How to Measure the Intelligence of Large Language Models?

0
Sign in to get full access
Overview
- The paper discusses how to measure the intelligence of large language models (LLMs).
- LLMs like ChatGPT have generated significant interest and debate around their capabilities.
- Evaluating the intelligence of these models is crucial for understanding their potential and limitations.
Plain English Explanation
The paper tackles the challenge of measuring the intelligence of large language models. These powerful AI systems, like ChatGPT, have captured the public's imagination with their impressive language abilities. However, accurately assessing their intelligence is crucial for understanding their true capabilities and limitations.
The researchers propose a multi-faceted approach to evaluating LLMs, looking at factors like their reasoning skills, problem-solving abilities, and **capacity for abstract thought. By examining these different aspects of intelligence, the researchers aim to provide a more comprehensive understanding of how these models think and perform compared to humans.
Technical Explanation
The paper outlines a framework for evaluating the intelligence of large language models. The researchers propose assessing LLMs across several key dimensions:
- Reasoning Skills: Examining the models' logical reasoning and ability to draw valid conclusions from given information.
- Problem-Solving Abilities: Testing the models' capacity to tackle complex problems and devise effective solutions.
- Capacity for Abstract Thought: Evaluating the models' understanding of abstract concepts and their ability to apply this knowledge in novel situations.
By systematically evaluating LLMs across these dimensions, the researchers aim to gain a more holistic understanding of their intelligence and cognitive abilities.
Critical Analysis
The paper acknowledges the complexity and challenges involved in measuring the intelligence of large language models. The authors note that existing evaluation methods may not fully capture the nuances of these systems, and they call for the development of more sophisticated and comprehensive assessment tools.
Additionally, the researchers caution against overestimating the capabilities of LLMs, emphasizing the need for continued research and cautious interpretation of the models' performance. They highlight the potential for these systems to exhibit biases or limitations that may not be immediately apparent.
Conclusion
This paper represents an important contribution to the ongoing debate around the intelligence of large language models. By proposing a multifaceted approach to evaluation, the researchers aim to provide a more holistic and reliable understanding of these powerful AI systems.
As LLMs continue to evolve and influence various domains, the insights from this research can inform the development of more robust and responsible AI that can be leveraged to benefit society. However, the authors also emphasize the need for continued vigilance and critical assessment to ensure these technologies are deployed in an ethical and transparent manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
How to Measure the Intelligence of Large Language Models?
Nils Korber, Silvan Wehrli, Christopher Irrgang
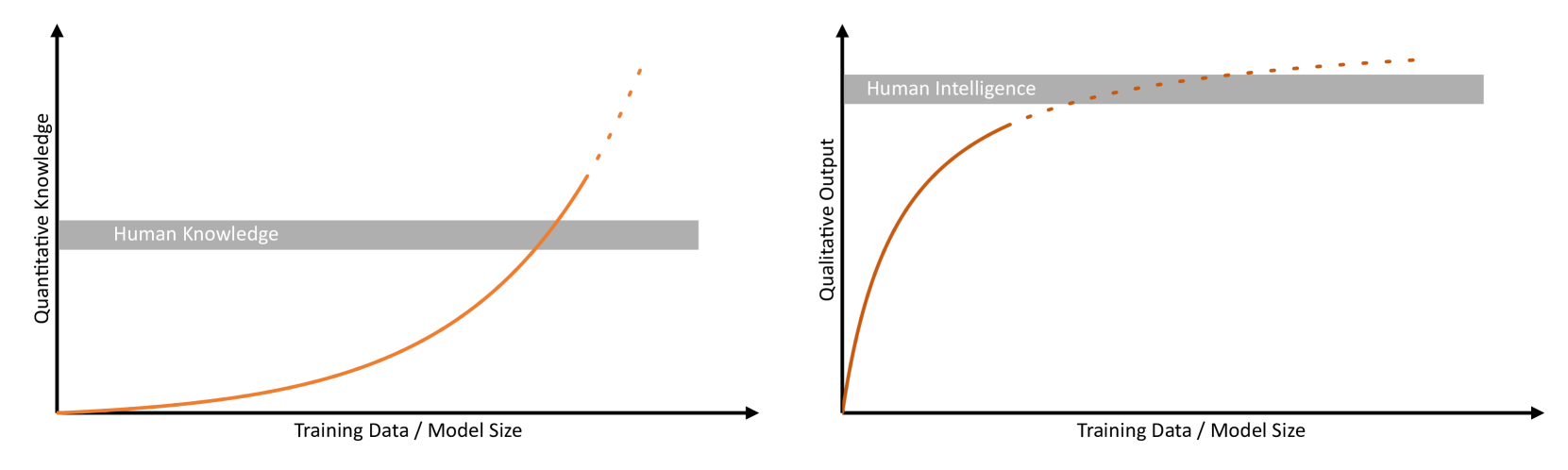
With the release of ChatGPT and other large language models (LLMs) the discussion about the intelligence, possibilities, and risks, of current and future models have seen large attention. This discussion included much debated scenarios about the imminent rise of so-called super-human AI, i.e., AI systems that are orders of magnitude smarter than humans. In the spirit of Alan Turing, there is no doubt that current state-of-the-art language models already pass his famous test. Moreover, current models outperform humans in several benchmark tests, so that publicly available LLMs have already become versatile companions that connect everyday life, industry and science. Despite their impressive capabilities, LLMs sometimes fail completely at tasks that are thought to be trivial for humans. In other cases, the trustworthiness of LLMs becomes much more elusive and difficult to evaluate. Taking the example of academia, language models are capable of writing convincing research articles on a given topic with only little input. Yet, the lack of trustworthiness in terms of factual consistency or the existence of persistent hallucinations in AI-generated text bodies has led to a range of restrictions for AI-based content in many scientific journals. In view of these observations, the question arises as to whether the same metrics that apply to human intelligence can also be applied to computational methods and has been discussed extensively. In fact, the choice of metrics has already been shown to dramatically influence assessments on potential intelligence emergence. Here, we argue that the intelligence of LLMs should not only be assessed by task-specific statistical metrics, but separately in terms of qualitative and quantitative measures.
Read more7/31/2024
💬
0
Assessing the nature of large language models: A caution against anthropocentrism
Ann Speed
Generative AI models garnered a large amount of public attention and speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion camps exist: one excited about possibilities these models offer for fundamental changes to human tasks, and another highly concerned about power these models seem to have. To address these concerns, we assessed several LLMs, primarily GPT 3.5, using standard, normed, and validated cognitive and personality measures. For this seedling project, we developed a battery of tests that allowed us to estimate the boundaries of some of these models capabilities, how stable those capabilities are over a short period of time, and how they compare to humans. Our results indicate that LLMs are unlikely to have developed sentience, although its ability to respond to personality inventories is interesting. GPT3.5 did display large variability in both cognitive and personality measures over repeated observations, which is not expected if it had a human-like personality. Variability notwithstanding, LLMs display what in a human would be considered poor mental health, including low self-esteem, marked dissociation from reality, and in some cases narcissism and psychopathy, despite upbeat and helpful responses.
Read more6/28/2024

34
Evidence of interrelated cognitive-like capabilities in large language models: Indications of artificial general intelligence or achievement?
David Ili'c, Gilles E. Gignac
Large language models (LLMs) are advanced artificial intelligence (AI) systems that can perform a variety of tasks commonly found in human intelligence tests, such as defining words, performing calculations, and engaging in verbal reasoning. There are also substantial individual differences in LLM capacities. Given the consistent observation of a positive manifold and general intelligence factor in human samples, along with group-level factors (e.g., crystallized intelligence), we hypothesized that LLM test scores may also exhibit positive intercorrelations, which could potentially give rise to an artificial general ability (AGA) factor and one or more group-level factors. Based on a sample of 591 LLMs and scores from 12 tests aligned with fluid reasoning (Gf), domain-specific knowledge (Gkn), reading/writing (Grw), and quantitative knowledge (Gq), we found strong empirical evidence for a positive manifold and a general factor of ability. Additionally, we identified a combined Gkn/Grw group-level factor. Finally, the number of LLM parameters correlated positively with both general factor of ability and Gkn/Grw factor scores, although the effects showed diminishing returns. We interpreted our results to suggest that LLMs, like human cognitive abilities, may share a common underlying efficiency in processing information and solving problems, though whether LLMs manifest primarily achievement/expertise rather than intelligence remains to be determined. Finally, while models with greater numbers of parameters exhibit greater general cognitive-like abilities, akin to the connection between greater neuronal density and human general intelligence, other characteristics must also be involved.
Read more9/12/2024
🧪
1
Testing AI on language comprehension tasks reveals insensitivity to underlying meaning
Vittoria Dentella, Fritz Guenther, Elliot Murphy, Gary Marcus, Evelina Leivada
Large Language Models (LLMs) are recruited in applications that span from clinical assistance and legal support to question answering and education. Their success in specialized tasks has led to the claim that they possess human-like linguistic capabilities related to compositional understanding and reasoning. Yet, reverse-engineering is bound by Moravec's Paradox, according to which easy skills are hard. We systematically assess 7 state-of-the-art models on a novel benchmark. Models answered a series of comprehension questions, each prompted multiple times in two settings, permitting one-word or open-length replies. Each question targets a short text featuring high-frequency linguistic constructions. To establish a baseline for achieving human-like performance, we tested 400 humans on the same prompts. Based on a dataset of n=26,680 datapoints, we discovered that LLMs perform at chance accuracy and waver considerably in their answers. Quantitatively, the tested models are outperformed by humans, and qualitatively their answers showcase distinctly non-human errors in language understanding. We interpret this evidence as suggesting that, despite their usefulness in various tasks, current AI models fall short of understanding language in a way that matches humans, and we argue that this may be due to their lack of a compositional operator for regulating grammatical and semantic information.
Read more7/10/2024