Hybrid Structure-from-Motion and Camera Relocalization for Enhanced Egocentric Localization

0
Sign in to get full access
Overview
- This paper presents a hybrid approach that combines Structure-from-Motion (SfM) and camera relocalization to enhance egocentric localization.
- SfM is used to reconstruct the 3D structure of the environment, while camera relocalization helps improve the accuracy of the user's pose estimation.
- The proposed method aims to provide more robust and reliable localization for egocentric vision applications, such as augmented reality and mobile robotics.
Plain English Explanation
The paper describes a technique that combines two different methods to help a camera or device know where it is located in a 3D space. The first method, called Structure-from-Motion (SfM), is used to build a 3D map of the environment by analyzing the images captured by the camera as it moves around. The second method, called camera relocalization, helps the camera figure out its exact position and orientation within that 3D map.
By using both of these techniques together, the researchers were able to create a more accurate and robust way for the camera to determine its location, which could be useful for applications like augmented reality or mobile robotics. The SfM part builds a 3D model of the surroundings, while the relocalization part helps the camera figure out exactly where it is within that model, even if it gets a bit lost or confused.
Technical Explanation
The paper proposes a hybrid approach that combines Structure-from-Motion (SfM) and camera relocalization to enhance egocentric localization. SfM is used to reconstruct the 3D structure of the environment by analyzing the images captured by the moving camera. The 3D model obtained through SfM is then used as a reference for camera relocalization, which helps improve the accuracy of the user's pose estimation.
The key elements of the proposed approach are:
- SfM-based 3D reconstruction: The method uses SfM techniques to build a 3D model of the environment from the images captured by the moving camera.
- Camera relocalization: The camera's position and orientation within the 3D model are estimated using relocalization algorithms, which helps refine the user's pose estimation.
- Hybrid integration: The SfM-based 3D model and the camera relocalization outputs are combined to provide a more robust and accurate egocentric localization solution.
The authors evaluate their approach on several datasets and demonstrate its effectiveness in improving localization accuracy compared to using SfM or relocalization alone.
Critical Analysis
The paper presents a promising approach to enhancing egocentric localization by leveraging the strengths of both SfM and camera relocalization. However, the authors do not discuss any potential limitations or caveats of their method.
One area that could be explored further is the robustness of the approach in challenging environments, such as those with dynamic elements or significant occlusions. The paper also does not address how the method would scale to large-scale environments or how it might be affected by sensor noise or other real-world factors.
Additionally, the authors could have compared their hybrid approach to more state-of-the-art SfM and relocalization techniques to better contextualize the performance and novelty of their work.
Conclusion
This paper presents a hybrid approach that combines Structure-from-Motion and camera relocalization to enhance egocentric localization. By integrating these two complementary techniques, the researchers were able to create a more robust and accurate way for a camera or device to determine its location within a 3D space.
The proposed method could have significant implications for applications that rely on precise spatial awareness, such as augmented reality and mobile robotics. While the paper does not address certain limitations, the overall approach represents a promising step forward in improving egocentric localization capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hybrid Structure-from-Motion and Camera Relocalization for Enhanced Egocentric Localization
Jinjie Mai, Abdullah Hamdi, Silvio Giancola, Chen Zhao, Bernard Ghanem
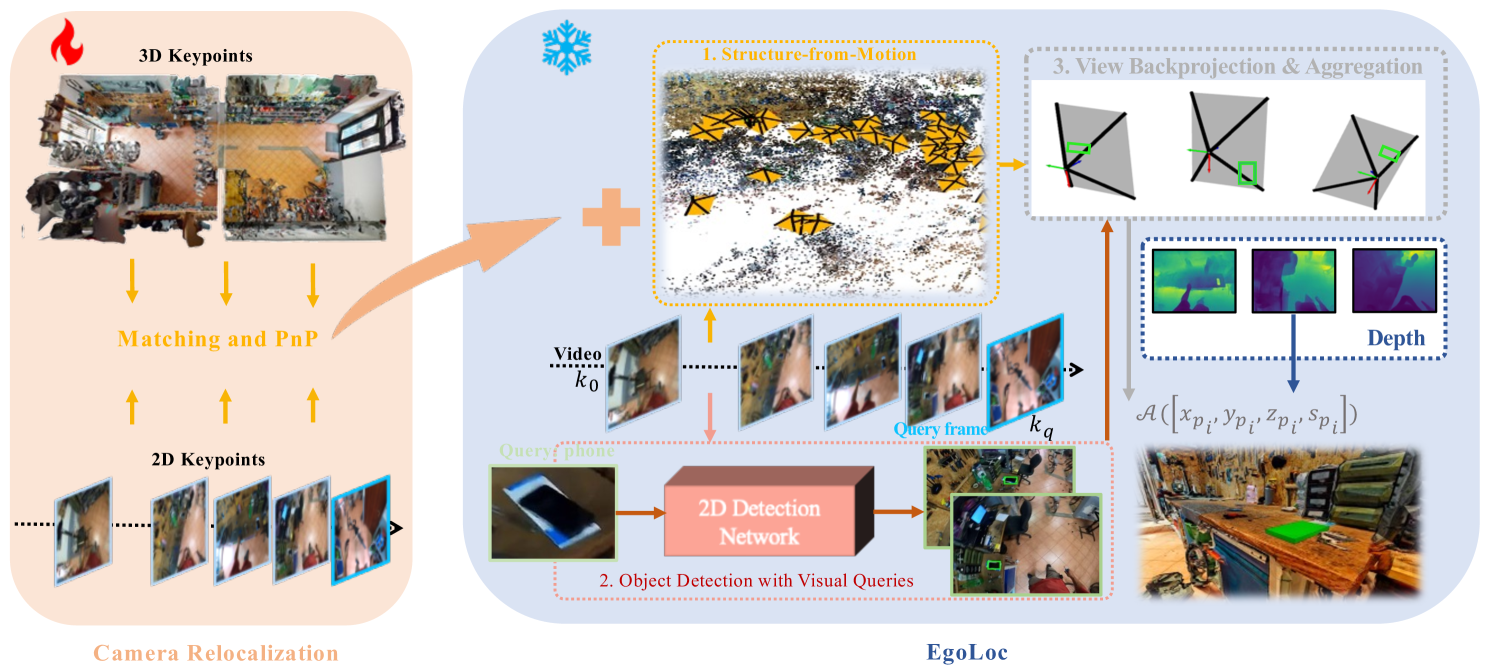
We built our pipeline EgoLoc-v1, mainly inspired by EgoLoc. We propose a model ensemble strategy to improve the camera pose estimation part of the VQ3D task, which has been proven to be essential in previous work. The core idea is not only to do SfM for egocentric videos but also to do 2D-3D matching between existing 3D scans and 2D video frames. In this way, we have a hybrid SfM and camera relocalization pipeline, which can provide us with more camera poses, leading to higher QwP and overall success rate. Our method achieves the best performance regarding the most important metric, the overall success rate. We surpass previous state-of-the-art, the competitive EgoLoc, by $1.5%$. The code is available at url{https://github.com/Wayne-Mai/egoloc_v1}.
Read more7/12/2024
🏷️
0
3D Human Pose Perception from Egocentric Stereo Videos
Hiroyasu Akada, Jian Wang, Vladislav Golyanik, Christian Theobalt
While head-mounted devices are becoming more compact, they provide egocentric views with significant self-occlusions of the device user. Hence, existing methods often fail to accurately estimate complex 3D poses from egocentric views. In this work, we propose a new transformer-based framework to improve egocentric stereo 3D human pose estimation, which leverages the scene information and temporal context of egocentric stereo videos. Specifically, we utilize 1) depth features from our 3D scene reconstruction module with uniformly sampled windows of egocentric stereo frames, and 2) human joint queries enhanced by temporal features of the video inputs. Our method is able to accurately estimate human poses even in challenging scenarios, such as crouching and sitting. Furthermore, we introduce two new benchmark datasets, i.e., UnrealEgo2 and UnrealEgo-RW (RealWorld). The proposed datasets offer a much larger number of egocentric stereo views with a wider variety of human motions than the existing datasets, allowing comprehensive evaluation of existing and upcoming methods. Our extensive experiments show that the proposed approach significantly outperforms previous methods. We will release UnrealEgo2, UnrealEgo-RW, and trained models on our project page.
Read more5/16/2024
🖼️
0
Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cavallari, 'Aron Monszpart, Daniyar Turmukhambetov, Victor Adrian Prisacariu
We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. In many cases, our method, ACE0, estimates camera poses with an accuracy close to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
Read more7/29/2024
0
EgoPoseFormer: A Simple Baseline for Stereo Egocentric 3D Human Pose Estimation
Chenhongyi Yang, Anastasia Tkach, Shreyas Hampali, Linguang Zhang, Elliot J. Crowley, Cem Keskin
We present EgoPoseFormer, a simple yet effective transformer-based model for stereo egocentric human pose estimation. The main challenge in egocentric pose estimation is overcoming joint invisibility, which is caused by self-occlusion or a limited field of view (FOV) of head-mounted cameras. Our approach overcomes this challenge by incorporating a two-stage pose estimation paradigm: in the first stage, our model leverages the global information to estimate each joint's coarse location, then in the second stage, it employs a DETR style transformer to refine the coarse locations by exploiting fine-grained stereo visual features. In addition, we present a Deformable Stereo Attention operation to enable our transformer to effectively process multi-view features, which enables it to accurately localize each joint in the 3D world. We evaluate our method on the stereo UnrealEgo dataset and show it significantly outperforms previous approaches while being computationally efficient: it improves MPJPE by 27.4mm (45% improvement) with only 7.9% model parameters and 13.1% FLOPs compared to the state-of-the-art. Surprisingly, with proper training settings, we find that even our first-stage pose proposal network can achieve superior performance compared to previous arts. We also show that our method can be seamlessly extended to monocular settings, which achieves state-of-the-art performance on the SceneEgo dataset, improving MPJPE by 25.5mm (21% improvement) compared to the best existing method with only 60.7% model parameters and 36.4% FLOPs. Code is available at: https://github.com/ChenhongyiYang/egoposeformer .
Read more8/16/2024