Can Large Language Models Write Parallel Code?
2401.12554
1
0
💬
Abstract
Large language models are increasingly becoming a popular tool for software development. Their ability to model and generate source code has been demonstrated in a variety of contexts, including code completion, summarization, translation, and lookup. However, they often struggle to generate code for complex programs. In this paper, we study the capabilities of state-of-the-art language models to generate parallel code. In order to evaluate language models, we create a benchmark, ParEval, consisting of prompts that represent 420 different coding tasks related to scientific and parallel computing. We use ParEval to evaluate the effectiveness of several state-of-the-art open- and closed-source language models on these tasks. We introduce novel metrics for evaluating the performance of generated code, and use them to explore how well each large language model performs for 12 different computational problem types and six different parallel programming models.
Create account to get full access
Overview
- This paper examines the capabilities of large language models (LLMs) in generating parallel code for complex programs.
- The researchers created a benchmark called ParEval, which consists of 420 coding tasks related to scientific and parallel computing, to evaluate the performance of various state-of-the-art open- and closed-source LLMs.
- Novel metrics were introduced to assess the quality of the generated code, and the models' performance was analyzed across 12 computational problem types and six parallel programming models.
Plain English Explanation
Large language models (LLMs) have become increasingly popular tools for software development, as they can model and generate source code for various tasks, such as code completion, summarization, translation, and lookup. However, these models often struggle to generate code for complex programs.
To address this, the researchers in this paper created a benchmark called ParEval, which consists of 420 coding tasks related to scientific and parallel computing. They used this benchmark to evaluate the effectiveness of several state-of-the-art open- and closed-source LLMs in generating parallel code.
The researchers introduced novel metrics to assess the quality of the generated code, and they used these metrics to explore how well each LLM performed for 12 different computational problem types and six different parallel programming models. This allowed them to gain insights into the strengths and limitations of these models when it comes to generating complex, parallel code.
Technical Explanation
The researchers in this paper investigated the capabilities of LLMs in generating parallel code for complex programs. They created a benchmark called ParEval, which consists of 420 coding tasks related to scientific and parallel computing, to evaluate the performance of various state-of-the-art open- and closed-source LLMs.
To assess the quality of the generated code, the researchers introduced novel metrics, such as performance-aligned metrics and RealHumanEval scores. They used these metrics to analyze the models' performance across 12 different computational problem types and six parallel programming models, including OpenMP, MPI, and CUDA.
The results of their experiments provide insights into the strengths and limitations of these LLMs when it comes to generating parallel code. The researchers found that while the models were able to generate some parallel code, they often struggled with more complex tasks, particularly when it came to optimizing the performance of the generated code.
Critical Analysis
The researchers acknowledged several caveats and limitations in their study. For example, they note that the ParEval benchmark may not capture the full breadth of parallel computing tasks that LLMs may be asked to handle in real-world scenarios. Additionally, the researchers did not explore the models' ability to learn and adapt to new parallel programming patterns over time, which could be an important capability in practical applications.
Furthermore, the study focused primarily on evaluating the models' code generation capabilities, but did not delve deeply into their potential for other software development tasks, such as code summarization or automated programming. Exploring the models' broader capabilities in the software engineering domain could provide a more comprehensive understanding of their potential and limitations.
Conclusion
This paper presents a comprehensive evaluation of the capabilities of state-of-the-art LLMs in generating parallel code for complex programs. By creating the ParEval benchmark and introducing novel metrics, the researchers were able to gain valuable insights into the strengths and limitations of these models.
The findings suggest that while LLMs can be a useful tool for certain software development tasks, they still struggle with generating high-performance parallel code, particularly for more complex computational problems. As these models continue to evolve, further research is needed to address these limitations and unlock the full potential of LLMs in the software engineering domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
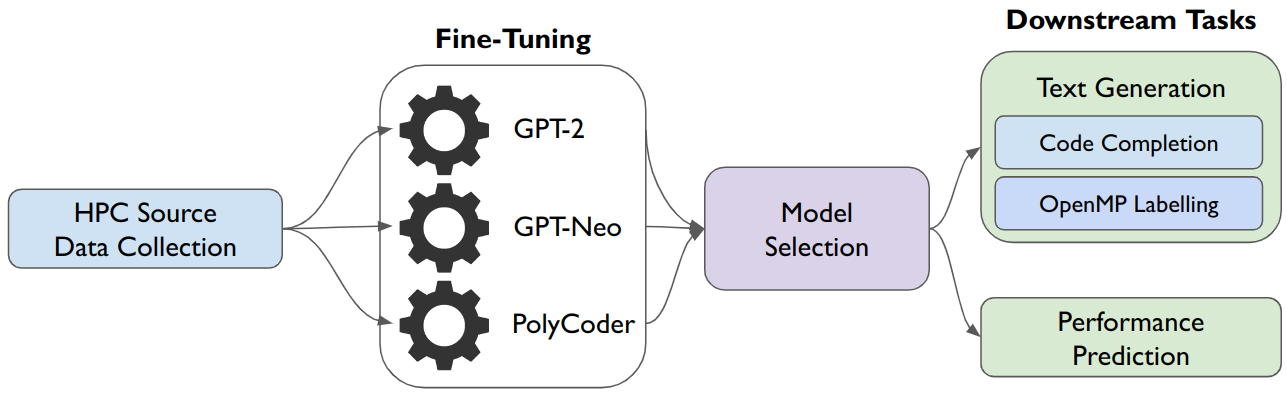
HPC-Coder: Modeling Parallel Programs using Large Language Models
Daniel Nichols, Aniruddha Marathe, Harshitha Menon, Todd Gamblin, Abhinav Bhatele
0
0
Parallel programs in high performance computing (HPC) continue to grow in complexity and scale in the exascale era. The diversity in hardware and parallel programming models make developing, optimizing, and maintaining parallel software even more burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. Until recently, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform, especially for parallel programs. However, with recent advancements in language modeling, and the availability of large amounts of open-source code related data, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We introduce a new dataset of HPC and scientific codes and use it to fine-tune several pre-trained models. We compare several pre-trained LLMs on HPC-related tasks and introduce a new model, HPC-Coder, fine-tuned on parallel codes. In our experiments, we show that this model can auto-complete HPC functions where generic models cannot, decorate for loops with OpenMP pragmas, and model performance changes in scientific application repositories as well as programming competition solutions.
5/15/2024

Large Language Models for Code Summarization
Bal'azs Szalontai, GergH{o} Szalay, Tam'as M'arton, Anna Sike, Bal'azs Pint'er, Tibor Gregorics
0
0
Recently, there has been increasing activity in using deep learning for software engineering, including tasks like code generation and summarization. In particular, the most recent coding Large Language Models seem to perform well on these problems. In this technical report, we aim to review how these models perform in code explanation/summarization, while also investigating their code generation capabilities (based on natural language descriptions).
5/30/2024
💬
Investigating the translation capabilities of Large Language Models trained on parallel data only
Javier Garc'ia Gilabert, Carlos Escolano, Aleix Sant Savall, Francesca De Luca Fornaciari, Audrey Mash, Xixian Liao, Maite Melero
0
0
In recent years, Large Language Models (LLMs) have demonstrated exceptional proficiency across a broad spectrum of Natural Language Processing (NLP) tasks, including Machine Translation. However, previous methods predominantly relied on iterative processes such as instruction fine-tuning or continual pre-training, leaving unexplored the challenges of training LLMs solely on parallel data. In this work, we introduce PLUME (Parallel Language Model), a collection of three 2B LLMs featuring varying vocabulary sizes (32k, 128k, and 256k) trained exclusively on Catalan-centric parallel examples. These models perform comparably to previous encoder-decoder architectures on 16 supervised translation directions and 56 zero-shot ones. Utilizing this set of models, we conduct a thorough investigation into the translation capabilities of LLMs, probing their performance, the impact of the different elements of the prompt, and their cross-lingual representation space.
6/14/2024
💬
Evaluation of the Programming Skills of Large Language Models
Luc Bryan Heitz, Joun Chamas, Christopher Scherb
0
0
The advent of Large Language Models (LLM) has revolutionized the efficiency and speed with which tasks are completed, marking a significant leap in productivity through technological innovation. As these chatbots tackle increasingly complex tasks, the challenge of assessing the quality of their outputs has become paramount. This paper critically examines the output quality of two leading LLMs, OpenAI's ChatGPT and Google's Gemini AI, by comparing the quality of programming code generated in both their free versions. Through the lens of a real-world example coupled with a systematic dataset, we investigate the code quality produced by these LLMs. Given their notable proficiency in code generation, this aspect of chatbot capability presents a particularly compelling area for analysis. Furthermore, the complexity of programming code often escalates to levels where its verification becomes a formidable task, underscoring the importance of our study. This research aims to shed light on the efficacy and reliability of LLMs in generating high-quality programming code, an endeavor that has significant implications for the field of software development and beyond.
5/24/2024