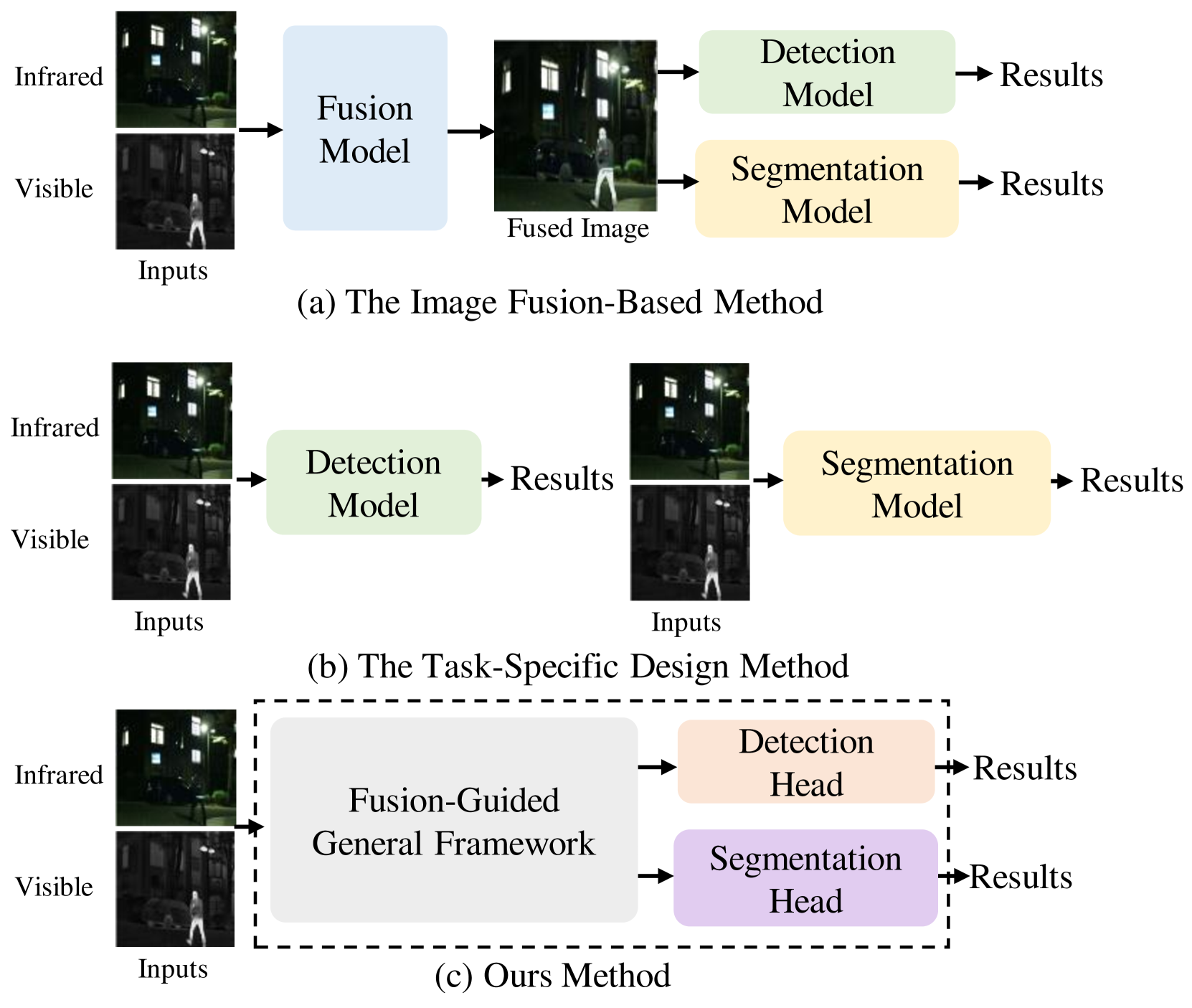
IVGF: The Fusion-Guided Infrared and Visible General Framework

0
Sign in to get full access
Overview
- The paper introduces the Infrared and Visible General Framework (IVGF), a fusion-guided framework for dual-modality semantic segmentation and object detection tasks.
- IVGF combines infrared (IR) and visible (VIS) image data to leverage the complementary strengths of both modalities.
- The framework includes a fusion module that guides the feature extraction and fusion process to effectively integrate IR and VIS information.
Plain English Explanation
The IVGF: The Fusion-Guided Infrared and Visible General Framework paper presents a new approach for combining infrared (IR) and visible (VIS) camera data to improve performance on computer vision tasks like semantic segmentation and object detection.
The key insight is that IR and VIS images contain complementary information - IR cameras are good at detecting heat signatures, while VIS cameras capture visual details. By fusing the data from both modalities, the framework can leverage the strengths of each to get more accurate results.
The fusion module in IVGF is designed to intelligently combine the IR and VIS features in a way that prioritizes the most relevant information for the task at hand. This helps the system focus on the important details and avoid getting confused by irrelevant data.
Overall, IVGF provides a general-purpose way to take advantage of dual-modality data sources, which could be useful in a variety of computer vision applications where both thermal and visual information is important, such as autonomous vehicles or surveillance systems.
Technical Explanation
The IVGF framework consists of several key components:
-
Dual-Modality Feature Extraction: IVGF takes in corresponding IR and VIS image pairs and extracts features from each modality using separate backbone networks.
-
Fusion Module: A fusion module combines the IR and VIS features, guided by a learned fusion map that indicates the relative importance of each modality for the given task and input.
-
Task-Specific Heads: The fused features are then passed to task-specific heads for semantic segmentation, object detection, or other computer vision tasks.
The authors evaluate IVGF on several benchmark datasets for dual-modality semantic segmentation and object detection, demonstrating state-of-the-art performance compared to previous approaches.
Key insights from the technical analysis include:
- The fusion module is critical for effectively integrating the complementary IR and VIS features.
- Modality-aware feature weighting, guided by the learned fusion map, is important for achieving optimal performance.
- IVGF is a general framework that can be applied to various dual-modality computer vision tasks.
Critical Analysis
The IVGF paper provides a well-designed and thorough evaluation of the proposed framework, addressing several limitations of prior work in dual-modality vision tasks.
However, the authors acknowledge that IVGF still has some limitations:
- The framework assumes perfect spatial and temporal alignment between the IR and VIS images, which may not always be the case in real-world scenarios.
- The computational complexity of the fusion module could be a concern for deployment on resource-constrained platforms.
- The paper focuses on semantic segmentation and object detection, but the generalizability of IVGF to other computer vision tasks is not explored.
Potential areas for future research include:
- Developing techniques to handle misaligned or asynchronous IR and VIS data.
- Optimizing the fusion module for better efficiency without sacrificing performance.
- Investigating the application of IVGF to a broader range of computer vision problems beyond semantic segmentation and object detection.
Overall, the IVGF framework represents a promising step forward in leveraging the complementary strengths of IR and VIS data for advanced computer vision systems.
Conclusion
The IVGF: The Fusion-Guided Infrared and Visible General Framework paper introduces a novel approach for combining infrared and visible image data to improve the performance of semantic segmentation and object detection tasks. By using a specialized fusion module to effectively integrate the complementary information from both modalities, IVGF achieves state-of-the-art results on benchmark datasets.
While the framework has some limitations, such as the need for perfectly aligned IR and VIS data, the authors have demonstrated the value of their approach and opened up new avenues for research in dual-modality computer vision. As sensor technologies continue to advance, frameworks like IVGF could play an increasingly important role in enabling robust and capable vision systems for a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IVGF: The Fusion-Guided Infrared and Visible General Framework
Fangcen Liu, Chenqiang Gao, Fang Chen, Pengcheng Li, Junjie Guo, Deyu Meng
Infrared and visible dual-modality tasks such as semantic segmentation and object detection can achieve robust performance even in extreme scenes by fusing complementary information. Most current methods design task-specific frameworks, which are limited in generalization across multiple tasks. In this paper, we propose a fusion-guided infrared and visible general framework, IVGF, which can be easily extended to many high-level vision tasks. Firstly, we adopt the SOTA infrared and visible foundation models to extract the general representations. Then, to enrich the semantics information of these general representations for high-level vision tasks, we design the feature enhancement module and token enhancement module for feature maps and tokens, respectively. Besides, the attention-guided fusion module is proposed for effectively fusing by exploring the complementary information of two modalities. Moreover, we also adopt the cutout&mix augmentation strategy to conduct the data augmentation, which further improves the ability of the model to mine the regional complementary between the two modalities. Extensive experiments show that the IVGF outperforms state-of-the-art dual-modality methods in the semantic segmentation and object detection tasks. The detailed ablation studies demonstrate the effectiveness of each module, and another experiment explores the anti-missing modality ability of the proposed method in the dual-modality semantic segmentation task.
Read more9/17/2024

0
A Semantic-Aware and Multi-Guided Network for Infrared-Visible Image Fusion
Xiaoli Zhang, Liying Wang, Libo Zhao, Xiongfei Li, Siwei Ma
Multi-modality image fusion aims at fusing specific-modality and shared-modality information from two source images. To tackle the problem of insufficient feature extraction and lack of semantic awareness for complex scenes, this paper focuses on how to model correlation-driven decomposing features and reason high-level graph representation by efficiently extracting complementary features and multi-guided feature aggregation. We propose a three-branch encoder-decoder architecture along with corresponding fusion layers as the fusion strategy. The transformer with Multi-Dconv Transposed Attention and Local-enhanced Feed Forward network is used to extract shallow features after the depthwise convolution. In the three parallel branches encoder, Cross Attention and Invertible Block (CAI) enables to extract local features and preserve high-frequency texture details. Base feature extraction module (BFE) with residual connections can capture long-range dependency and enhance shared-modality expression capabilities. Graph Reasoning Module (GR) is introduced to reason high-level cross-modality relations and extract low-level details features as CAI's specific-modality complementary information simultaneously. Experiments demonstrate that our method has obtained competitive results compared with state-of-the-art methods in visible/infrared image fusion and medical image fusion tasks. Moreover, we surpass other fusion methods in terms of subsequent tasks, averagely scoring 9.78% [email protected] higher in object detection and 6.46% mIoU higher in semantic segmentation.
Read more7/9/2024

0
HSFusion: A high-level vision task-driven infrared and visible image fusion network via semantic and geometric domain transformation
Chengjie Jiang, Xiaowen Liu, Bowen Zheng, Lu Bai, Jing Li
Infrared and visible image fusion has been developed from vision perception oriented fusion methods to strategies which both consider the vision perception and high-level vision task. However, the existing task-driven methods fail to address the domain gap between semantic and geometric representation. To overcome these issues, we propose a high-level vision task-driven infrared and visible image fusion network via semantic and geometric domain transformation, terms as HSFusion. Specifically, to minimize the gap between semantic and geometric representation, we design two separate domain transformation branches by CycleGAN framework, and each includes two processes: the forward segmentation process and the reverse reconstruction process. CycleGAN is capable of learning domain transformation patterns, and the reconstruction process of CycleGAN is conducted under the constraint of these patterns. Thus, our method can significantly facilitate the integration of semantic and geometric information and further reduces the domain gap. In fusion stage, we integrate the infrared and visible features that extracted from the reconstruction process of two seperate CycleGANs to obtain the fused result. These features, containing varying proportions of semantic and geometric information, can significantly enhance the high level vision tasks. Additionally, we generate masks based on segmentation results to guide the fusion task. These masks can provide semantic priors, and we design adaptive weights for two distinct areas in the masks to facilitate image fusion. Finally, we conducted comparative experiments between our method and eleven other state-of-the-art methods, demonstrating that our approach surpasses others in both visual appeal and semantic segmentation task.
Read more7/16/2024

0
SimpleFusion: A Simple Fusion Framework for Infrared and Visible Images
Ming Chen, Yuxuan Cheng, Xinwei He, Xinyue Wang, Yan Aze, Jinhai Xiang
Integrating visible and infrared images into one high-quality image, also known as visible and infrared image fusion, is a challenging yet critical task for many downstream vision tasks. Most existing works utilize pretrained deep neural networks or design sophisticated frameworks with strong priors for this task, which may be unsuitable or lack flexibility. This paper presents SimpleFusion, a simple yet effective framework for visible and infrared image fusion. Our framework follows the decompose-and-fusion paradigm, where the visible and the infrared images are decomposed into reflectance and illumination components via Retinex theory and followed by the fusion of these corresponding elements. The whole framework is designed with two plain convolutional neural networks without downsampling, which can perform image decomposition and fusion efficiently. Moreover, we introduce decomposition loss and a detail-to-semantic loss to preserve the complementary information between the two modalities for fusion. We conduct extensive experiments on the challenging benchmarks, verifying the superiority of our method over previous state-of-the-arts. Code is available at href{https://github.com/hxwxss/SimpleFusion-A-Simple-Fusion-Framework-for-Infrared-and-Visible-Images}{https://github.com/hxwxss/SimpleFusion-A-Simple-Fusion-Framework-for-Infrared-and-Visible-Images}
Read more6/28/2024