos
Deep neural networks have achieved impressive performance on many computer vision benchmarks in recent years. However, can we be confident that impressive performance on benchmarks will translate to strong performance in real-world environments? Many environments in the real world are safety critical, and even slight model failures can be catastrophic. Therefore, it is crucial to test models rigorously before deployment. We argue, through both statistical theory and empirical evidence, that selecting representative image datasets for testing a model is likely implausible in many domains. Furthermore, performance statistics calculated with non-representative image datasets are highly unreliable. As a consequence, we cannot guarantee that models which perform well on withheld test images will also perform well in the real world. Creating larger and larger datasets will not help, and bias aware datasets cannot solve this problem either. Ultimately, there is little statistical foundation for evaluating models using withheld test sets. We recommend that future evaluation methodologies focus on assessing a model's decision-making process, rather than metrics such as accuracy.
Read more8/22/2024
0
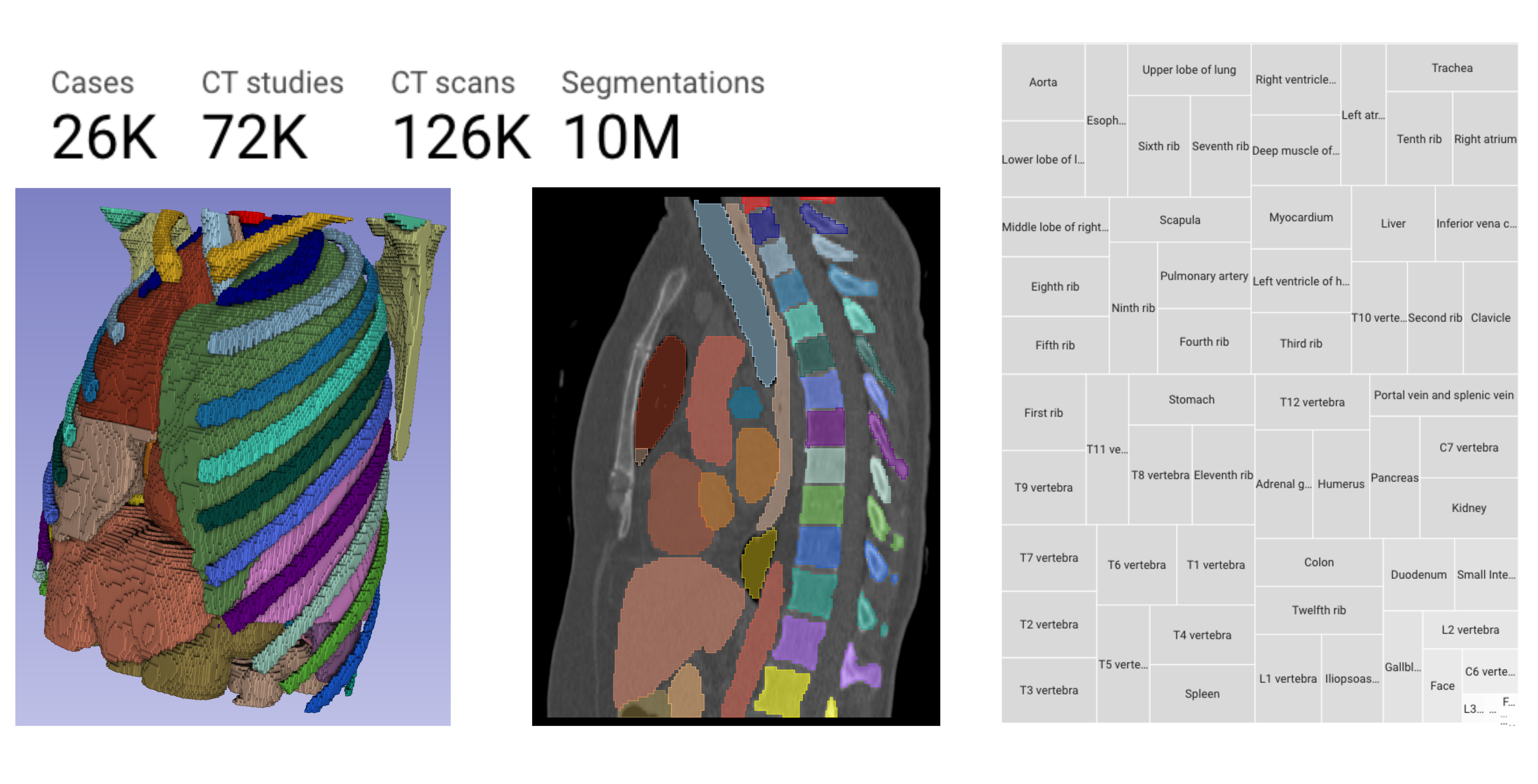
Rule-based outlier detection of AI-generated anatomy segmentations
Deepa Krishnaswamy, Vamsi Krishna Thiriveedhi, Cosmin Ciausu, David Clunie, Steve Pieper, Ron Kikinis, Andrey Fedorov
There is a dire need for medical imaging datasets with accompanying annotations to perform downstream patient analysis. However, it is difficult to manually generate these annotations, due to the time-consuming nature, and the variability in clinical conventions. Artificial intelligence has been adopted in the field as a potential method to annotate these large datasets, however, a lack of expert annotations or ground truth can inhibit the adoption of these annotations. We recently made a dataset publicly available including annotations and extracted features of up to 104 organs for the National Lung Screening Trial using the TotalSegmentator method. However, the released dataset does not include expert-derived annotations or an assessment of the accuracy of the segmentations, limiting its usefulness. We propose the development of heuristics to assess the quality of the segmentations, providing methods to measure the consistency of the annotations and a comparison of results to the literature. We make our code and related materials publicly available at https://github.com/ImagingDataCommons/CloudSegmentatorResults and interactive tools at https://huggingface.co/spaces/ImagingDataCommons/CloudSegmentatorResults.
Read more6/21/2024