FlashSpeech: Efficient Zero-Shot Speech Synthesis
2404.14700
0
0
🗣️
Abstract
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Recent advancements in large-scale zero-shot speech synthesis have been driven by language models and diffusion models.
- However, the generation process of these methods is slow and computationally intensive.
- Efficiently generating high-quality speech with a lower computing budget remains a significant challenge.
- The paper presents FlashSpeech, a large-scale zero-shot speech synthesis system that is approximately 5% as slow as previous work.
Plain English Explanation
FlashSpeech is a new system that can generate high-quality speech without being trained on that specific speech before. This is called "zero-shot" speech synthesis. Previous zero-shot speech synthesis systems based on language models and diffusion models were slow and required a lot of computing power to run.
The key innovation in FlashSpeech is that it can generate speech much faster, using only about 5% of the time required by previous systems. It does this by using a new technique called "adversarial consistency training" that allows it to be trained from scratch without needing a pre-trained diffusion model.
FlashSpeech also has a new "prosody generator" module that makes the rhythm and flow of the generated speech sound more natural and lifelike. Overall, FlashSpeech can generate high-quality zero-shot speech that is 20 times faster than other systems, while maintaining similar performance in terms of voice quality and similarity to the original audio prompts.
Technical Explanation
FlashSpeech is built on the "latent consistency model" and applies a novel "adversarial consistency training" approach. This allows the system to be trained from scratch without needing a pre-trained diffusion model as a teacher, as required by previous methods like MEGA-TTS 2 and HumaneSpeech.
The system also includes a new "prosody generator" module that enhances the diversity of the generated speech's rhythm and flow, making it sound more natural, as seen in systems like NaturalSpeech 3.
Experimentally, FlashSpeech demonstrates superior performance, being able to generate high-quality zero-shot speech that is about 20 times faster than other systems, while maintaining comparable voice quality and similarity to the original audio prompts. The generation process can be achieved efficiently with just one or two sampling steps.
FlashSpeech also shows versatility by performing tasks like voice conversion, speech editing, and diverse speech sampling effectively and efficiently, building on capabilities seen in systems like CoVoMix.
Critical Analysis
The paper provides a thorough technical explanation of the FlashSpeech system and its key innovations. However, it does not deeply explore the limitations or potential drawbacks of the approach.
For example, the paper does not discuss the quality of the generated prosody compared to human speech, or how the system might handle diverse accents, emotions, or speaking styles. Additionally, the computational efficiency gains are significant, but the paper does not explore the trade-offs in terms of model size, training time, or other factors that might impact real-world deployment.
Further research could investigate the generalization capabilities of FlashSpeech, its robustness to noisy or varied inputs, and its performance on a wider range of zero-shot speech synthesis tasks. Comparisons to other state-of-the-art zero-shot speech systems beyond the ones mentioned would also help contextualize the significance of the results.
Conclusion
FlashSpeech represents a significant advancement in large-scale zero-shot speech synthesis by dramatically improving the computational efficiency of the generation process. Its novel training approach and prosody generation module enable high-quality speech output that is up to 20 times faster than previous systems.
This breakthrough has the potential to unlock new applications and use cases for zero-shot speech synthesis, such as real-time voice conversion, personalized text-to-speech, and efficient speech editing. As the field continues to evolve, the insights and techniques introduced in FlashSpeech could pave the way for even more efficient and versatile zero-shot speech synthesis systems in the future.
Related Papers

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
🗣️
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
0
0
Zero-shot text-to-speech (TTS) aims to synthesize voices with unseen speech prompts, which significantly reduces the data and computation requirements for voice cloning by skipping the fine-tuning process. However, the prompting mechanisms of zero-shot TTS still face challenges in the following aspects: 1) previous works of zero-shot TTS are typically trained with single-sentence prompts, which significantly restricts their performance when the data is relatively sufficient during the inference stage. 2) The prosodic information in prompts is highly coupled with timbre, making it untransferable to each other. This paper introduces Mega-TTS 2, a generic prompting mechanism for zero-shot TTS, to tackle the aforementioned challenges. Specifically, we design a powerful acoustic autoencoder that separately encodes the prosody and timbre information into the compressed latent space while providing high-quality reconstructions. Then, we propose a multi-reference timbre encoder and a prosody latent language model (P-LLM) to extract useful information from multi-sentence prompts. We further leverage the probabilities derived from multiple P-LLM outputs to produce transferable and controllable prosody. Experimental results demonstrate that Mega-TTS 2 could not only synthesize identity-preserving speech with a short prompt of an unseen speaker from arbitrary sources but consistently outperform the fine-tuning method when the volume of data ranges from 10 seconds to 5 minutes. Furthermore, our method enables to transfer various speaking styles to the target timbre in a fine-grained and controlled manner. Audio samples can be found in https://boostprompt.github.io/boostprompt/.
4/11/2024

Humane Speech Synthesis through Zero-Shot Emotion and Disfluency Generation
Rohan Chaudhury, Mihir Godbole, Aakash Garg, Jinsil Hwaryoung Seo
0
0
Contemporary conversational systems often present a significant limitation: their responses lack the emotional depth and disfluent characteristic of human interactions. This absence becomes particularly noticeable when users seek more personalized and empathetic interactions. Consequently, this makes them seem mechanical and less relatable to human users. Recognizing this gap, we embarked on a journey to humanize machine communication, to ensure AI systems not only comprehend but also resonate. To address this shortcoming, we have designed an innovative speech synthesis pipeline. Within this framework, a cutting-edge language model introduces both human-like emotion and disfluencies in a zero-shot setting. These intricacies are seamlessly integrated into the generated text by the language model during text generation, allowing the system to mirror human speech patterns better, promoting more intuitive and natural user interactions. These generated elements are then adeptly transformed into corresponding speech patterns and emotive sounds using a rule-based approach during the text-to-speech phase. Based on our experiments, our novel system produces synthesized speech that's almost indistinguishable from genuine human communication, making each interaction feel more personal and authentic.
4/3/2024
NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, Zhizheng Wu, Tao Qin, Xiang-Yang Li, Wei Ye, Shikun Zhang, Jiang Bian, Lei He, Jinyu Li, Sheng Zhao
0
0
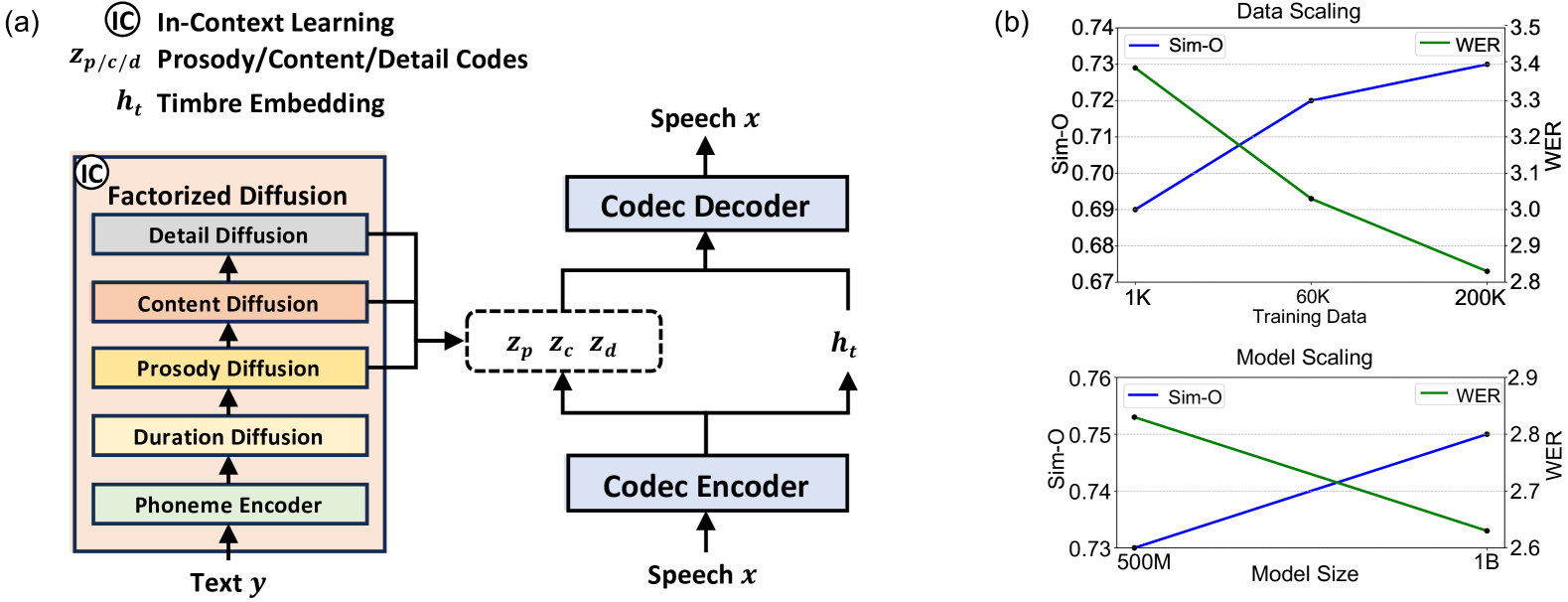
While recent large-scale text-to-speech (TTS) models have achieved significant progress, they still fall short in speech quality, similarity, and prosody. Considering speech intricately encompasses various attributes (e.g., content, prosody, timbre, and acoustic details) that pose significant challenges for generation, a natural idea is to factorize speech into individual subspaces representing different attributes and generate them individually. Motivated by it, we propose NaturalSpeech 3, a TTS system with novel factorized diffusion models to generate natural speech in a zero-shot way. Specifically, 1) we design a neural codec with factorized vector quantization (FVQ) to disentangle speech waveform into subspaces of content, prosody, timbre, and acoustic details; 2) we propose a factorized diffusion model to generate attributes in each subspace following its corresponding prompt. With this factorization design, NaturalSpeech 3 can effectively and efficiently model intricate speech with disentangled subspaces in a divide-and-conquer way. Experiments show that NaturalSpeech 3 outperforms the state-of-the-art TTS systems on quality, similarity, prosody, and intelligibility, and achieves on-par quality with human recordings. Furthermore, we achieve better performance by scaling to 1B parameters and 200K hours of training data.
4/24/2024