Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models

0
Sign in to get full access
Overview
- Presents a hierarchical prompting taxonomy for evaluating large language models (LLMs)
- Aims to provide a universal framework for assessing LLM capabilities across a wide range of tasks
- Introduces a hierarchical structure to organize prompting tasks, capturing different levels of complexity
Plain English Explanation
The paper introduces a hierarchical prompting taxonomy as a way to evaluate the capabilities of large language models (LLMs). The goal is to create a standardized framework that can assess how well these models perform on a diverse set of tasks.
The key idea is to organize prompting tasks into a hierarchical structure, with different levels of complexity. At the lowest level, there are basic tasks like answering questions or generating text. As you move up the hierarchy, the tasks become more sophisticated, such as engaging in multi-step reasoning or combining multiple skills to solve a problem.
By testing LLMs across this hierarchical taxonomy, researchers can gain a more comprehensive understanding of the models' strengths and limitations. This could help guide the development of more capable and well-rounded language models in the future.
Technical Explanation
The paper proposes a hierarchical prompting taxonomy as a framework for evaluating large language models (LLMs). The taxonomy organizes prompting tasks into a hierarchical structure, with four main levels:
- Elementary Tasks: Basic operations like answering questions, generating text, or performing simple logical reasoning.
- Composed Tasks: Combinations of elementary tasks, requiring the model to coordinate multiple skills.
- Relational Tasks: Tasks that involve understanding relationships between entities or concepts, such as analogical reasoning or commonsense inference.
- Multistep Tasks: Complex, multi-stage problems that require the model to plan, reason, and execute a sequence of steps to reach the final solution.
The authors argue that this hierarchical structure captures different levels of task complexity, allowing for a more comprehensive evaluation of LLM capabilities. They demonstrate the use of this taxonomy on several language models, highlighting their strengths and weaknesses across the various task levels.
Critical Analysis
The hierarchical prompting taxonomy proposed in this paper provides a valuable framework for evaluating LLMs. By structuring tasks in a hierarchical manner, it allows researchers to assess model performance across a wide range of complexity levels, revealing both the capabilities and limitations of these language models.
One potential limitation is that the taxonomy may not capture all the nuances of task complexity. The authors acknowledge that the task categories are not mutually exclusive, and some tasks may span multiple levels of the hierarchy. Additionally, the specific task examples used to populate the taxonomy may not be exhaustive, and the evaluation results may be sensitive to the choice of tasks.
Further research could explore ways to refine the taxonomy, potentially incorporating task features beyond just complexity, such as reasoning style, knowledge requirements, or multi-modal integration. Applying the taxonomy to a broader set of language models, including specialized or domain-specific ones, could also provide valuable insights.
Conclusion
The hierarchical prompting taxonomy presented in this paper offers a comprehensive framework for evaluating the capabilities of large language models. By organizing prompting tasks into a hierarchical structure, it allows researchers to assess LLM performance across different levels of complexity, providing a more nuanced understanding of their strengths and weaknesses.
This framework has the potential to guide the development of more capable and well-rounded language models, as it can help identify areas where models excel or struggle. Additionally, the taxonomy could be applied to other AI systems, such as multimodal or multi-agent models, to expand its utility and impact on the broader field of artificial intelligence research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models
Devichand Budagam, Sankalp KJ, Ashutosh Kumar, Vinija Jain, Aman Chadha
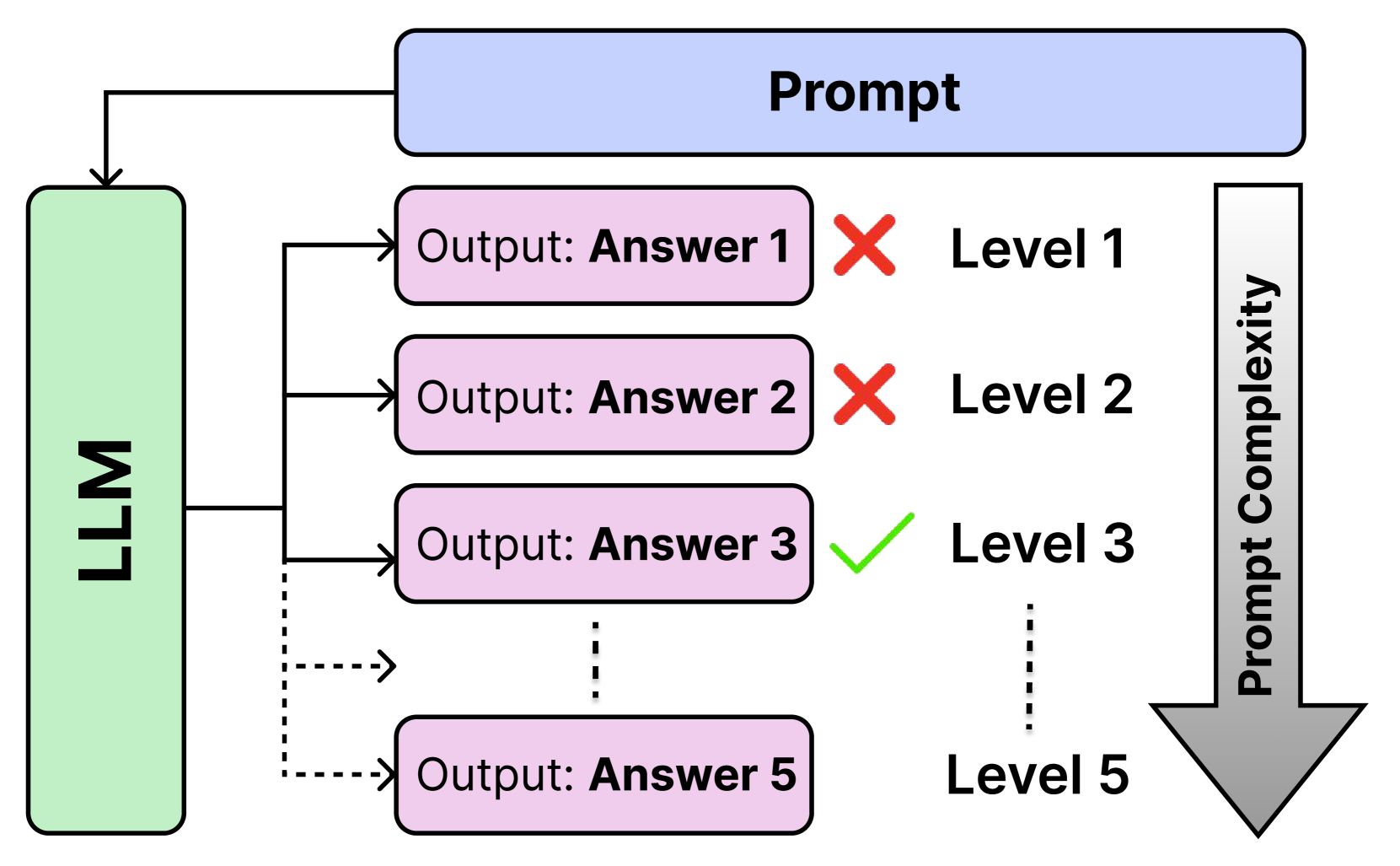
Assessing the effectiveness of large language models (LLMs) in addressing diverse tasks is essential for comprehending their strengths and weaknesses. Conventional evaluation techniques typically apply a single prompting strategy uniformly across datasets, not considering the varying degrees of task complexity. We introduce the Hierarchical Prompting Taxonomy (HPT), a taxonomy that employs a Hierarchical Prompt Framework (HPF) composed of five unique prompting strategies, arranged from the simplest to the most complex, to assess LLMs more precisely and to offer a clearer perspective. This taxonomy assigns a score, called the Hierarchical Prompting Score (HP-Score), to datasets as well as LLMs based on the rules of the taxonomy, providing a nuanced understanding of their ability to solve diverse tasks and offering a universal measure of task complexity. Additionally, we introduce the Adaptive Hierarchical Prompt framework, which automates the selection of appropriate prompting strategies for each task. This study compares manual and adaptive hierarchical prompt frameworks using four instruction-tuned LLMs, namely Llama 3 8B, Phi 3 3.8B, Mistral 7B, and Gemma 7B, across four datasets: BoolQ, CommonSenseQA (CSQA), IWSLT-2017 en-fr (IWSLT), and SamSum. Experiments demonstrate the effectiveness of HPT, providing a reliable way to compare different tasks and LLM capabilities. This paper leads to the development of a universal evaluation metric that can be used to evaluate both the complexity of the datasets and the capabilities of LLMs. The implementation of both manual HPF and adaptive HPF is publicly available.
Read more6/28/2024
0
HPT++: Hierarchically Prompting Vision-Language Models with Multi-Granularity Knowledge Generation and Improved Structure Modeling
Yubin Wang, Xinyang Jiang, De Cheng, Wenli Sun, Dongsheng Li, Cairong Zhao
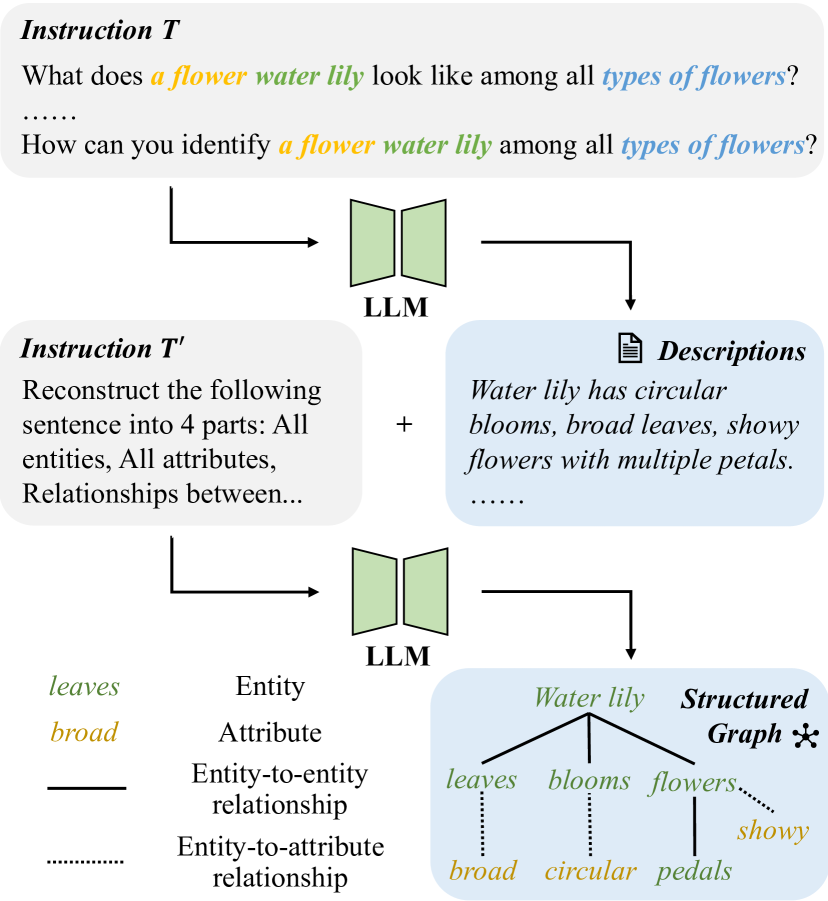
Prompt learning has become a prevalent strategy for adapting vision-language foundation models (VLMs) such as CLIP to downstream tasks. With the emergence of large language models (LLMs), recent studies have explored the potential of using category-related descriptions to enhance prompt effectiveness. However, conventional descriptions lack explicit structured information necessary to represent the interconnections among key elements like entities or attributes with relation to a particular category. Since existing prompt tuning methods give little consideration to managing structured knowledge, this paper advocates leveraging LLMs to construct a graph for each description to prioritize such structured knowledge. Consequently, we propose a novel approach called Hierarchical Prompt Tuning (HPT), enabling simultaneous modeling of both structured and conventional linguistic knowledge. Specifically, we introduce a relationship-guided attention module to capture pair-wise associations among entities and attributes for low-level prompt learning. In addition, by incorporating high-level and global-level prompts modeling overall semantics, the proposed hierarchical structure forges cross-level interlinks and empowers the model to handle more complex and long-term relationships. Finally, by enhancing multi-granularity knowledge generation, redesigning the relationship-driven attention re-weighting module, and incorporating consistent constraints on the hierarchical text encoder, we propose HPT++, which further improves the performance of HPT. Our experiments are conducted across a wide range of evaluation settings, including base-to-new generalization, cross-dataset evaluation, and domain generalization. Extensive results and ablation studies demonstrate the effectiveness of our methods, which consistently outperform existing SOTA methods.
Read more8/28/2024
0
Prompt Recursive Search: A Living Framework with Adaptive Growth in LLM Auto-Prompting
Xiangyu Zhao, Chengqian Ma
Large Language Models (LLMs) exhibit remarkable proficiency in addressing a diverse array of tasks within the Natural Language Processing (NLP) domain, with various prompt design strategies significantly augmenting their capabilities. However, these prompts, while beneficial, each possess inherent limitations. The primary prompt design methodologies are twofold: The first, exemplified by the Chain of Thought (CoT), involves manually crafting prompts specific to individual datasets, hence termed Expert-Designed Prompts (EDPs). Once these prompts are established, they are unalterable, and their effectiveness is capped by the expertise of the human designers. When applied to LLMs, the static nature of EDPs results in a uniform approach to both simple and complex problems within the same dataset, leading to the inefficient use of tokens for straightforward issues. The second method involves prompts autonomously generated by the LLM, known as LLM-Derived Prompts (LDPs), which provide tailored solutions to specific problems, mitigating the limitations of EDPs. However, LDPs may encounter a decline in performance when tackling complex problems due to the potential for error accumulation during the solution planning process. To address these challenges, we have conceived a novel Prompt Recursive Search (PRS) framework that leverages the LLM to generate solutions specific to the problem, thereby conserving tokens. The framework incorporates an assessment of problem complexity and an adjustable structure, ensuring a reduction in the likelihood of errors. We have substantiated the efficacy of PRS framework through extensive experiments using LLMs with different numbers of parameters across a spectrum of datasets in various domains. Compared to the CoT method, the PRS method has increased the accuracy on the BBH dataset by 8% using Llama3-7B model, achieving a 22% improvement.
Read more8/6/2024
0
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
Yuchi Liu, Jaskirat Singh, Gaowen Liu, Ali Payani, Liang Zheng
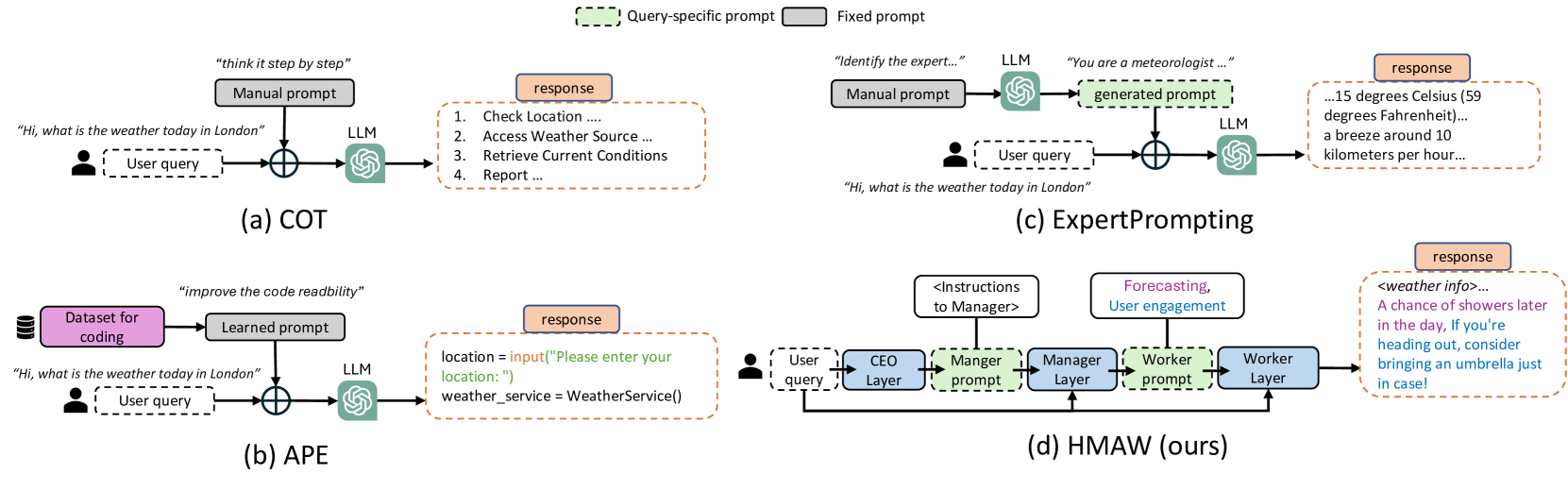
Large language models (LLMs) have shown great progress in responding to user questions, allowing for a multitude of diverse applications. Yet, the quality of LLM outputs heavily depends on the prompt design, where a good prompt might enable the LLM to answer a very challenging question correctly. Therefore, recent works have developed many strategies for improving the prompt, including both manual crafting and in-domain optimization. However, their efficacy in unrestricted scenarios remains questionable, as the former depends on human design for specific questions and the latter usually generalizes poorly to unseen scenarios. To address these problems, we give LLMs the freedom to design the best prompts according to themselves. Specifically, we include a hierarchy of LLMs, first constructing a prompt with precise instructions and accurate wording in a hierarchical manner, and then using this prompt to generate the final answer to the user query. We term this pipeline Hierarchical Multi-Agent Workflow, or HMAW. In contrast with prior works, HMAW imposes no human restriction and requires no training, and is completely task-agnostic while capable of adjusting to the nuances of the underlying task. Through both quantitative and qualitative experiments across multiple benchmarks, we verify that despite its simplicity, the proposed approach can create detailed and suitable prompts, further boosting the performance of current LLMs.
Read more5/31/2024