Scene Coordinate Reconstruction: Posing of Image Collections via Incremental Learning of a Relocalizer
2404.14351
0
0
🖼️
Abstract
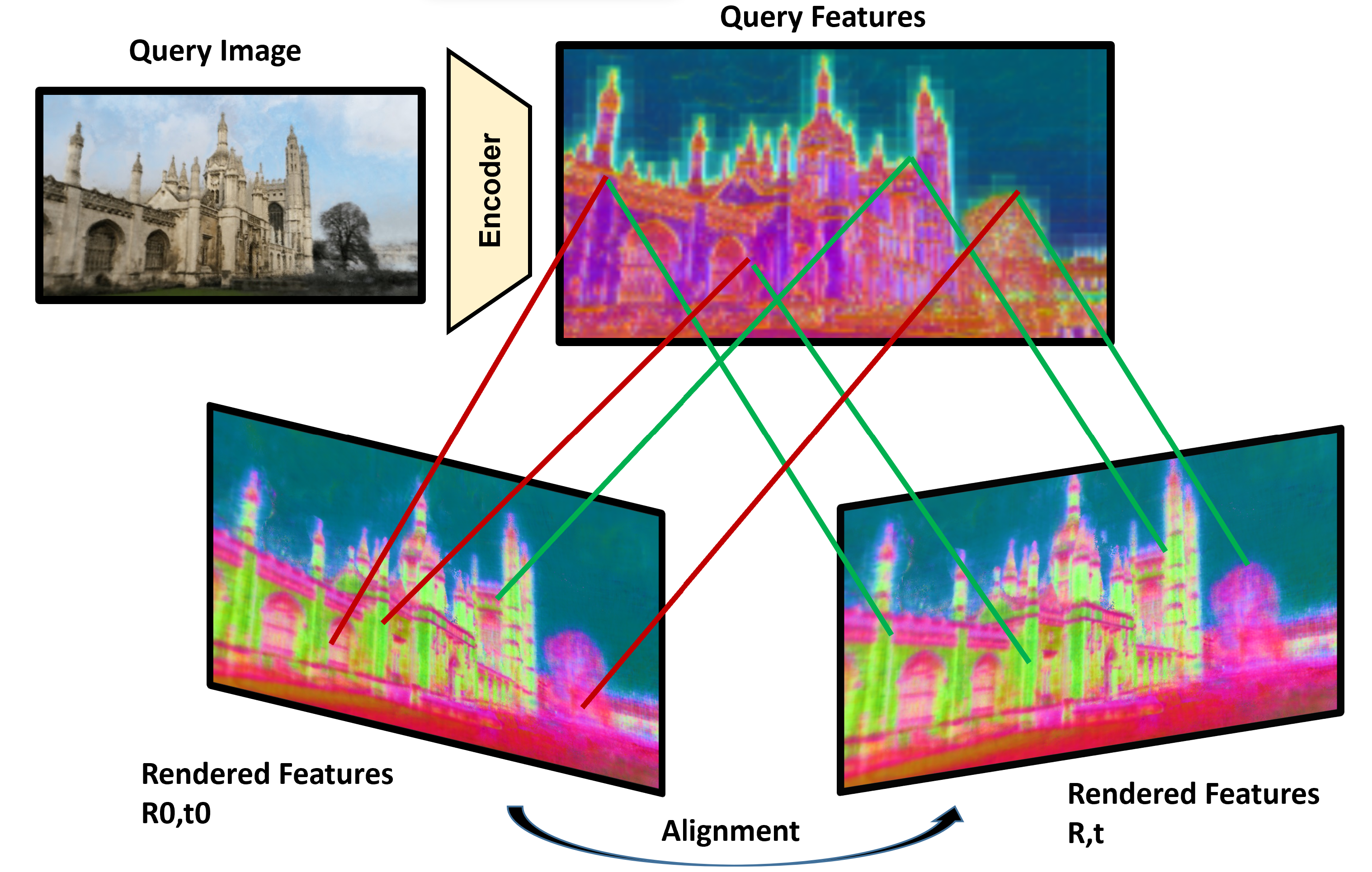
We address the task of estimating camera parameters from a set of images depicting a scene. Popular feature-based structure-from-motion (SfM) tools solve this task by incremental reconstruction: they repeat triangulation of sparse 3D points and registration of more camera views to the sparse point cloud. We re-interpret incremental structure-from-motion as an iterated application and refinement of a visual relocalizer, that is, of a method that registers new views to the current state of the reconstruction. This perspective allows us to investigate alternative visual relocalizers that are not rooted in local feature matching. We show that scene coordinate regression, a learning-based relocalization approach, allows us to build implicit, neural scene representations from unposed images. Different from other learning-based reconstruction methods, we do not require pose priors nor sequential inputs, and we optimize efficiently over thousands of images. Our method, ACE0 (ACE Zero), estimates camera poses to an accuracy comparable to feature-based SfM, as demonstrated by novel view synthesis. Project page: https://nianticlabs.github.io/acezero/
Create account to get full access
Overview
- The paper addresses the task of estimating camera parameters from a set of images depicting a scene.
- It re-interprets the popular feature-based structure-from-motion (SfM) approach as an iterated application and refinement of a visual relocalizer.
- The paper explores alternative visual relocalizers beyond local feature matching, focusing on scene coordinate regression, a learning-based relocalization approach.
- The proposed method, ACE0 (ACE Zero), can estimate camera poses without requiring pose priors or sequential inputs, and can optimize efficiently over thousands of images.
Plain English Explanation
The paper deals with the problem of figuring out the camera settings (e.g., position, orientation) used to capture a set of images of a scene. Traditional methods, known as structure-from-motion (SfM), work by gradually building up a 3D model of the scene and using that to determine the camera settings.
The authors take a different approach, viewing this process as repeatedly refining a method that can take a new image and figure out where the camera was when that image was taken. This allows them to explore new ways of doing this "relocalization" that don't rely on the traditional approach of matching local features in the images.
Their proposed method, called ACE0, uses a machine learning technique called "scene coordinate regression" to build an implicit, neural representation of the scene from the unposed images. Unlike some other learning-based reconstruction methods, ACE0 doesn't require any information about the camera poses ahead of time, and can efficiently optimize over large datasets of thousands of images.
The key advantage of ACE0 is that it can estimate camera poses with accuracy comparable to traditional SfM, as demonstrated by its ability to generate high-quality novel views of the scene. This suggests it could be a powerful alternative to feature-based SfM in applications like visual localization and augmented reality.
Technical Explanation
The paper re-interprets the incremental structure-from-motion (SfM) pipeline as an iterative process of visual relocalizer refinement. Rather than the traditional approach of triangulating sparse 3D points and incrementally registering new camera views, the authors view this as repeatedly improving a method that can take a new image and determine the camera parameters used to capture it.
This perspective allows them to explore alternative visual relocalizers beyond local feature matching, such as the scene coordinate regression approach used in their proposed ACE0 method. ACE0 builds an implicit, neural representation of the scene from unposed images, without requiring pose priors or sequential inputs.
The key innovation is that ACE0 can efficiently optimize this representation over large-scale datasets of thousands of images, in contrast to other learning-based reconstruction methods. The authors demonstrate that ACE0 can achieve camera pose estimation accuracy comparable to feature-based SfM, as evidenced by its ability to synthesize high-quality novel views of the scene.
Critical Analysis
The paper presents a promising alternative to traditional feature-based SfM, with the potential to enable more flexible and scalable 3D reconstruction from unstructured image collections. However, the authors do acknowledge some limitations of the ACE0 approach.
For example, the method relies on the availability of a large, diverse dataset of images to learn the scene representation. Its performance may degrade in scenarios with limited training data or significant changes in scene appearance. Additionally, the neural scene representation used by ACE0 may not be as interpretable or editable as the sparse 3D point clouds produced by SfM.
Further research could explore ways to incorporate additional constraints or priors to improve the robustness and generalizability of the neural relocalizer, or to enable interactive editing and refinement of the reconstructed scenes. Comparisons to other learning-based visual localization and reconstruction methods would also help to better situate the strengths and weaknesses of the ACE0 approach.
Conclusion
In summary, the paper presents a novel perspective on structure-from-motion, re-interpreting it as an iterative process of visual relocalizer refinement. This allows the authors to explore alternative approaches beyond traditional feature matching, such as their proposed ACE0 method, which uses scene coordinate regression to build implicit neural representations of scenes from unposed images.
The key advantage of ACE0 is its ability to efficiently optimize these representations over large-scale datasets, enabling camera pose estimation accuracy comparable to feature-based SfM. This suggests that learning-based visual relocalizers could be a powerful alternative to traditional SfM, with potential applications in areas like visual localization and augmented reality. Further research is needed to address the method's limitations and explore its broader implications for 3D reconstruction and scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Incremental Joint Learning of Depth, Pose and Implicit Scene Representation on Monocular Camera in Large-scale Scenes
Tianchen Deng, Nailin Wang, Chongdi Wang, Shenghai Yuan, Jingchuan Wang, Danwei Wang, Weidong Chen
0
0
Dense scene reconstruction for photo-realistic view synthesis has various applications, such as VR/AR, autonomous vehicles. However, most existing methods have difficulties in large-scale scenes due to three core challenges: textit{(a) inaccurate depth input.} Accurate depth input is impossible to get in real-world large-scale scenes. textit{(b) inaccurate pose estimation.} Most existing approaches rely on accurate pre-estimated camera poses. textit{(c) insufficient scene representation capability.} A single global radiance field lacks the capacity to effectively scale to large-scale scenes. To this end, we propose an incremental joint learning framework, which can achieve accurate depth, pose estimation, and large-scale scene reconstruction. A vision transformer-based network is adopted as the backbone to enhance performance in scale information estimation. For pose estimation, a feature-metric bundle adjustment (FBA) method is designed for accurate and robust camera tracking in large-scale scenes. In terms of implicit scene representation, we propose an incremental scene representation method to construct the entire large-scale scene as multiple local radiance fields to enhance the scalability of 3D scene representation. Extended experiments have been conducted to demonstrate the effectiveness and accuracy of our method in depth estimation, pose estimation, and large-scale scene reconstruction.
4/10/2024

MCGMapper: Light-Weight Incremental Structure from Motion and Visual Localization With Planar Markers and Camera Groups
Yusen Xie, Zhenmin Huang, Kai Chen, Lei Zhu, Jun Ma
0
0
Structure from Motion (SfM) and visual localization in indoor texture-less scenes and industrial scenarios present prevalent yet challenging research topics. Existing SfM methods designed for natural scenes typically yield low accuracy or map-building failures due to insufficient robust feature extraction in such settings. Visual markers, with their artificially designed features, can effectively address these issues. Nonetheless, existing marker-assisted SfM methods encounter problems like slow running speed and difficulties in convergence; and also, they are governed by the strong assumption of unique marker size. In this paper, we propose a novel SfM framework that utilizes planar markers and multiple cameras with known extrinsics to capture the surrounding environment and reconstruct the marker map. In our algorithm, the initial poses of markers and cameras are calculated with Perspective-n-Points (PnP) in the front-end, while bundle adjustment methods customized for markers and camera groups are designed in the back-end to optimize the 6-DOF pose directly. Our algorithm facilitates the reconstruction of large scenes with different marker sizes, and its accuracy and speed of map building are shown to surpass existing methods. Our approach is suitable for a wide range of scenarios, including laboratories, basements, warehouses, and other industrial settings. Furthermore, we incorporate representative scenarios into simulations and also supply our datasets with pose labels to address the scarcity of quantitative ground-truth datasets in this research field. The datasets and source code are available on GitHub.
5/28/2024
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Maxime Pietrantoni, Gabriela Csurka, Martin Humenberger, Torsten Sattler
0
0
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
6/13/2024
↗️
Fusing Structure from Motion and Simulation-Augmented Pose Regression from Optical Flow for Challenging Indoor Environments
Felix Ott, Lucas Heublein, David Rugamer, Bernd Bischl, Christopher Mutschler
0
0
The localization of objects is a crucial task in various applications such as robotics, virtual and augmented reality, and the transportation of goods in warehouses. Recent advances in deep learning have enabled the localization using monocular visual cameras. While structure from motion (SfM) predicts the absolute pose from a point cloud, absolute pose regression (APR) methods learn a semantic understanding of the environment through neural networks. However, both fields face challenges caused by the environment such as motion blur, lighting changes, repetitive patterns, and feature-less structures. This study aims to address these challenges by incorporating additional information and regularizing the absolute pose using relative pose regression (RPR) methods. RPR methods suffer under different challenges, i.e., motion blur. The optical flow between consecutive images is computed using the Lucas-Kanade algorithm, and the relative pose is predicted using an auxiliary small recurrent convolutional network. The fusion of absolute and relative poses is a complex task due to the mismatch between the global and local coordinate systems. State-of-the-art methods fusing absolute and relative poses use pose graph optimization (PGO) to regularize the absolute pose predictions using relative poses. In this work, we propose recurrent fusion networks to optimally align absolute and relative pose predictions to improve the absolute pose prediction. We evaluate eight different recurrent units and construct a simulation environment to pre-train the APR and RPR networks for better generalized training. Additionally, we record a large database of different scenarios in a challenging large-scale indoor environment that mimics a warehouse with transportation robots. We conduct hyperparameter searches and experiments to show the effectiveness of our recurrent fusion method compared to PGO.
6/11/2024