CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
2404.06690
0
0
Abstract
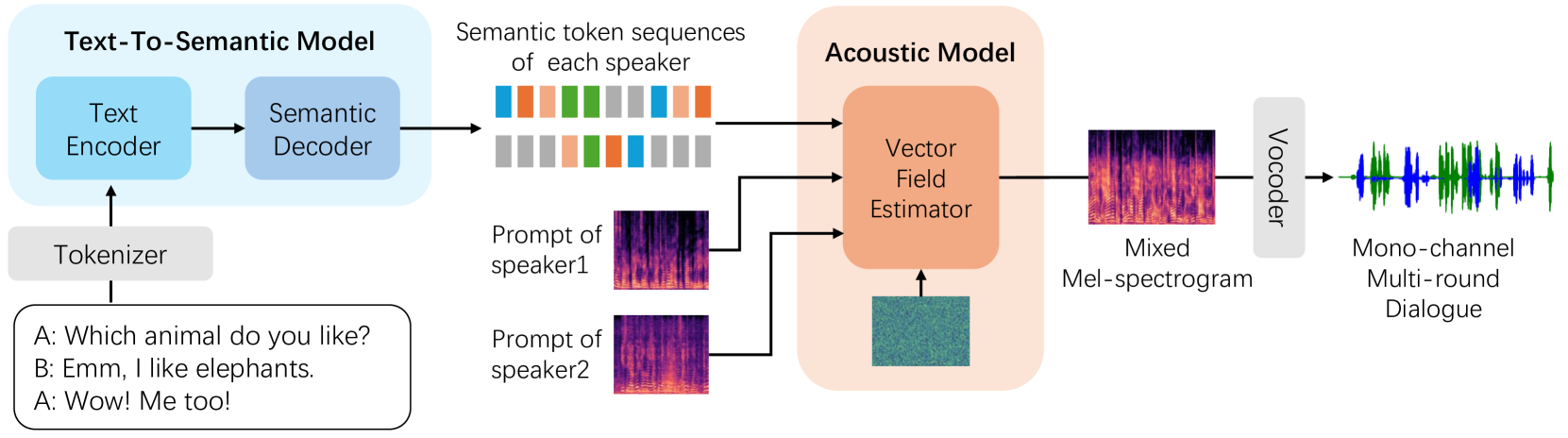
Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces CoVoMix, a zero-shot speech generation model that can create natural-sounding multi-talker conversations.
- The model is trained on a large dataset of single-speaker speech and can generate conversations between multiple speakers without any additional voice samples.
- The key innovations include an architecture that can blend multiple virtual voices, a training process that learns to modulate voice characteristics, and techniques to ensure the generated speech sounds realistic and coherent.
Plain English Explanation
CoVoMix is a new AI system that can create realistic-sounding conversations between multiple people, even if it has never heard those specific voices before. The system is trained on a large dataset of single-speaker recordings, and then it learns how to blend those voices together to generate natural-sounding multi-person dialogues.
This is an important advance because current text-to-speech technologies tend to sound robotic or unnatural when trying to generate conversations with back-and-forth between different speakers. CoVoMix solves this problem by having the AI learn how to smoothly transition between voices and match the pitch, tone, and pacing of a natural conversation.
The key innovations in CoVoMix include an architecture that can blend multiple virtual voices, a training process that teaches the model to modulate voice characteristics, and techniques to ensure the generated speech sounds realistic and coherent. This allows the system to create convincing multi-person dialogues from scratch, without needing any actual audio recordings of the specific speakers involved.
Technical Explanation
CoVoMix is a zero-shot speech generation model that can create natural-sounding multi-talker conversations. Unlike previous text-to-speech systems, CoVoMix does not require any audio samples of the target speakers. Instead, it is trained on a large dataset of single-speaker speech and learns to blend those voice characteristics to generate realistic multi-person dialogues.
The key innovations in the CoVoMix architecture include:
- A voice blending module that can seamlessly combine multiple virtual voices
- A voice modulation training process that teaches the model to adjust factors like pitch, tone, and pacing to match a natural conversation
- Techniques to ensure the generated speech sounds coherent and avoids artifacts or discontinuities
These advancements allow CoVoMix to generate multi-talker conversations that sound human-like, without any need for additional voice samples beyond the initial training data. This represents a significant step forward for zero-shot text-to-speech capabilities.
Critical Analysis
The CoVoMix paper makes a strong case for the technical advances it represents in zero-shot multi-talker speech synthesis. The authors provide thorough evaluations demonstrating the system's ability to generate natural-sounding conversations, both in terms of voice quality and coherence.
However, the paper does not address some potential limitations or areas for further research. For example, it's unclear how well CoVoMix would scale to supporting a larger number of distinct speaker voices, or how it might handle more complex conversational dynamics like interruptions or overlapping speech.
Additionally, there could be concerns around the ethical implications of such powerful speech synthesis capabilities, particularly if they were used to generate fake or misleading audio. The paper does not delve into these types of societal considerations.
Overall, the technical achievements of CoVoMix are impressive, but further research will be needed to fully understand the system's capabilities, limitations, and potential real-world impacts.
Conclusion
CoVoMix represents a significant advance in zero-shot speech generation, enabling the creation of natural-sounding multi-talker conversations without any need for voice samples of the target speakers.
The key innovations in the CoVoMix architecture, including voice blending, voice modulation, and techniques for coherent speech generation, allow it to produce human-like dialogues from scratch. This could have important implications for a wide range of applications, from virtual assistants to audiobook generation to film/TV production.
While the paper demonstrates the technical prowess of the CoVoMix system, further research will be needed to fully explore its capabilities, limitations, and potential societal impacts. Nonetheless, this work represents an important step forward in the field of zero-shot text-to-speech and the advancement of more natural, human-like speech synthesis.
Related Papers
VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild
Puyuan Peng, Po-Yao Huang, Abdelrahman Mohamed, David Harwath
0
0
We introduce VoiceCraft, a token infilling neural codec language model, that achieves state-of-the-art performance on both speech editing and zero-shot text-to-speech (TTS) on audiobooks, internet videos, and podcasts. VoiceCraft employs a Transformer decoder architecture and introduces a token rearrangement procedure that combines causal masking and delayed stacking to enable generation within an existing sequence. On speech editing tasks, VoiceCraft produces edited speech that is nearly indistinguishable from unedited recordings in terms of naturalness, as evaluated by humans; for zero-shot TTS, our model outperforms prior SotA models including VALLE and the popular commercial model XTTS-v2. Crucially, the models are evaluated on challenging and realistic datasets, that consist of diverse accents, speaking styles, recording conditions, and background noise and music, and our model performs consistently well compared to other models and real recordings. In particular, for speech editing evaluation, we introduce a high quality, challenging, and realistic dataset named RealEdit. We encourage readers to listen to the demos at https://jasonppy.github.io/VoiceCraft_web.
4/23/2024

Humane Speech Synthesis through Zero-Shot Emotion and Disfluency Generation
Rohan Chaudhury, Mihir Godbole, Aakash Garg, Jinsil Hwaryoung Seo
0
0
Contemporary conversational systems often present a significant limitation: their responses lack the emotional depth and disfluent characteristic of human interactions. This absence becomes particularly noticeable when users seek more personalized and empathetic interactions. Consequently, this makes them seem mechanical and less relatable to human users. Recognizing this gap, we embarked on a journey to humanize machine communication, to ensure AI systems not only comprehend but also resonate. To address this shortcoming, we have designed an innovative speech synthesis pipeline. Within this framework, a cutting-edge language model introduces both human-like emotion and disfluencies in a zero-shot setting. These intricacies are seamlessly integrated into the generated text by the language model during text generation, allowing the system to mirror human speech patterns better, promoting more intuitive and natural user interactions. These generated elements are then adeptly transformed into corresponding speech patterns and emotive sounds using a rule-based approach during the text-to-speech phase. Based on our experiments, our novel system produces synthesized speech that's almost indistinguishable from genuine human communication, making each interaction feel more personal and authentic.
4/3/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
🗣️
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Weizhen Bian, Shulin He, Qifeng Liu, Yike Guo, Wei Xue
0
0
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
4/26/2024