Humane Speech Synthesis through Zero-Shot Emotion and Disfluency Generation
2404.01339
0
0

Abstract
Contemporary conversational systems often present a significant limitation: their responses lack the emotional depth and disfluent characteristic of human interactions. This absence becomes particularly noticeable when users seek more personalized and empathetic interactions. Consequently, this makes them seem mechanical and less relatable to human users. Recognizing this gap, we embarked on a journey to humanize machine communication, to ensure AI systems not only comprehend but also resonate. To address this shortcoming, we have designed an innovative speech synthesis pipeline. Within this framework, a cutting-edge language model introduces both human-like emotion and disfluencies in a zero-shot setting. These intricacies are seamlessly integrated into the generated text by the language model during text generation, allowing the system to mirror human speech patterns better, promoting more intuitive and natural user interactions. These generated elements are then adeptly transformed into corresponding speech patterns and emotive sounds using a rule-based approach during the text-to-speech phase. Based on our experiments, our novel system produces synthesized speech that's almost indistinguishable from genuine human communication, making each interaction feel more personal and authentic.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach to generating more human-like and expressive speech synthesis using zero-shot emotion and disfluency generation.
- The researchers developed a model that can add natural vocal cues like emotion and disfluencies (e.g., hesitations, fillers) to synthesized speech without requiring labeled training data.
- This allows for more natural-sounding and engaging speech synthesis, which could have applications in areas like virtual assistants, audio books, and video game characters.
Plain English Explanation
The researchers wanted to make speech synthesis - the process of generating artificial speech - sound more natural and human-like. Current speech synthesis systems can sound a bit robotic or flat, lacking the emotional expressiveness and natural imperfections that characterize human speech.
To address this, the researchers developed a new model that can add emotional tones and disfluencies (things like "um," "uh," pauses) to synthesized speech, even without having examples of that kind of speech in the training data. The idea is that by injecting these natural vocal cues, the synthesized speech will sound more engaging and life-like.
Imagine you're listening to an audiobook or talking to a virtual assistant. Normally, the voice might sound a bit monotone and mechanical. But with this new approach, the voice could convey subtle emotions like excitement or uncertainty, and include natural pauses and verbal fillers, making the experience feel more human and relatable.
This could be useful in all kinds of applications where we want synthesized speech to feel more natural and expressive, from educational materials to video game characters. It's a step toward making artificial voices sound less robotic and more personable.
Technical Explanation
The core of the researchers' approach is a generative model that can produce emotional and disfluent speech features without requiring labeled training data for those attributes. The model has two main components:
- An emotion encoder that can infer the emotional state (e.g., happy, sad, angry) from the input text and audio features.
- A disfluency generator that can add realistic vocal imperfections like hesitations, filled pauses, and self-corrections to the synthesized speech.
By combining these two components, the model can generate speech that not only conveys the appropriate emotional tone, but also includes natural-sounding disfluencies, even for input text that doesn't explicitly specify those attributes.
The researchers evaluated their model on several benchmarks and found that it outperformed previous approaches in terms of producing engaging and human-like synthesized speech. Listeners rated the speech as more natural, emotional, and varied compared to standard text-to-speech systems.
Critical Analysis
A key strength of this research is the ability to generate emotional and disfluent speech without relying on labeled training data, which can be difficult and expensive to acquire. This zero-shot approach makes the model more flexible and scalable.
However, the paper does not provide a detailed analysis of the specific emotions and disfluencies generated by the model. It would be helpful to understand the range and nuance of the emotional expressiveness and the types of disfluencies produced.
Additionally, the evaluation was conducted on relatively simple, controlled tasks. It's unclear how well the model would perform on more complex, real-world speech scenarios with varied content and contexts. Further testing in diverse application settings would help validate the model's robustness.
Overall, this is a promising step toward more human-like and engaging speech synthesis. Continuing to improve the versatility and realism of these generative models could lead to significant advancements in fields like virtual assistants, audiobooks, and interactive media.
Conclusion
This paper presents a novel approach to generating more natural and expressive speech synthesis by incorporating zero-shot emotion and disfluency modeling. The researchers developed a generative model that can add emotional tones and realistic vocal imperfections to synthesized speech, even without labeled training data for those attributes.
By injecting these human-like qualities, the model is able to produce speech that sounds more engaging and relatable compared to standard text-to-speech systems. This work represents an important step toward making artificial voices feel more personable and lifelike, with potential applications in a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
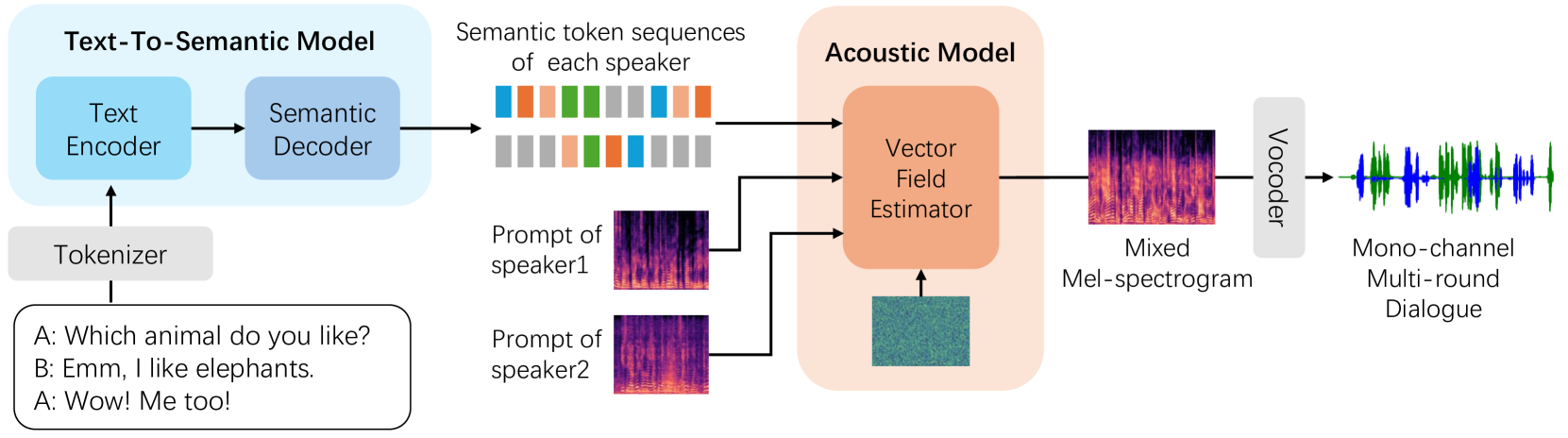
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Leying Zhang, Yao Qian, Long Zhou, Shujie Liu, Dongmei Wang, Xiaofei Wang, Midia Yousefi, Yanmin Qian, Jinyu Li, Lei He, Sheng Zhao, Michael Zeng
0
0
Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
4/11/2024
🗣️
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Weizhen Bian, Shulin He, Qifeng Liu, Yike Guo, Wei Xue
0
0
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
4/26/2024
Expressivity and Speech Synthesis
Andreas Triantafyllopoulos, Bjorn W. Schuller
0
0
Imbuing machines with the ability to talk has been a longtime pursuit of artificial intelligence (AI) research. From the very beginning, the community has not only aimed to synthesise high-fidelity speech that accurately conveys the semantic meaning of an utterance, but also to colour it with inflections that cover the same range of affective expressions that humans are capable of. After many years of research, it appears that we are on the cusp of achieving this when it comes to single, isolated utterances. This unveils an abundance of potential avenues to explore when it comes to combining these single utterances with the aim of synthesising more complex, longer-term behaviours. In the present chapter, we outline the methodological advances that brought us so far and sketch out the ongoing efforts to reach that coveted next level of artificial expressivity. We also discuss the societal implications coupled with rapidly advancing expressive speech synthesis (ESS) technology and highlight ways to mitigate those risks and ensure the alignment of ESS capabilities with ethical norms.
5/1/2024
🛸
Listen, Disentangle, and Control: Controllable Speech-Driven Talking Head Generation
Changpeng Cai, Guinan Guo, Jiao Li, Junhao Su, Chenghao He, Jing Xiao, Yuanxu Chen, Lei Dai, Feiyu Zhu
0
0
Most earlier investigations on talking face generation have focused on the synchronization of lip motion and speech content. However, human head pose and facial emotions are equally important characteristics of natural human faces. While audio-driven talking face generation has seen notable advancements, existing methods either overlook facial emotions or are limited to specific individuals and cannot be applied to arbitrary subjects. In this paper, we propose a one-shot Talking Head Generation framework (SPEAK) that distinguishes itself from general Talking Face Generation by enabling emotional and postural control. Specifically, we introduce the Inter-Reconstructed Feature Disentanglement (IRFD) method to decouple human facial features into three latent spaces. We then design a face editing module that modifies speech content and facial latent codes into a single latent space. Subsequently, we present a novel generator that employs modified latent codes derived from the editing module to regulate emotional expression, head poses, and speech content in synthesizing facial animations. Extensive trials demonstrate that our method can generate realistic talking head with coordinated lip motions, authentic facial emotions, and smooth head movements. The demo video is available at the anonymous link: https://anonymous.4open.science/r/SPEAK-F56E
5/14/2024