Are Large Language Models Good Statisticians?

0

Sign in to get full access
Overview
- The paper investigates whether large language models (LLMs) are good at performing statistical reasoning tasks.
- The researchers created a new dataset called StatQA to evaluate the statistical reasoning capabilities of LLMs.
- The experiments show that while LLMs perform well on simple statistical tasks, they struggle with more complex statistical reasoning problems.
Plain English Explanation
The paper looks at whether large language models (LLMs) - powerful AI systems trained on massive amounts of text data - are good at doing statistical reasoning. The researchers created a new dataset called StatQA that tests the statistical skills of LLMs. They found that LLMs can handle basic statistical tasks pretty well, but when it comes to more complex statistical reasoning problems, the LLMs start to struggle.
This suggests that while LLMs are impressive in many ways, they may not be superhuman when it comes to the kind of statistical thinking and problem-solving that humans excel at. The paper provides some insights into the limitations of current LLMs and points to areas where more research is needed to improve their statistical capabilities.
Technical Explanation
The paper introduces a new dataset called StatQA to evaluate the statistical reasoning abilities of large language models (LLMs). StatQA consists of a series of multiple-choice questions that test different aspects of statistical reasoning, ranging from simple calculations to more advanced concepts like hypothesis testing and Bayesian inference.
The researchers tested several prominent LLMs, including GPT-3, T5, and PaLM, on the StatQA dataset. The results showed that the LLMs performed well on simpler statistical tasks, but struggled significantly on more complex problems involving things like experimental design, causal reasoning, and advanced statistical concepts.
The paper provides a detailed analysis of the types of statistical reasoning errors made by the LLMs, shedding light on their underlying limitations. For example, the models often failed to properly account for issues like sample size, confounding variables, and the distinction between correlation and causation.
Overall, the findings suggest that while LLMs have impressive language and reasoning abilities, they may not be as statistically adept as humans. The researchers argue that developing more robust statistical reasoning capabilities in LLMs is an important area for future AI research and development.
Critical Analysis
The paper makes a valuable contribution by rigorously evaluating the statistical reasoning abilities of large language models. The creation of the StatQA dataset is a particularly noteworthy achievement, as it provides a standardized benchmark for assessing this important capability.
However, the paper also acknowledges several limitations of the study. For example, the StatQA dataset may not capture the full breadth of statistical reasoning required in real-world applications, and the performance of the LLMs may improve with further fine-tuning or architectural changes.
Additionally, the paper does not delve deeply into the underlying reasons why the LLMs struggled with more complex statistical reasoning. A more thorough investigation of the models' strengths, weaknesses, and biases could provide deeper insights and guide future research.
It would also be interesting to see how the LLMs' performance compares to that of human participants on the StatQA tasks, which could help contextualize the models' capabilities and limitations.
Overall, this paper serves as an important step in understanding the current state-of-the-art in statistical reasoning for large language models. The findings suggest that while these models are impressive in many ways, there is still significant room for improvement when it comes to the kind of rigorous analytical thinking required for advanced statistical problems.
Conclusion
The paper "Are Large Language Models Good Statisticians?" investigates the statistical reasoning capabilities of large language models (LLMs) using a new dataset called StatQA. The results show that while LLMs perform well on simple statistical tasks, they struggle significantly with more complex statistical reasoning problems.
This suggests that, despite their impressive language and reasoning abilities, current LLMs may not be as statistically adept as humans. The paper provides valuable insights into the limitations of LLMs and highlights the need for further research to develop more robust statistical reasoning capabilities in these powerful AI systems.
As LLMs continue to advance and find applications in fields that rely heavily on statistical analysis, such as link to "Are Large Language Models Superhuman Chemists?" and link to "Can Large Language Models Make the Grade?", understanding and addressing their statistical shortcomings will be crucial. The insights from this paper can inform the development of more statistically-savvy LLMs that can better support complex decision-making and problem-solving tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Are Large Language Models Good Statisticians?
Yizhang Zhu, Shiyin Du, Boyan Li, Yuyu Luo, Nan Tang
Large Language Models (LLMs) have demonstrated impressive capabilities across a range of scientific tasks including mathematics, physics, and chemistry. Despite their successes, the effectiveness of LLMs in handling complex statistical tasks remains systematically under-explored. To bridge this gap, we introduce StatQA, a new benchmark designed for statistical analysis tasks. StatQA comprises 11,623 examples tailored to evaluate LLMs' proficiency in specialized statistical tasks and their applicability assessment capabilities, particularly for hypothesis testing methods. We systematically experiment with representative LLMs using various prompting strategies and show that even state-of-the-art models such as GPT-4o achieve a best performance of only 64.83%, indicating significant room for improvement. Notably, while open-source LLMs (e.g. LLaMA-3) show limited capability, those fine-tuned ones exhibit marked improvements, outperforming all in-context learning-based methods (e.g. GPT-4o). Moreover, our comparative human experiments highlight a striking contrast in error types between LLMs and humans: LLMs primarily make applicability errors, whereas humans mostly make statistical task confusion errors. This divergence highlights distinct areas of proficiency and deficiency, suggesting that combining LLM and human expertise could lead to complementary strengths, inviting further investigation into their collaborative potential.
Read more6/13/2024
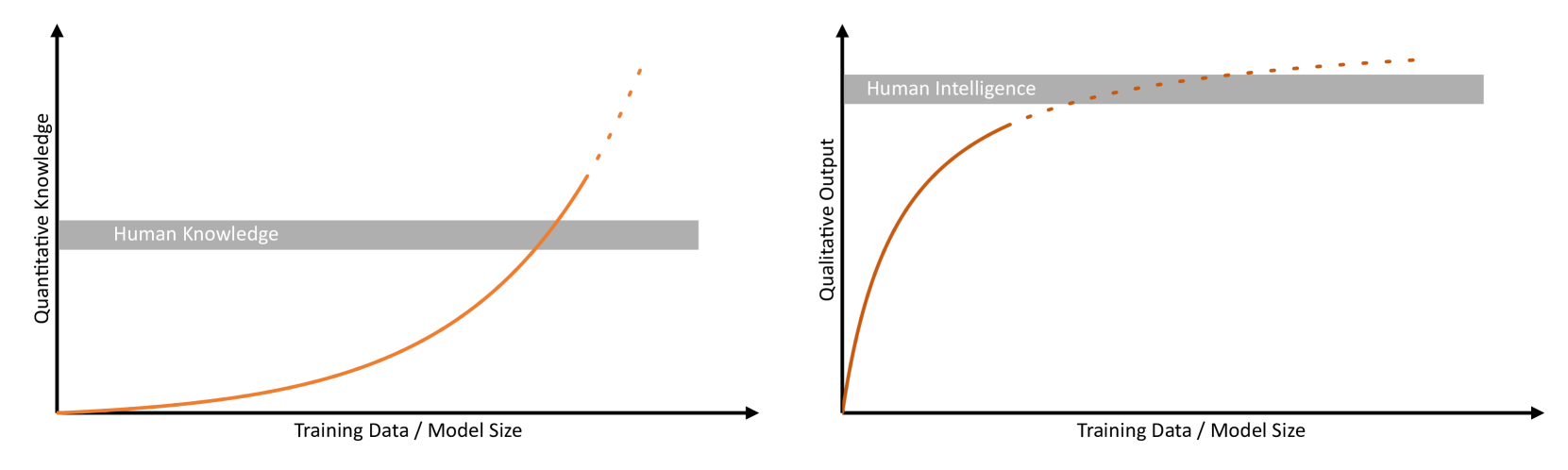
0
How to Measure the Intelligence of Large Language Models?
Nils Korber, Silvan Wehrli, Christopher Irrgang
With the release of ChatGPT and other large language models (LLMs) the discussion about the intelligence, possibilities, and risks, of current and future models have seen large attention. This discussion included much debated scenarios about the imminent rise of so-called super-human AI, i.e., AI systems that are orders of magnitude smarter than humans. In the spirit of Alan Turing, there is no doubt that current state-of-the-art language models already pass his famous test. Moreover, current models outperform humans in several benchmark tests, so that publicly available LLMs have already become versatile companions that connect everyday life, industry and science. Despite their impressive capabilities, LLMs sometimes fail completely at tasks that are thought to be trivial for humans. In other cases, the trustworthiness of LLMs becomes much more elusive and difficult to evaluate. Taking the example of academia, language models are capable of writing convincing research articles on a given topic with only little input. Yet, the lack of trustworthiness in terms of factual consistency or the existence of persistent hallucinations in AI-generated text bodies has led to a range of restrictions for AI-based content in many scientific journals. In view of these observations, the question arises as to whether the same metrics that apply to human intelligence can also be applied to computational methods and has been discussed extensively. In fact, the choice of metrics has already been shown to dramatically influence assessments on potential intelligence emergence. Here, we argue that the intelligence of LLMs should not only be assessed by task-specific statistical metrics, but separately in terms of qualitative and quantitative measures.
Read more7/31/2024

0
Benchmarking Large Language Models for Math Reasoning Tasks
Kathrin Se{ss}ler, Yao Rong, Emek Gozluklu, Enkelejda Kasneci
The use of Large Language Models (LLMs) in mathematical reasoning has become a cornerstone of related research, demonstrating the intelligence of these models and enabling potential practical applications through their advanced performance, such as in educational settings. Despite the variety of datasets and in-context learning algorithms designed to improve the ability of LLMs to automate mathematical problem solving, the lack of comprehensive benchmarking across different datasets makes it complicated to select an appropriate model for specific tasks. In this project, we present a benchmark that fairly compares seven state-of-the-art in-context learning algorithms for mathematical problem solving across five widely used mathematical datasets on four powerful foundation models. Furthermore, we explore the trade-off between efficiency and performance, highlighting the practical applications of LLMs for mathematical reasoning. Our results indicate that larger foundation models like GPT-4o and LLaMA 3-70B can solve mathematical reasoning independently from the concrete prompting strategy, while for smaller models the in-context learning approach significantly influences the performance. Moreover, the optimal prompt depends on the chosen foundation model. We open-source our benchmark code to support the integration of additional models in future research.
Read more8/21/2024
💬
0
From Text to Insight: Leveraging Large Language Models for Performance Evaluation in Management
Ning Li, Huaikang Zhou, Mingze Xu
This study explores the potential of Large Language Models (LLMs), specifically GPT-4, to enhance objectivity in organizational task performance evaluations. Through comparative analyses across two studies, including various task performance outputs, we demonstrate that LLMs can serve as a reliable and even superior alternative to human raters in evaluating knowledge-based performance outputs, which are a key contribution of knowledge workers. Our results suggest that GPT ratings are comparable to human ratings but exhibit higher consistency and reliability. Additionally, combined multiple GPT ratings on the same performance output show strong correlations with aggregated human performance ratings, akin to the consensus principle observed in performance evaluation literature. However, we also find that LLMs are prone to contextual biases, such as the halo effect, mirroring human evaluative biases. Our research suggests that while LLMs are capable of extracting meaningful constructs from text-based data, their scope is currently limited to specific forms of performance evaluation. By highlighting both the potential and limitations of LLMs, our study contributes to the discourse on AI role in management studies and sets a foundation for future research to refine AI theoretical and practical applications in management.
Read more8/13/2024