HPT++: Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling

0
Sign in to get full access
Overview
- Proposes a new hierarchical prompting technique called HPT++ for vision-language models
- Generates multi-granularity knowledge and improves structure modeling
- Outperforms previous prompting approaches on a range of tasks
Plain English Explanation
This research paper introduces a new technique called HPT++ (Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling) for improving the performance of vision-language models on various tasks.
The key idea is to use a hierarchical prompting approach that generates knowledge at multiple levels of granularity and also better models the underlying structure of the task. This allows the model to draw upon a richer set of information and learn more effective representations compared to previous prompting techniques.
The hierarchical prompting involves using a series of prompts at different levels, such as high-level concepts, mid-level attributes, and low-level details. This multi-granularity knowledge generation is combined with improved structure modeling to capture the relationships between different elements of the task.
Overall, the HPT++ approach is shown to outperform previous prompting methods on a range of vision-language benchmarks, demonstrating the benefits of this more sophisticated prompting technique.
Technical Explanation
The paper proposes a Hierarchical Prompting Technique called HPT++ that generates knowledge at multiple levels of granularity and also better models the underlying structure of the task.
The hierarchical prompting involves using a series of prompts at different levels:
- High-level Concepts: These prompts capture broad, high-level information about the task.
- Mid-level Attributes: These prompts target more specific, mid-level attributes relevant to the task.
- Low-level Details: These prompts focus on capturing granular, low-level details.
By generating knowledge at these multiple levels of granularity, the model can draw upon a richer set of information to solve the task.
In addition, the paper also introduces improved structure modeling techniques to better capture the relationships between the different elements of the task. This allows the model to learn more effective representations compared to previous prompting approaches.
The experiments show that the HPT++ approach outperforms previous prompting methods on a range of vision-language benchmarks, including image captioning, visual question answering, and multi-modal attribute prediction.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the HPT++ technique, comparing it to state-of-the-art prompting approaches across a diverse range of vision-language tasks.
One potential limitation is that the paper does not delve into the specific architectural details or training procedures of the underlying vision-language model used. This makes it harder to assess how generalizable the HPT++ technique might be to other model architectures or training regimes.
Additionally, the paper does not address potential issues around the scalability of the hierarchical prompting approach, especially as the number of prompts and levels of granularity increase. There may be practical limitations in terms of prompt engineering and computational cost that could hinder the real-world applicability of this technique.
Further research could explore ways to automate or optimize the process of designing the hierarchical prompts, as well as investigate the tradeoffs between the benefits of multi-granularity knowledge generation and the increased complexity of the prompting system.
Conclusion
The HPT++ technique proposed in this paper represents a significant advancement in the field of vision-language modeling by introducing a hierarchical prompting approach that generates knowledge at multiple levels of granularity and improves the underlying structure modeling.
The empirical results demonstrate the effectiveness of this approach in outperforming previous prompting methods across a range of tasks. This suggests that the HPT++ technique could have far-reaching implications for building more capable and versatile vision-language models that can better understand and interact with the world around them.
As the research community continues to push the boundaries of what is possible with large language models, the insights and techniques presented in this paper will likely serve as an important foundation for further advancements in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HPT++: Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling
Yubin Wang, Xinyang Jiang, De Cheng, Wenli Sun, Dongsheng Li, Cairong Zhao
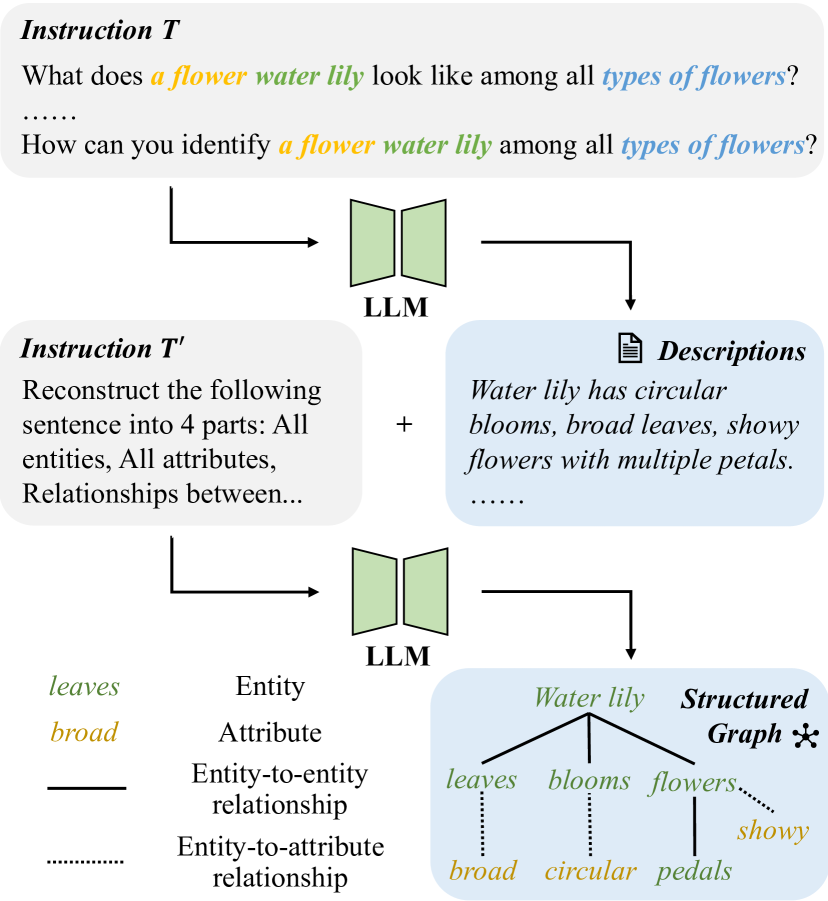
Prompt learning has become a prevalent strategy for adapting vision-language foundation models (VLMs) such as CLIP to downstream tasks. With the emergence of large language models (LLMs), recent studies have explored the potential of using category-related descriptions to enhance prompt effectiveness. However, conventional descriptions lack explicit structured information necessary to represent the interconnections among key elements like entities or attributes with relation to a particular category. Since existing prompt tuning methods give little consideration to managing structured knowledge, this paper advocates leveraging LLMs to construct a graph for each description to prioritize such structured knowledge. Consequently, we propose a novel approach called Hierarchical Prompt Tuning (HPT), enabling simultaneous modeling of both structured and conventional linguistic knowledge. Specifically, we introduce a relationship-guided attention module to capture pair-wise associations among entities and attributes for low-level prompt learning. In addition, by incorporating high-level and global-level prompts modeling overall semantics, the proposed hierarchical structure forges cross-level interlinks and empowers the model to handle more complex and long-term relationships. Finally, by enhancing multi-granularity knowledge generation, redesigning the relationship-driven attention re-weighting module, and incorporating consistent constraints on the hierarchical text encoder, we propose HPT++, which further improves the performance of HPT. Our experiments are conducted across a wide range of evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization. Extensive results and ablation studies demonstrate the effectiveness of our methods, which consistently outperform existing SOTA methods.
Read more8/28/2024
0
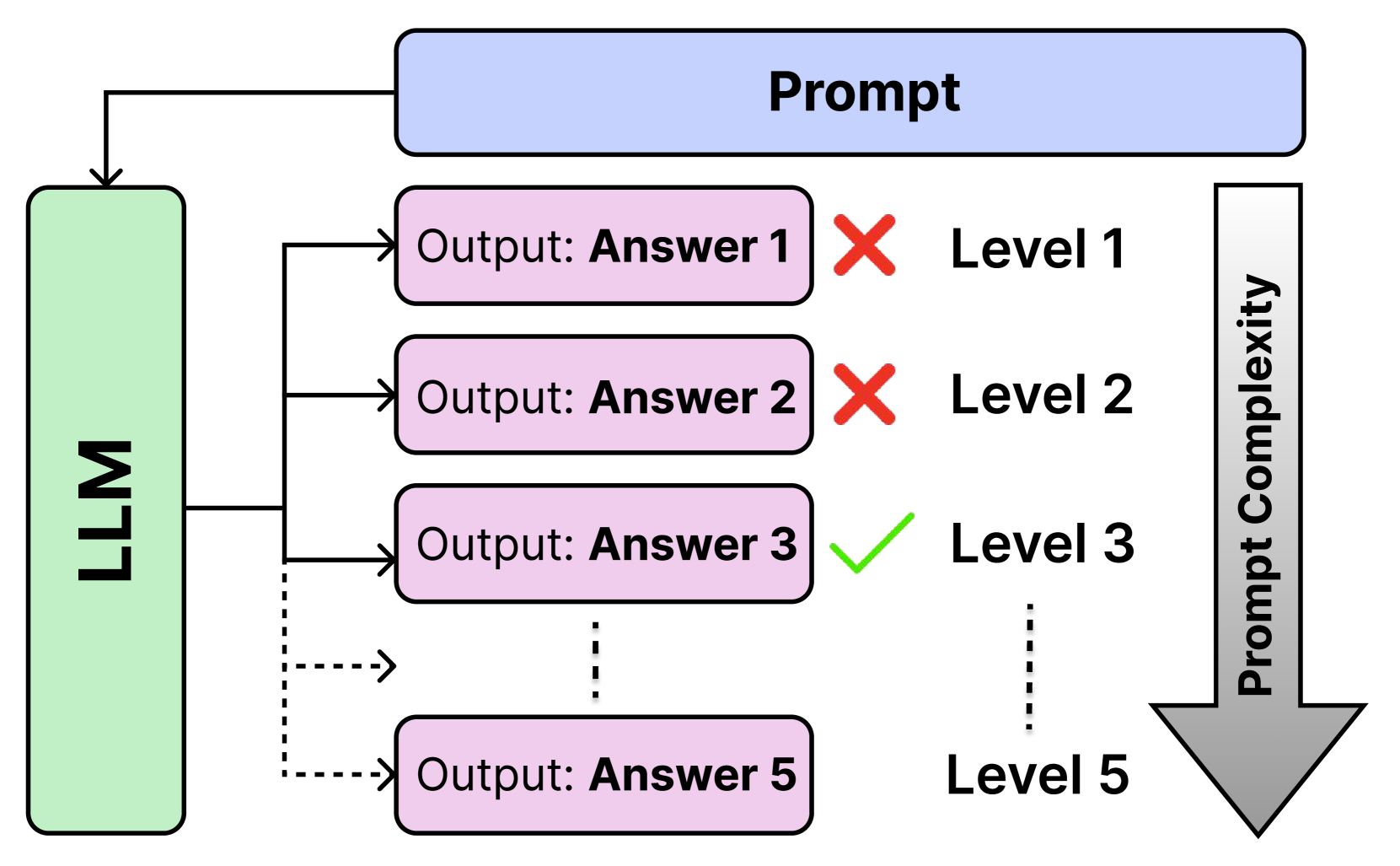
Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models
Devichand Budagam, Sankalp KJ, Ashutosh Kumar, Vinija Jain, Aman Chadha
Assessing the effectiveness of large language models (LLMs) in addressing diverse tasks is essential for comprehending their strengths and weaknesses. Conventional evaluation techniques typically apply a single prompting strategy uniformly across datasets, not considering the varying degrees of task complexity. We introduce the Hierarchical Prompting Taxonomy (HPT), a taxonomy that employs a Hierarchical Prompt Framework (HPF) composed of five unique prompting strategies, arranged from the simplest to the most complex, to assess LLMs more precisely and to offer a clearer perspective. This taxonomy assigns a score, called the Hierarchical Prompting Score (HP-Score), to datasets as well as LLMs based on the rules of the taxonomy, providing a nuanced understanding of their ability to solve diverse tasks and offering a universal measure of task complexity. Additionally, we introduce the Adaptive Hierarchical Prompt framework, which automates the selection of appropriate prompting strategies for each task. This study compares manual and adaptive hierarchical prompt frameworks using four instruction-tuned LLMs, namely Llama 3 8B, Phi 3 3.8B, Mistral 7B, and Gemma 7B, across four datasets: BoolQ, CommonSenseQA (CSQA), IWSLT-2017 en-fr (IWSLT), and SamSum. Experiments demonstrate the effectiveness of HPT, providing a reliable way to compare different tasks and LLM capabilities. This paper leads to the development of a universal evaluation metric that can be used to evaluate both the complexity of the datasets and the capabilities of LLMs. The implementation of both manual HPF and adaptive HPF is publicly available.
Read more6/28/2024
👀
0
Patch-Prompt Aligned Bayesian Prompt Tuning for Vision-Language Models
Xinyang Liu, Dongsheng Wang, Bowei Fang, Miaoge Li, Zhibin Duan, Yishi Xu, Bo Chen, Mingyuan Zhou
For downstream applications of vision-language pre-trained models, there has been significant interest in constructing effective prompts. Existing works on prompt engineering, which either require laborious manual designs or optimize the prompt tuning as a point estimation problem, may fail to describe diverse characteristics of categories and limit their applications. We introduce a Bayesian probabilistic resolution to prompt tuning, where the label-specific stochastic prompts are generated hierarchically by first sampling a latent vector from an underlying distribution and then employing a lightweight generative model. Importantly, we semantically regularize the tuning process by minimizing the statistical distance between the visual patches and linguistic prompts, which pushes the stochastic label representations to faithfully capture diverse visual concepts, instead of overfitting the training categories. We evaluate the effectiveness of our approach on four tasks: few-shot image recognition, base-to-new generalization, dataset transfer learning, and domain shifts. Extensive results over 15 datasets show promising transferability and generalization performance of our proposed model, both quantitatively and qualitatively.
Read more7/2/2024

0
Revisiting Prompt Pretraining of Vision-Language Models
Zhenyuan Chen, Lingfeng Yang, Shuo Chen, Zhaowei Chen, Jiajun Liang, Xiang Li
Prompt learning is an effective method to customize Vision-Language Models (VLMs) for various downstream tasks, involving tuning very few parameters of input prompt tokens. Recently, prompt pretraining in large-scale dataset (e.g., ImageNet-21K) has played a crucial role in prompt learning for universal visual discrimination. However, we revisit and observe that the limited learnable prompts could face underfitting risks given the extensive images during prompt pretraining, simultaneously leading to poor generalization. To address the above issues, in this paper, we propose a general framework termed Revisiting Prompt Pretraining (RPP), which targets at improving the fitting and generalization ability from two aspects: prompt structure and prompt supervision. For prompt structure, we break the restriction in common practice where query, key, and value vectors are derived from the shared learnable prompt token. Instead, we introduce unshared individual query, key, and value learnable prompts, thereby enhancing the model's fitting capacity through increased parameter diversity. For prompt supervision, we additionally utilize soft labels derived from zero-shot probability predictions provided by a pretrained Contrastive Language Image Pretraining (CLIP) teacher model. These soft labels yield more nuanced and general insights into the inter-class relationships, thereby endowing the pretraining process with better generalization ability. RPP produces a more resilient prompt initialization, enhancing its robust transferability across diverse visual recognition tasks. Experiments across various benchmarks consistently confirm the state-of-the-art (SOTA) performance of our pretrained prompts. Codes and models will be made available soon.
Read more9/11/2024