How to Evaluate Semantic Communications for Images with ViTScore Metric?
2309.04891
0
0
📈
Abstract
Semantic communications (SC) have been expected to be a new paradigm shifting to catalyze the next generation communication, whose main concerns shift from accurate bit transmission to effective semantic information exchange in communications. However, the previous and widely-used metrics for images are not applicable to evaluate the image semantic similarity in SC. Classical metrics to measure the similarity between two images usually rely on the pixel level or the structural level, such as the PSNR and the MS-SSIM. Straightforwardly using some tailored metrics based on deep-learning methods in CV community, such as the LPIPS, is infeasible for SC. To tackle this, inspired by BERTScore in NLP community, we propose a novel metric for evaluating image semantic similarity, named Vision Transformer Score (ViTScore). We prove theoretically that ViTScore has 3 important properties, including symmetry, boundedness, and normalization, which make ViTScore convenient and intuitive for image measurement. To evaluate the performance of ViTScore, we compare ViTScore with 3 typical metrics (PSNR, MS-SSIM, and LPIPS) through 4 classes of experiments: (i) correlation with BERTScore through evaluation of image caption downstream CV task, (ii) evaluation in classical image communications, (iii) evaluation in image semantic communication systems, and (iv) evaluation in image semantic communication systems with semantic attack. Experimental results demonstrate that ViTScore is robust and efficient in evaluating the semantic similarity of images. Particularly, ViTScore outperforms the other 3 typical metrics in evaluating the image semantic changes by semantic attack, such as image inverse with Generative Adversarial Networks (GANs). This indicates that ViTScore is an effective performance metric when deployed in SC scenarios.
Create account to get full access
Overview
- Semantic communications (SC) is a new paradigm that shifts the focus from accurate bit transmission to effective semantic information exchange in communications.
- Existing metrics for evaluating image similarity, such as PSNR and MS-SSIM, are not suitable for SC as they rely on pixel-level or structural-level comparisons.
- To address this, the paper proposes a novel metric called Vision Transformer Score (ViTScore) for evaluating image semantic similarity, inspired by BERTScore in the NLP community.
Plain English Explanation
Semantic communications (SC) is a new way of thinking about how we transmit information over communication networks. Instead of just focusing on accurately sending bits of data, SC is more concerned with effectively conveying the meaning or semantic content of the information.
This is a significant shift from traditional communication methods, which have typically relied on metrics like PSNR (Peak Signal-to-Noise Ratio) and MS-SSIM (Multi-Scale Structural Similarity Index) to evaluate the similarity between images. These metrics work by comparing the pixels or structures of the images, but they don't really capture the underlying meaning or semantic content.
To address this limitation, the researchers in this paper have developed a new metric called ViTScore (Vision Transformer Score). This metric is inspired by a similar concept called BERTScore that is used in the field of natural language processing (NLP) to evaluate the semantic similarity of text.
The key idea behind ViTScore is to use a deep learning model, specifically a Vision Transformer, to extract meaningful features from the images and then compare those features to evaluate the semantic similarity between them. This approach is designed to be more aligned with the goals of semantic communications, where the focus is on conveying the underlying meaning rather than just the raw pixel data.
Technical Explanation
The paper proposes a novel metric called Vision Transformer Score (ViTScore) for evaluating the semantic similarity of images, which is crucial for the emerging field of semantic communications (SC).
The authors first explain that classical image similarity metrics, such as PSNR and MS-SSIM, are not suitable for SC scenarios as they focus on pixel-level or structural-level comparisons rather than semantic-level understanding. They also discuss the challenges of directly using deep learning-based metrics from the computer vision (CV) community, such as LPIPS, in the context of SC.
To address these limitations, the researchers were inspired by BERTScore in the NLP domain and proposed the ViTScore metric. ViTScore leverages a Vision Transformer model to extract semantic features from images and then compares these features to evaluate the semantic similarity between them.
The paper demonstrates that ViTScore has several desirable properties, including symmetry, boundedness, and normalization, which make it a convenient and intuitive metric for measuring image similarity in SC scenarios.
To evaluate the performance of ViTScore, the authors conducted four sets of experiments:
- Correlation with BERTScore: They assessed the correlation between ViTScore and BERTScore through the evaluation of an image caption downstream task in computer vision.
- Evaluation in classical image communications: They compared ViTScore with PSNR, MS-SSIM, and LPIPS in classical image communication settings.
- Evaluation in image semantic communication systems: They further evaluated the metrics in image semantic communication systems.
- Evaluation in image semantic communication systems with semantic attack: They assessed the metrics' performance in the presence of semantic attacks, such as image inversion using Generative Adversarial Networks (GANs).
The experimental results demonstrate that ViTScore outperforms the other three metrics, particularly in evaluating the semantic changes introduced by semantic attacks. This indicates that ViTScore is an effective performance metric for deployment in SC scenarios.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed ViTScore metric. The authors have recognized the limitations of existing image similarity metrics in the context of semantic communications and have provided a compelling solution.
One potential area for further research could be exploring the use of other vision transformer architectures or comparing the performance of ViTScore against other emerging image evaluation metrics, such as CrossScore or LipSim.
Additionally, it would be interesting to see how ViTScore performs in more diverse semantic communication scenarios, such as those involving different modalities (e.g., audio, video) or more complex semantic attacks.
Overall, the paper presents a valuable contribution to the field of semantic communications and offers a promising metric for evaluating image semantic similarity, which is a critical aspect of this emerging paradigm.
Conclusion
The paper introduces a novel metric called Vision Transformer Score (ViTScore) for evaluating the semantic similarity of images, which is a crucial requirement for the emerging field of semantic communications (SC). The authors demonstrate that ViTScore outperforms traditional image similarity metrics, such as PSNR and MS-SSIM, as well as deep learning-based metrics like LPIPS, particularly in the presence of semantic attacks.
The development of ViTScore represents an important step towards enabling more effective and semantically-aware communication systems, which have the potential to revolutionize various applications, from image and video transmission to remote sensing and beyond. As the field of semantic communications continues to evolve, metrics like ViTScore will play a vital role in ensuring the accurate and meaningful exchange of information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Semantic Similarity Score for Measuring Visual Similarity at Semantic Level
Senran Fan, Zhicheng Bao, Chen Dong, Haotai Liang, Xiaodong Xu, Ping Zhang
0
0
Semantic communication, as a revolutionary communication architecture, is considered a promising novel communication paradigm. Unlike traditional symbol-based error-free communication systems, semantic-based visual communication systems extract, compress, transmit, and reconstruct images at the semantic level. However, widely used image similarity evaluation metrics, whether pixel-based MSE or PSNR or structure-based MS-SSIM, struggle to accurately measure the loss of semantic-level information of the source during system transmission. This presents challenges in evaluating the performance of visual semantic communication systems, especially when comparing them with traditional communication systems. To address this, we propose a semantic evaluation metric -- SeSS (Semantic Similarity Score), based on Scene Graph Generation and graph matching, which shifts the similarity scores between images into semantic-level graph matching scores. Meanwhile, semantic similarity scores for tens of thousands of image pairs are manually annotated to fine-tune the hyperparameters in the graph matching algorithm, aligning the metric more closely with human semantic perception. The performance of the SeSS is tested on different datasets, including (1)images transmitted by traditional and semantic communication systems at different compression rates, (2)images transmitted by traditional and semantic communication systems at different signal-to-noise ratios, (3)images generated by large-scale model with different noise levels introduced, and (4)cases of images subjected to certain special transformations. The experiments demonstrate the effectiveness of SeSS, indicating that the metric can measure the semantic-level differences in semantic-level information of images and can be used for evaluation in visual semantic communication systems.
6/7/2024
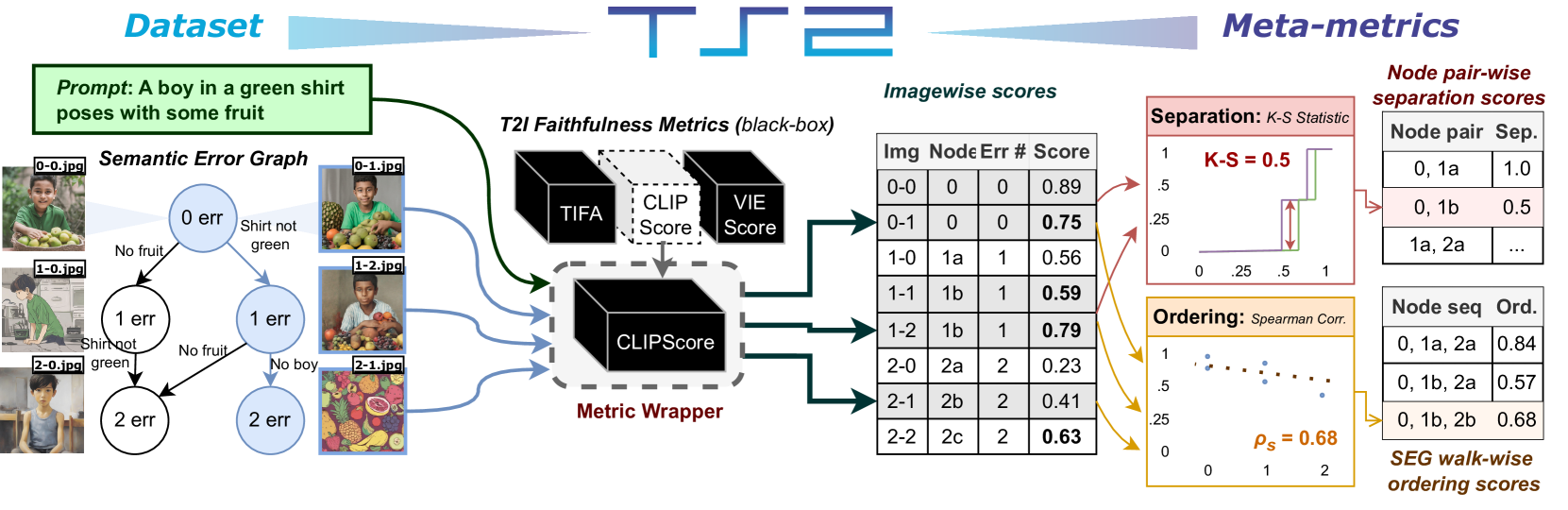
Who Evaluates the Evaluations? Objectively Scoring Text-to-Image Prompt Coherence Metrics with T2IScoreScore (TS2)
Michael Saxon, Fatima Jahara, Mahsa Khoshnoodi, Yujie Lu, Aditya Sharma, William Yang Wang
0
0
With advances in the quality of text-to-image (T2I) models has come interest in benchmarking their prompt faithfulness-the semantic coherence of generated images to the prompts they were conditioned on. A variety of T2I faithfulness metrics have been proposed, leveraging advances in cross-modal embeddings and vision-language models (VLMs). However, these metrics are not rigorously compared and benchmarked, instead presented with correlation to human Likert scores over a set of easy-to-discriminate images against seemingly weak baselines. We introduce T2IScoreScore (TS2), a curated set of semantic error graphs containing a prompt and a set increasingly erroneous images. These allow us to rigorously judge whether a given prompt faithfulness metric can correctly order images with respect to their objective error count and significantly discriminate between different error nodes, using meta-metric scores derived from established statistical tests. Surprisingly, we find that the state-of-the-art VLM-based metrics (e.g., TIFA, DSG, LLMScore, VIEScore) we tested fail to significantly outperform simple (and supposedly worse) feature-based metrics like CLIPScore, particularly on a hard subset of naturally-occurring T2I model errors. TS2 will enable the development of better T2I prompt faithfulness metrics through more rigorous comparison of their conformity to expected orderings and separations under objective criteria.
5/24/2024

VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, Wenhu Chen
0
0
In the rapidly advancing field of conditional image generation research, challenges such as limited explainability lie in effectively evaluating the performance and capabilities of various models. This paper introduces VIEScore, a Visual Instruction-guided Explainable metric for evaluating any conditional image generation tasks. VIEScore leverages general knowledge from Multimodal Large Language Models (MLLMs) as the backbone and does not require training or fine-tuning. We evaluate VIEScore on seven prominent tasks in conditional image tasks and found: (1) VIEScore (GPT4-o) achieves a high Spearman correlation of 0.4 with human evaluations, while the human-to-human correlation is 0.45. (2) VIEScore (with open-source MLLM) is significantly weaker than GPT-4o and GPT-4v in evaluating synthetic images. (3) VIEScore achieves a correlation on par with human ratings in the generation tasks but struggles in editing tasks. With these results, we believe VIEScore shows its great potential to replace human judges in evaluating image synthesis tasks.
6/4/2024
🧪
Similarity Metrics for MR Image-To-Image Translation
Melanie Dohmen, Mark Klemens, Ivo Baltruschat, Tuan Truong, Matthias Lenga
0
0
Image-to-image translation can create large impact in medical imaging, for instance the possibility to synthetically transform images to other modalities, sequence types, higher resolutions or lower noise levels. In order to assure a high level of patient safety, these methods are mostly validated by human reader studies, which require a considerable amount of time and costs. Quantitative metrics have been used to complement such studies and to provide reproducible and objective assessment of synthetic images. Even though the SSIM and PSNR metrics are extensively used, they do not detect all types of errors in synthetic images as desired. Other metrics could provide additional useful evaluation. In this study, we give an overview and a quantitative analysis of 15 metrics for assessing the quality of synthetically generated images. We include 11 full-reference metrics (SSIM, MS-SSIM, CW-SSIM, PSNR, MSE, NMSE, MAE, LPIPS, DISTS, NMI and PCC), three non-reference metrics (BLUR, MLC, MSLC) and one downstream task segmentation metric (DICE) to detect 11 kinds of typical distortions and artifacts that occur in MR images. In addition, we analyze the influence of four prominent normalization methods (Minmax, cMinmax, Zscore and Quantile) on the different metrics and distortions. Finally, we provide adverse examples to highlight pitfalls in metric assessment and derive recommendations for effective usage of the analyzed similarity metrics for evaluation of image-to-image translation models.
6/19/2024