HSFusion: A high-level vision task-driven infrared and visible image fusion network via semantic and geometric domain transformation

0

Sign in to get full access
Overview
- Proposes a high-level vision task-driven infrared and visible image fusion network called HSFusion
- Uses semantic and geometric domain transformation to fuse infrared and visible images
- Aims to improve performance on high-level vision tasks like semantic segmentation and object detection
Plain English Explanation
The paper introduces a new approach called HSFusion for combining infrared and visible light images. Infrared cameras can see heat signatures, while visible light cameras capture color and detail. By fusing these two types of information, HSFusion aims to create a more comprehensive understanding of a scene.
The key innovation is the use of "semantic and geometric domain transformation." This means the system tries to understand the meaningful content and spatial relationships in the input images, not just blend the raw pixel data. For example, it might identify that a certain region corresponds to a person or building, and then use that high-level understanding to guide the fusion process.
The goal is to improve performance on advanced computer vision tasks like semantic segmentation and object detection, which could be useful for applications like autonomous driving, surveillance, and search and rescue. By fusing the complementary strengths of infrared and visible light, HSFusion aims to create a more reliable and informative representation of the environment.
Technical Explanation
The HSFusion network takes in an infrared image and a visible light image, and produces a fused output that can be used for high-level vision tasks. The key components are:
-
Semantic Transformation: The input images are passed through separate convolutional neural network backbones to extract semantic features. This allows the system to understand the semantic content of the scene, like the locations of objects, people, and buildings.
-
Geometric Transformation: The network also extracts geometric features from the inputs, modeling the spatial relationships and structures in the scene. This complements the semantic understanding.
-
Feature Fusion: The semantic and geometric features are then fused together using attention mechanisms. This allows the network to selectively combine the most relevant information from the two modalities.
-
Task-Specific Heads: The fused features are fed into task-specific output heads, such as for semantic segmentation or object detection. This ensures the fusion is optimized for the desired high-level vision application.
The authors evaluate HSFusion on several benchmark datasets, showing improved performance compared to previous image fusion methods like SimpleFusion, CoMoFusion, and AHDGAN. The results demonstrate the benefits of the semantic and geometric transformations for high-level vision tasks.
Critical Analysis
The paper presents a well-designed and comprehensive approach to infrared-visible image fusion. The use of semantic and geometric transformations is a clever way to go beyond simple pixel-level blending and leverage high-level understanding of the scene.
However, one potential limitation is the computational complexity of the network, which may make it challenging to deploy in real-time applications. The authors don't provide detailed performance metrics like inference time or memory usage.
Additionally, the paper focuses on evaluating HSFusion on standard benchmarks, but doesn't explore how it might perform in more diverse or challenging real-world scenarios. Further research could investigate the robustness of the approach to factors like varying environmental conditions, sensor noise, or occlusions.
It would also be interesting to see how HSFusion compares to more recent state-of-the-art fusion models that also leverage advanced techniques like saliency detection and attention mechanisms.
Overall, the HSFusion approach represents a promising step forward in leveraging the complementary strengths of infrared and visible imagery for high-level vision tasks. Continued research and development in this area could lead to significant advancements in a wide range of applications.
Conclusion
The HSFusion paper proposes a novel infrared-visible image fusion network that uses semantic and geometric domain transformations to improve performance on high-level computer vision tasks. By going beyond simple pixel-level blending and instead modeling the meaningful content and spatial relationships in the input images, HSFusion demonstrates superior results compared to previous fusion methods.
While the computational complexity of the network may limit its real-time applicability, the core concepts introduced in this work represent an important advancement in multimodal perception. Further research building on these ideas could lead to even more robust and capable computer vision systems, with far-reaching implications for applications like autonomous vehicles, security, and environmental monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HSFusion: A high-level vision task-driven infrared and visible image fusion network via semantic and geometric domain transformation
Chengjie Jiang, Xiaowen Liu, Bowen Zheng, Lu Bai, Jing Li
Infrared and visible image fusion has been developed from vision perception oriented fusion methods to strategies which both consider the vision perception and high-level vision task. However, the existing task-driven methods fail to address the domain gap between semantic and geometric representation. To overcome these issues, we propose a high-level vision task-driven infrared and visible image fusion network via semantic and geometric domain transformation, terms as HSFusion. Specifically, to minimize the gap between semantic and geometric representation, we design two separate domain transformation branches by CycleGAN framework, and each includes two processes: the forward segmentation process and the reverse reconstruction process. CycleGAN is capable of learning domain transformation patterns, and the reconstruction process of CycleGAN is conducted under the constraint of these patterns. Thus, our method can significantly facilitate the integration of semantic and geometric information and further reduces the domain gap. In fusion stage, we integrate the infrared and visible features that extracted from the reconstruction process of two seperate CycleGANs to obtain the fused result. These features, containing varying proportions of semantic and geometric information, can significantly enhance the high level vision tasks. Additionally, we generate masks based on segmentation results to guide the fusion task. These masks can provide semantic priors, and we design adaptive weights for two distinct areas in the masks to facilitate image fusion. Finally, we conducted comparative experiments between our method and eleven other state-of-the-art methods, demonstrating that our approach surpasses others in both visual appeal and semantic segmentation task.
Read more7/16/2024
🖼️
0
New!Infrared and Visible Image Fusion with Hierarchical Human Perception
Guang Yang, Jie Li, Xin Liu, Zhusi Zhong, Xinbo Gao
Image fusion combines images from multiple domains into one image, containing complementary information from source domains. Existing methods take pixel intensity, texture and high-level vision task information as the standards to determine preservation of information, lacking enhancement for human perception. We introduce an image fusion method, Hierarchical Perception Fusion (HPFusion), which leverages Large Vision-Language Model to incorporate hierarchical human semantic priors, preserving complementary information that satisfies human visual system. We propose multiple questions that humans focus on when viewing an image pair, and answers are generated via the Large Vision-Language Model according to images. The texts of answers are encoded into the fusion network, and the optimization also aims to guide the human semantic distribution of the fused image more similarly to source images, exploring complementary information within the human perception domain. Extensive experiments demonstrate our HPFusoin can achieve high-quality fusion results both for information preservation and human visual enhancement.
Read more9/17/2024
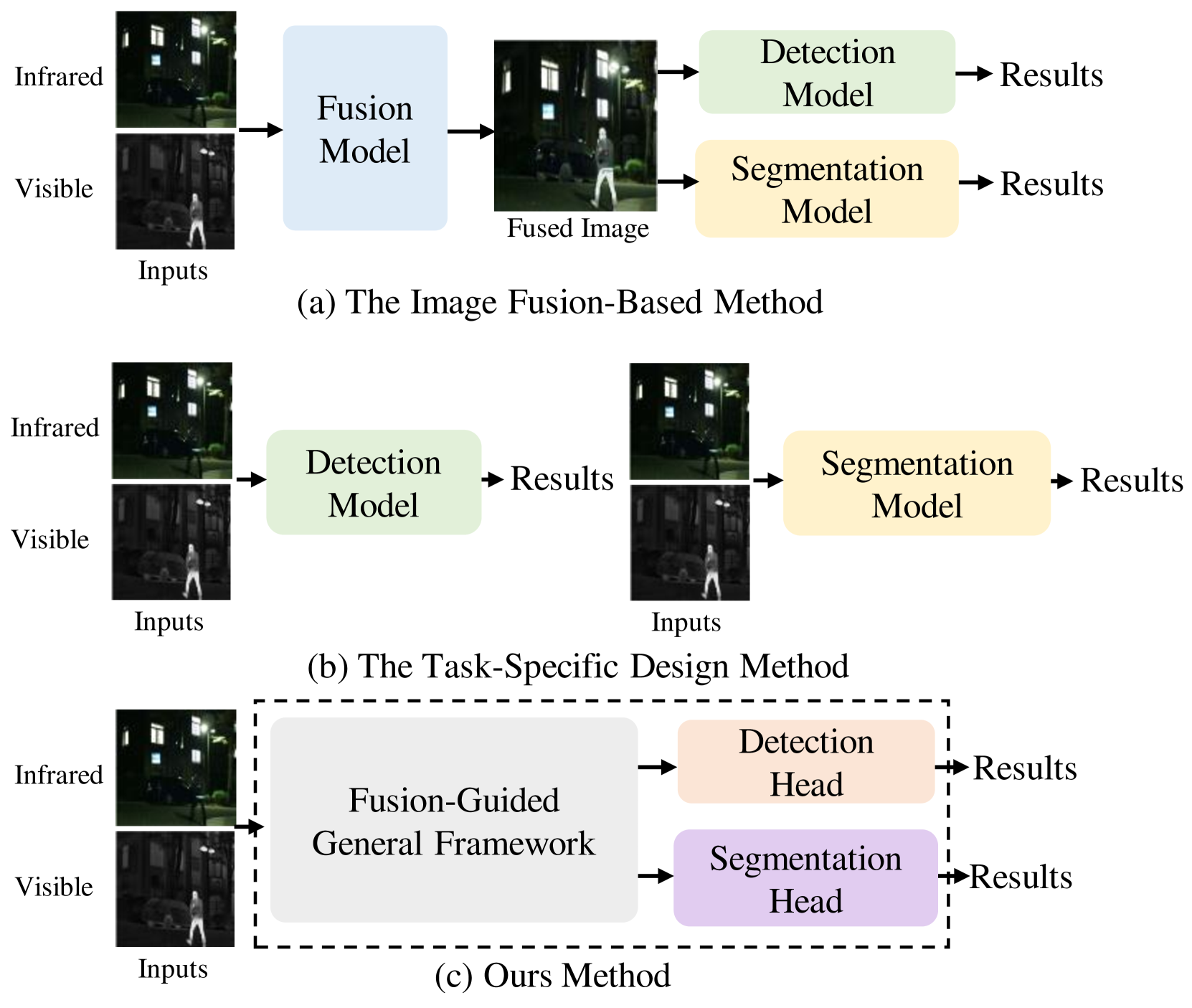
0
IVGF: The Fusion-Guided Infrared and Visible General Framework
Fangcen Liu, Chenqiang Gao, Fang Chen, Pengcheng Li, Junjie Guo, Deyu Meng
Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
Read more9/17/2024

0
A Semantic-Aware and Multi-Guided Network for Infrared-Visible Image Fusion
Xiaoli Zhang, Liying Wang, Libo Zhao, Xiongfei Li, Siwei Ma
Multi-modality image fusion aims at fusing specific-modality and shared-modality information from two source images. To tackle the problem of insufficient feature extraction and lack of semantic awareness for complex scenes, this paper focuses on how to model correlation-driven decomposing features and reason high-level graph representation by efficiently extracting complementary features and multi-guided feature aggregation. We propose a three-branch encoder-decoder architecture along with corresponding fusion layers as the fusion strategy. The transformer with Multi-Dconv Transposed Attention and Local-enhanced Feed Forward network is used to extract shallow features after the depthwise convolution. In the three parallel branches encoder, Cross Attention and Invertible Block (CAI) enables to extract local features and preserve high-frequency texture details. Base feature extraction module (BFE) with residual connections can capture long-range dependency and enhance shared-modality expression capabilities. Graph Reasoning Module (GR) is introduced to reason high-level cross-modality relations and extract low-level details features as CAI's specific-modality complementary information simultaneously. Experiments demonstrate that our method has obtained competitive results compared with state-of-the-art methods in visible/infrared image fusion and medical image fusion tasks. Moreover, we surpass other fusion methods in terms of subsequent tasks, averagely scoring 9.78% [email protected] higher in object detection and 6.46% mIoU higher in semantic segmentation.
Read more7/9/2024