One model to use them all: Training a segmentation model with complementary datasets

0
Sign in to get full access
Overview
- This paper explores training a single segmentation model using multiple complementary datasets to improve its performance on diverse medical imaging tasks.
- The authors investigate different strategies for combining datasets and show that a unified model can outperform specialized models trained on individual datasets.
- The research has implications for developing more robust and generalizable medical image analysis tools, which could benefit MedCLIP-SAM, cross-modal tumor segmentation, and other medical imaging applications.
Plain English Explanation
The paper describes a way to train a single machine learning model that can perform well on different medical imaging tasks, like detecting tumors or measuring organ sizes. Typically, researchers would train a separate model for each task using data specific to that task.
However, the authors of this paper tried something different. They trained one model using data from multiple medical imaging datasets, even if the datasets were focused on different tasks. The key insight is that by exposing the model to diverse data, it can learn general features and patterns that make it good at a variety of tasks, rather than being specialized for just one.
The authors tested different strategies for combining the datasets during training, and found that a unified model trained this way outperformed models trained on individual datasets. This suggests that a single, versatile model could be more useful than having many specialized models for different medical imaging applications, like what's done in synthetic data for robust stroke segmentation or determining dataset size for medical AI.
Technical Explanation
The paper proposes a method for training a single segmentation model using multiple complementary medical imaging datasets. The key contributions are:
- Investigating different data combination strategies, including dataset mixing, dataset concatenation, and gradient decomposition.
- Showing that a unified model trained this way can outperform specialized models trained on individual datasets.
- Demonstrating the versatility of the unified model on a variety of medical imaging tasks, including brain lesion detection and organ segmentation.
The authors experimented with several backbone architectures, including U-Net and Swin Transformer, and found the unified model approach improved performance across the board. The results suggest this method could lead to more generalizable and robust medical imaging models compared to the current practice of training specialized models for each task.
Critical Analysis
The paper provides a compelling approach for developing more versatile medical image analysis tools. By training a single model on diverse datasets, the authors demonstrate the potential to create models that can handle a wide range of tasks without sacrificing performance.
One limitation mentioned is the need for careful dataset selection and curation to ensure the complementary datasets truly capture the variety of medical imaging data. Datasets with significant domain shifts or conflicting annotations may hinder the unified model's ability to learn generalizable features.
Additionally, the paper does not explore the impact of dataset size on the unified model's performance. It would be interesting to see how the approach scales as more data becomes available, and whether there are diminishing returns as the model is exposed to an increasingly large and diverse set of training samples.
Overall, this research represents an important step towards more flexible and efficient medical image analysis systems. The findings could inspire further work on cross-modal tumor segmentation and other areas where a single, adaptable model could provide significant benefits.
Conclusion
This paper introduces a novel approach for training a single segmentation model capable of performing well on a variety of medical imaging tasks. By combining complementary datasets during training, the authors demonstrate that a unified model can outperform specialized models trained on individual datasets.
The findings suggest this method could lead to more robust and generalizable medical imaging tools, which could have a significant impact on MedCLIP-SAM and other applications that rely on accurate medical image analysis. As the field of medical AI continues to evolve, techniques like the one described in this paper will likely play an important role in developing practical, versatile solutions that can benefit clinicians and patients alike.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
One model to use them all: Training a segmentation model with complementary datasets
Alexander C. Jenke, Sebastian Bodenstedt, Fiona R. Kolbinger, Marius Distler, Jurgen Weitz, Stefanie Speidel
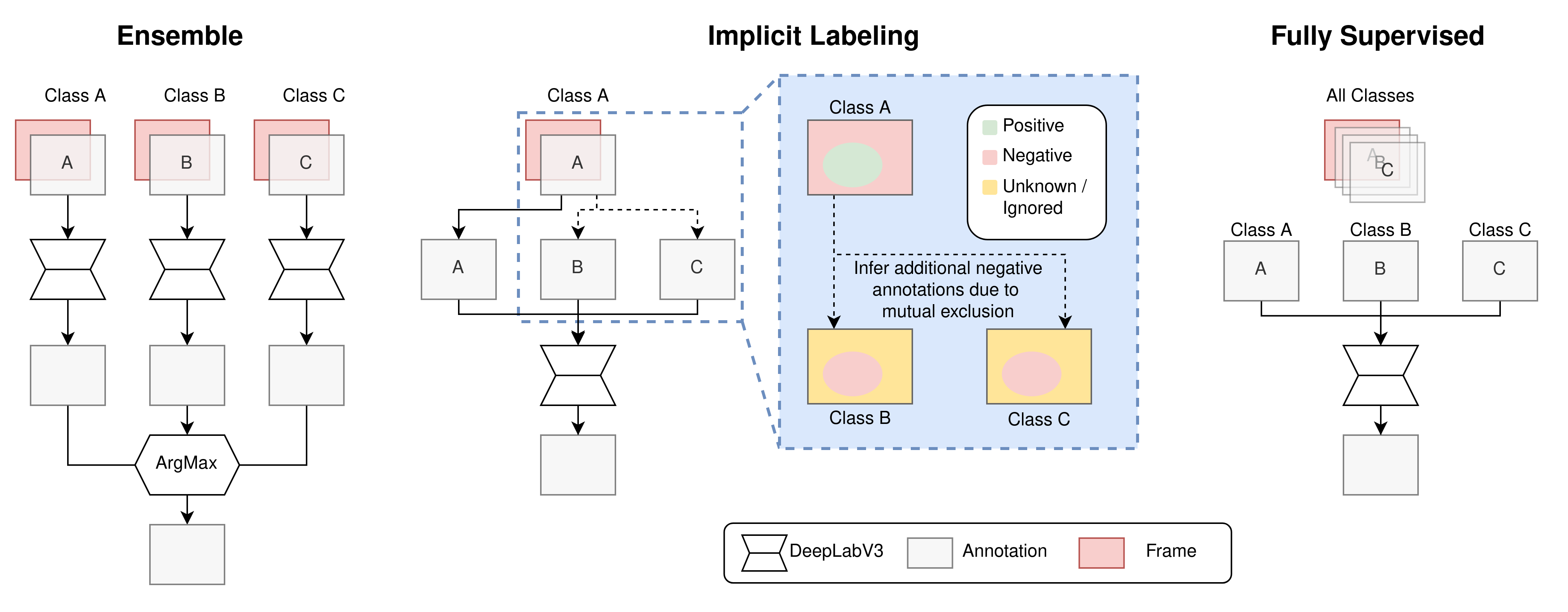
Understanding a surgical scene is crucial for computer-assisted surgery systems to provide any intelligent assistance functionality. One way of achieving this scene understanding is via scene segmentation, where every pixel of a frame is classified and therefore identifies the visible structures and tissues. Progress on fully segmenting surgical scenes has been made using machine learning. However, such models require large amounts of annotated training data, containing examples of all relevant object classes. Such fully annotated datasets are hard to create, as every pixel in a frame needs to be annotated by medical experts and, therefore, are rarely available. In this work, we propose a method to combine multiple partially annotated datasets, which provide complementary annotations, into one model, enabling better scene segmentation and the use of multiple readily available datasets. Our method aims to combine available data with complementary labels by leveraging mutual exclusive properties to maximize information. Specifically, we propose to use positive annotations of other classes as negative samples and to exclude background pixels of binary annotations, as we cannot tell if they contain a class not annotated but predicted by the model. We evaluate our method by training a DeepLabV3 on the publicly available Dresden Surgical Anatomy Dataset, which provides multiple subsets of binary segmented anatomical structures. Our approach successfully combines 6 classes into one model, increasing the overall Dice Score by 4.4% compared to an ensemble of models trained on the classes individually. By including information on multiple classes, we were able to reduce confusion between stomach and colon by 24%. Our results demonstrate the feasibility of training a model on multiple datasets. This paves the way for future work further alleviating the need for one large, fully segmented datasets.
Read more4/8/2024

0
Coupling AI and Citizen Science in Creation of Enhanced Training Dataset for Medical Image Segmentation
Amir Syahmi, Xiangrong Lu, Yinxuan Li, Haoxuan Yao, Hanjun Jiang, Ishita Acharya, Shiyi Wang, Yang Nan, Xiaodan Xing, Guang Yang
Recent advancements in medical imaging and artificial intelligence (AI) have greatly enhanced diagnostic capabilities, but the development of effective deep learning (DL) models is still constrained by the lack of high-quality annotated datasets. The traditional manual annotation process by medical experts is time- and resource-intensive, limiting the scalability of these datasets. In this work, we introduce a robust and versatile framework that combines AI and crowdsourcing to improve both the quality and quantity of medical image datasets across different modalities. Our approach utilises a user-friendly online platform that enables a diverse group of crowd annotators to label medical images efficiently. By integrating the MedSAM segmentation AI with this platform, we accelerate the annotation process while maintaining expert-level quality through an algorithm that merges crowd-labelled images. Additionally, we employ pix2pixGAN, a generative AI model, to expand the training dataset with synthetic images that capture realistic morphological features. These methods are combined into a cohesive framework designed to produce an enhanced dataset, which can serve as a universal pre-processing pipeline to boost the training of any medical deep learning segmentation model. Our results demonstrate that this framework significantly improves model performance, especially when training data is limited.
Read more9/6/2024

0
Deep Mutual Learning among Partially Labeled Datasets for Multi-Organ Segmentation
Xiaoyu Liu, Linhao Qu, Ziyue Xie, Yonghong Shi, Zhijian Song
The task of labeling multiple organs for segmentation is a complex and time-consuming process, resulting in a scarcity of comprehensively labeled multi-organ datasets while the emergence of numerous partially labeled datasets. Current methods are inadequate in effectively utilizing the supervised information available from these datasets, thereby impeding the progress in improving the segmentation accuracy. This paper proposes a two-stage multi-organ segmentation method based on mutual learning, aiming to improve multi-organ segmentation performance by complementing information among partially labeled datasets. In the first stage, each partial-organ segmentation model utilizes the non-overlapping organ labels from different datasets and the distinct organ features extracted by different models, introducing additional mutual difference learning to generate higher quality pseudo labels for unlabeled organs. In the second stage, each full-organ segmentation model is supervised by fully labeled datasets with pseudo labels and leverages true labels from other datasets, while dynamically sharing accurate features across different models, introducing additional mutual similarity learning to enhance multi-organ segmentation performance. Extensive experiments were conducted on nine datasets that included the head and neck, chest, abdomen, and pelvis. The results indicate that our method has achieved SOTA performance in segmentation tasks that rely on partial labels, and the ablation studies have thoroughly confirmed the efficacy of the mutual learning mechanism.
Read more7/18/2024

0
New!Resolving Inconsistent Semantics in Multi-Dataset Image Segmentation
Qilong Zhangli, Di Liu, Abhishek Aich, Dimitris Metaxas, Samuel Schulter
Leveraging multiple training datasets to scale up image segmentation models is beneficial for increasing robustness and semantic understanding. Individual datasets have well-defined ground truth with non-overlapping mask layouts and mutually exclusive semantics. However, merging them for multi-dataset training disrupts this harmony and leads to semantic inconsistencies; for example, the class person in one dataset and class face in another will require multilabel handling for certain pixels. Existing methods struggle with this setting, particularly when evaluated on label spaces mixed from the individual training sets. To overcome these issues, we introduce a simple yet effective multi-dataset training approach by integrating language-based embeddings of class names and label space-specific query embeddings. Our method maintains high performance regardless of the underlying inconsistencies between training datasets. Notably, on four benchmark datasets with label space inconsistencies during inference, we outperform previous methods by 1.6% mIoU for semantic segmentation, 9.1% PQ for panoptic segmentation, 12.1% AP for instance segmentation, and 3.0% in the newly proposed PIQ metric.
Read more9/17/2024