Progressive Semantic-Guided Vision Transformer for Zero-Shot Learning
2404.07713
0
0

Abstract
Zero-shot learning (ZSL) recognizes the unseen classes by conducting visual-semantic interactions to transfer semantic knowledge from seen classes to unseen ones, supported by semantic information (e.g., attributes). However, existing ZSL methods simply extract visual features using a pre-trained network backbone (i.e., CNN or ViT), which fail to learn matched visual-semantic correspondences for representing semantic-related visual features as lacking of the guidance of semantic information, resulting in undesirable visual-semantic interactions. To tackle this issue, we propose a progressive semantic-guided vision transformer for zero-shot learning (dubbed ZSLViT). ZSLViT mainly considers two properties in the whole network: i) discover the semantic-related visual representations explicitly, and ii) discard the semantic-unrelated visual information. Specifically, we first introduce semantic-embedded token learning to improve the visual-semantic correspondences via semantic enhancement and discover the semantic-related visual tokens explicitly with semantic-guided token attention. Then, we fuse low semantic-visual correspondence visual tokens to discard the semantic-unrelated visual information for visual enhancement. These two operations are integrated into various encoders to progressively learn semantic-related visual representations for accurate visual-semantic interactions in ZSL. The extensive experiments show that our ZSLViT achieves significant performance gains on three popular benchmark datasets, i.e., CUB, SUN, and AWA2.
Create account to get full access
Overview
- Proposes a novel "Progressive Semantic-Guided Vision Transformer" for zero-shot learning
- Leverages semantic information to guide the vision transformer's learning process
- Aims to improve the model's performance on unseen classes without any training data
Plain English Explanation
The paper introduces a new type of vision transformer model that uses semantic information to help it learn. Typically, vision transformer models are trained on large datasets of labeled images. However, this can be a challenge for certain tasks, like identifying objects that the model has never seen before (known as "zero-shot learning").
To address this, the researchers developed a vision transformer that incorporates semantic data - information about the meaning and relationships between different concepts. This "semantic-guided" approach allows the model to better understand the visual characteristics of unseen classes, even without any training examples.
The key innovation is that the semantic information is gradually incorporated into the vision transformer as the model trains, in a "progressive" fashion. This helps the model learn more efficiently and effectively compared to simply appending the semantic data all at once.
By combining the power of vision transformers with semantic guidance, the researchers were able to create a model that performs well on zero-shot learning tasks, where it needs to classify objects it has never seen before. This could have important applications in areas like robotics, medical imaging, and other domains where training data is scarce.
Technical Explanation
The proposed "Progressive Semantic-Guided Vision Transformer" (PSGVT) architecture builds upon the standard vision transformer by incorporating semantic information in a progressive manner during training.
The model starts with a typical vision transformer backbone, which takes image patches as input and produces visual representations. Alongside this, the model also has a semantic pathway that takes in textual descriptions of the classes and generates semantic embeddings.
During training, the visual and semantic embeddings are gradually fused together through a series of "semantic-guided attention" layers. These layers allow the visual representations to be refined and enhanced using the semantic information, helping the model learn more powerful visual-semantic associations.
The progressive nature of this fusion process is key - the semantic guidance starts off weak and becomes stronger over the course of training. This allows the model to first learn robust visual representations, before fine-tuning them using the semantic data.
Experiments on standard zero-shot learning benchmarks demonstrate the effectiveness of the PSGVT approach. Compared to prior methods that either ignore semantic information or fuse it in a more simplistic way, the progressive semantic guidance allows the model to significantly outperform the state-of-the-art.
Critical Analysis
The paper provides a compelling approach to addressing the challenge of zero-shot learning, which is an important problem in computer vision with many real-world applications. The progressive semantic-guided architecture is a clever way to leverage textual class descriptions to enhance the visual representations learned by the transformer.
However, the paper does not deeply explore the limitations of this approach. For example, the researchers only evaluate on standard benchmark datasets, which may not capture the full complexity of real-world zero-shot scenarios. Additionally, the impact of the degree of semantic information available, or the quality of the textual descriptions, is not thoroughly investigated.
There are also open questions about the generalizability of the method. Would the progressive fusion strategy work equally well for other types of auxiliary semantic data, beyond just textual descriptions? And how robust is the approach to noisy or incomplete semantic information?
Further research could explore these areas, as well as investigating the interpretability and explainability of the semantic-guided attention mechanism. Understanding how the model is using the semantic data to inform its visual representations could lead to additional insights.
Conclusion
Overall, the "Progressive Semantic-Guided Vision Transformer" represents a meaningful advance in zero-shot learning, demonstrating how semantic information can be effectively incorporated into vision transformer models. By progressively fusing visual and semantic embeddings, the approach is able to leverage textual class descriptions to improve performance on unseen categories.
This work highlights the potential for vision-language models to tackle challenging computer vision problems where training data is scarce. As AI systems become more widely deployed, techniques like this that can adapt to new scenarios without extensive retraining will be increasingly valuable. The paper lays an important foundation for future research in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning
Wenjin Hou, Shiming Chen, Shuhuang Chen, Ziming Hong, Yan Wang, Xuetao Feng, Salman Khan, Fahad Shahbaz Khan, Xinge You
0
0
Generative Zero-shot learning (ZSL) learns a generator to synthesize visual samples for unseen classes, which is an effective way to advance ZSL. However, existing generative methods rely on the conditions of Gaussian noise and the predefined semantic prototype, which limit the generator only optimized on specific seen classes rather than characterizing each visual instance, resulting in poor generalizations (textit{e.g.}, overfitting to seen classes). To address this issue, we propose a novel Visual-Augmented Dynamic Semantic prototype method (termed VADS) to boost the generator to learn accurate semantic-visual mapping by fully exploiting the visual-augmented knowledge into semantic conditions. In detail, VADS consists of two modules: (1) Visual-aware Domain Knowledge Learning module (VDKL) learns the local bias and global prior of the visual features (referred to as domain visual knowledge), which replace pure Gaussian noise to provide richer prior noise information; (2) Vision-Oriented Semantic Updation module (VOSU) updates the semantic prototype according to the visual representations of the samples. Ultimately, we concatenate their output as a dynamic semantic prototype, which serves as the condition of the generator. Extensive experiments demonstrate that our VADS achieves superior CZSL and GZSL performances on three prominent datasets and outperforms other state-of-the-art methods with averaging increases by 6.4%, 5.9% and 4.2% on SUN, CUB and AWA2, respectively.
4/24/2024
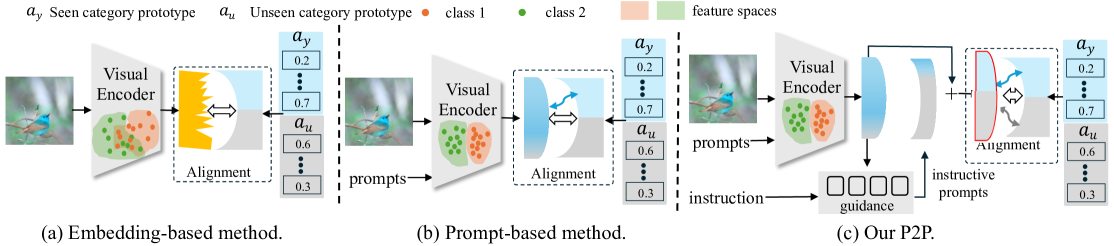
Instructing Prompt-to-Prompt Generation for Zero-Shot Learning
Man Liu, Huihui Bai, Feng Li, Chunjie Zhang, Yunchao Wei, Meng Wang, Tat-Seng Chua, Yao Zhao
0
0
Zero-shot learning (ZSL) aims to explore the semantic-visual interactions to discover comprehensive knowledge transferred from seen categories to classify unseen categories. Recently, prompt engineering has emerged in ZSL, demonstrating impressive potential as it enables the zero-shot transfer of diverse visual concepts to downstream tasks. However, these methods are still not well generalized to broad unseen domains. A key reason is that the fixed adaption of learnable prompts on seen domains makes it tend to over-emphasize the primary visual features observed during training. In this work, we propose a textbf{P}rompt-to-textbf{P}rompt generation methodology (textbf{P2P}), which addresses this issue by further embracing the instruction-following technique to distill instructive visual prompts for comprehensive transferable knowledge discovery. The core of P2P is to mine semantic-related instruction from prompt-conditioned visual features and text instruction on modal-sharing semantic concepts and then inversely rectify the visual representations with the guidance of the learned instruction prompts. This enforces the compensation for missing visual details to primary contexts and further eliminates the cross-modal disparity, endowing unseen domain generalization. Through extensive experimental results, we demonstrate the efficacy of P2P in achieving superior performance over state-of-the-art methods.
6/6/2024
🌐
Dual Relation Mining Network for Zero-Shot Learning
Jinwei Han, Yingguo Gao, Zhiwen Lin, Ke Yan, Shouhong Ding, Yuan Gao, Gui-Song Xia
0
0
Zero-shot learning (ZSL) aims to recognize novel classes through transferring shared semantic knowledge (e.g., attributes) from seen classes to unseen classes. Recently, attention-based methods have exhibited significant progress which align visual features and attributes via a spatial attention mechanism. However, these methods only explore visual-semantic relationship in the spatial dimension, which can lead to classification ambiguity when different attributes share similar attention regions, and semantic relationship between attributes is rarely discussed. To alleviate the above problems, we propose a Dual Relation Mining Network (DRMN) to enable more effective visual-semantic interactions and learn semantic relationship among attributes for knowledge transfer. Specifically, we introduce a Dual Attention Block (DAB) for visual-semantic relationship mining, which enriches visual information by multi-level feature fusion and conducts spatial attention for visual to semantic embedding. Moreover, an attribute-guided channel attention is utilized to decouple entangled semantic features. For semantic relationship modeling, we utilize a Semantic Interaction Transformer (SIT) to enhance the generalization of attribute representations among images. Additionally, a global classification branch is introduced as a complement to human-defined semantic attributes, and we then combine the results with attribute-based classification. Extensive experiments demonstrate that the proposed DRMN leads to new state-of-the-art performances on three standard ZSL benchmarks, i.e., CUB, SUN, and AwA2.
5/7/2024

A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
Thomas Stegmuller, Tim Lebailly, Nikola Dukic, Behzad Bozorgtabar, Tinne Tuytelaars, Jean-Philippe Thiran
0
0
Zero-shot classification capabilities naturally arise in models trained within a vision-language contrastive framework. Despite their classification prowess, these models struggle in dense tasks like zero-shot open-vocabulary segmentation. This deficiency is often attributed to the absence of localization cues in captions and the intertwined nature of the learning process, which encompasses both image representation learning and cross-modality alignment. To tackle these issues, we propose SimZSS, a Simple framework for open-vocabulary Zero-Shot Segmentation. The method is founded on two key principles: i) leveraging frozen vision-only models that exhibit spatial awareness while exclusively aligning the text encoder and ii) exploiting the discrete nature of text and linguistic knowledge to pinpoint local concepts within captions. By capitalizing on the quality of the visual representations, our method requires only image-caption pairs datasets and adapts to both small curated and large-scale noisy datasets. When trained on COCO Captions across 8 GPUs, SimZSS achieves state-of-the-art results on 7 out of 8 benchmark datasets in less than 15 minutes.
7/2/2024